В рамках конференции AI Dev 25 Апурва Джоши (Apoorva Joshi), специалист по связям с разработчиками в MongoDB, представила глубокий анализ одной из самых критических проблем современной разработки ИИ — управления памятью агентов. В то время как большинство современных LLM-приложений ограничиваются хранением истории чата, переход к полноценным ИИ-агентам требует системного подхода к долгосрочной памяти. Джоши утверждает, что именно умение эффективно сохранять, извлекать и обновлять знания превратит ИИ из простого чат-бота в интеллектуального партнера, способного учиться на собственном опыте.
🤖 От классических агентов к эре LLM 2:16
Апурва Джоши напоминает, что концепция ИИ-агентов зародилась задолго до появления современных языковых моделей. В 90-е годы доминировали агенты с обучением с подкреплением (Reinforcement Learning), которые выбирали действия из заранее определенного набора для максимизации вознаграждения . Именно такие системы обыгрывали гроссмейстеров в шахматы и го.
Однако сегодня под «ИИ-агентами» подразумеваются системы на базе LLM. По мнению спикера, современный агент состоит из пяти ключевых компонентов:
- Восприятие (Perception): способность наблюдать и интерпретировать окружающую среду (ввод пользователя, сигналы из Slack или почты) .
- Действие (Action): взаимодействие с миром через инструменты (API погоды, поиск, базы данных) .
- Память (Memory): хранение информации о прошлых действиях, состояниях и знаниях.
- Обратная связь (Feedback): сигналы от инструментов, пользователя или среды, направляющие поведение агента .
- Рассуждение (Reasoning): способность LLM как «мозга» планировать шаги для решения задачи .
🧠 Человеческая память как архитектурный шаблон 7:43
Чтобы построить по-настоящему умных агентов, Джоши предлагает обратиться к когнитивной психологии. Она выделяет несколько типов человеческой памяти, которые необходимо переложить на рельсы программного обеспечения:
- Краткосрочная и рабочая память: в ИИ-агентах это контекстное окно модели . Здесь хранятся промежуточные вычисления, текущие инструкции и результаты выполнения инструментов.
- Семантическая память: долгосрочное хранение фактов. Для агента это как знания, «зашитые» в веса LLM, так и внешние базы данных (например, документация продукта) .
- Эпизодическая память: воспоминания о конкретных событиях. В программной реализации это последовательности действий, которые агент предпринимал для решения задач в прошлом .
- Процедурная память: знание о том, «как» что-то делать. Это заложено в коде агента, системных промптах и весах модели .
- Сенсорная память: восприятие звуков, запахов и вкусов. Джоши считает, что ИИ-агенты пока далеки от полноценной обработки таких стимулов, поэтому в текущих архитектурах этот тип памяти можно опустить .
🛠️ CRUD для памяти: жизненный цикл данных 13:45
Управление памятью ИИ-агента Апурва Джоши описывает через классическую парадигму CRUD (Create, Read, Update, Delete).
Создание памяти (Create)
Просто хранить логи всех взаимодействий неэффективно. Спикер выделяет четыре «ингредиента» для формирования качественных воспоминаний:
- Трассировки рассуждений и планирования LLM .
- Результаты выполнения инструментов (tool calls).
- Диалоги с конечным пользователем.
- Обратная связь от среды исполнения.
Важно извлекать конкретные инсайты. Например, если агент управляет персонажем в симуляции, он должен сохранять черты характера героя или значимые события, а не весь текст логов .
Извлечение (Read) 20:01
Джоши выделяет несколько стратегий поиска нужных воспоминаний:
- Точное совпадение (Exact Match): поиск по конкретным критериям, например, по имени персонажа .
- Векторный поиск (Vector Search): извлечение информации по смыслу и намерению с использованием эмбеддингов .
- Гибридный поиск: сочетание ключевых слов и векторного поиска для повышения точности .
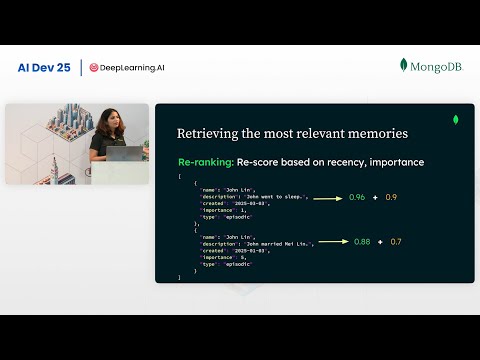
- Переранжирование (Reranking): корректировка результатов поиска с учетом свежести (Recency) или важности (Importance) воспоминания . Джоши приводит пример: воспоминание о том, что персонаж женился, должно иметь больший вес, чем то, что он просто пошел спать .
Обновление (Update) 24:41
Память должна быть динамичной. Если пользователь дает новую инструкцию (например, «всегда добавляй строки документации к функциям»), агент должен обновить свой системный промпт или семантическую память в базе данных, чтобы использовать это правило в будущем .
Удаление (Delete) 26:01
Хранить абсолютно всё — дорого и вредно для производительности. Джоши рекомендует внедрять политики жизненного цикла данных:
- Мониторинг паттернов использования.
- Перенос неиспользуемых воспоминаний в дешевые архивные хранилища .
- Удаление старых данных по истечении срока хранения для уменьшения пространства поиска и задержек (latency) .
📉 Практические компромиссы и риски 17:43
Внедрение сложной системы памяти неизбежно ведет к увеличению задержек. Каждое создание или обновление памяти — это дополнительный вызов LLM. Разработчикам приходится выбирать между адаптивностью агента и скоростью его ответа .
В ходе сессии вопросов и ответов Апурва Джоши затронула проблему галлюцинаций. По её мнению, если процесс согласования (reconciliation) старой и новой информации в памяти настроен некорректно, агент может начать «выдумывать» факты, основываясь на неверно интерпретированном контексте . Также она провела грань между логами и памятью: логи нужны для отладки и анализа всего массива данных, в то время как память агента должна быть лаконичной и содержать только ту информацию, которая необходима для принятия решений .
🚀 Будущее систем памяти 27:38
Апурва Джоши убеждена, что управление долгосрочной памятью является ключевым компонентом на пути к сильному ИИ (AGI). В будущем, по её прогнозу, процессы обучения на опыте могут стать частью процесса «быстрой дообучаемости» (flash tuning) самих весов моделей, но на текущем этапе внешние системы управления памятью (на базе баз данных, таких как MongoDB) остаются наиболее практичным и масштабируемым решением .




