Специалисты из Facebook AI Research совместно с учеными из INRIA и Университета Сорбонны представили архитектуру XCiT (Cross-Covariance Image Transformers), предлагающую инвертированный механизм работы внимания. Популярный ИТ-исследователь Янник Кильхер подробно разобрал данную научную работу, проанализировав её математическую основу и объяснив, почему новинка во многом ближе к свёрточным сетям, чем к классическим трансформерам. Предложенное решение заменяет квадратичную вычислительную сложность по длине последовательности на линейную, открывая возможности для прямой обработки изображений высокого разрешения.
🔄 Смена парадигмы: от токенов к каналам 0:01
В традиционных трансформерах механизм самовнимания (Self-Attention) заставляет каждый токен взаимодействовать со всеми остальными токенами последовательности. По словам Янника Кильхера, авторы статьи предложили своего рода «транспонирование» этого процесса. Вместо того чтобы вычислять внимание между токенами, архитектура XCiT переносит эту операцию на уровень признаков или каналов (channels).
Такой подход кардинально меняет вычислительные свойства модели. В классических трансформерах (включая Vision Transformers, работающие с патчами изображений) сложность растет квадратично относительно длины входной последовательности, что делает обработку больших объемов данных крайне ресурсоемкой. Перенос вычислений на взаимодействие каналов устраняет эту квадратичную зависимость. Модель XCiT демонстрирует линейную сложность относительно количества токенов, сохраняя при этом высокое качество работы на бенчмарках уровня ImageNet, а также в задачах плотного прогнозирования (например, сегментации изображений).
🤔 Трансформер или продвинутая свёрточная сеть? 1:18
Янник Кильхер высказывает определенный скепсис относительно терминологии, используемой авторами работы. Прочитав статью, ведущий пришел к выводу, что архитектуру XCiT едва ли можно назвать трансформером в привычном понимании. По его мнению, перед нами скорее глубоко модернизированная свёрточная сеть (ConvNet), в которой одна из свёрток сделана динамической.
Классическое глобальное самовнимание ценно тем, что позволяет модели гибко выходить за рамки локальных взаимодействий, свойственных обычным свёрткам. Однако за эту гибкость приходится платить огромным объемом памяти и времени вычислений при работе с изображениями высокого разрешения. Авторы XCiT заявляют, что их «перевёрнутое» внимание на основе матрицы кросс-ковариации между ключами (keys) и запросами (queries) успешно решает эту проблему. Новая архитектура, получившая название Cross-Covariance Image Transformer, призвана объединить точность классических трансформеров со масштабируемостью свёрточных решений.
📐 Анатомия вычислений: сравнение механизмов внимания 3:51
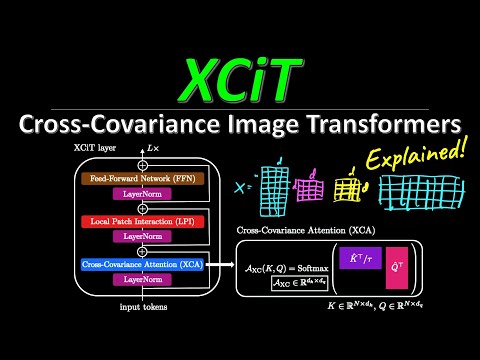
Чтобы наглядно объяснить разницу, Янник Кильхер обращается к базовым схемам построения слоев. Традиционный блок трансформера состоит из слоя самовнимания и последующей сети прямого распространения (Feed-Forward Network, FFN). В XCiT блок устроен иначе: стандартное самовнимание заменено комбинацией из двух элементов, ключевым из которых является кросс-ковариационное внимание (Cross-Covariance Attention, XCA).
Ведущий иронично отмечает, что рисовал схему классического внимания уже «тысячу раз», но готов повторить её снова ради контекста. В стандартных Vision Transformers (ViT) изображение разбивается на фиксированные патчи (кусочки), каждый из которых становится отдельным токеном последовательности, поскольку обрабатывать каждый пиксель напрямую слишком дорого. Свёрточные сети, напротив, работают с исходным разрешением за счет локальности ядра свёртки.
В классическом трансформере каждый токен генерирует векторы запроса ($Q$), ключа ($K$) и значения ($V$). Запросы сравниваются со всеми ключами (через скалярное произведение), формируя динамическую матрицу связей размера $N \times N$, где $N$ — количество токенов. По сути, это динамическая полносвязная сеть, где сила соединений вычисляется «на лету».
В механизме XCA логика переворачивается:
- Входная матрица данных имеет размерность $N \times D$, где $N$ — количество токенов (например, 5 точек данных), а $D$ — размерность эмбеддинга или число каналов (например, 4 измерения).
- Вместо того чтобы рассматривать токены как элементы последовательности, за элементы последовательности принимаются сами каналы.
- Запросы и ключи генерируются для каждого канала, и их взаимодействие просчитывается вдоль всей длины токенов.
- Вместо вычисления скалярных произведений строк ($N \times N$) вычисляется внешнее произведение (outer product), формирующее матрицу размера $D \times D$.
Поскольку размерность признаков $D$ обычно значительно меньше числа токенов $N$ при высоком разрешении, итоговая матрица ковариации получается компактной и стабильной по размеру. Вся информация о пространственном расположении токенов агрегируется внутри этого процесса.
🧩 Архитектура блоков XCiT и аналогия с лицом 9:50
Для объяснения физического смысла происходящего Янник Кильхер приводит понятную аналогию. В классическом ViT один патч может содержать фрагмент глаза, а другой — фрагмент рта. Механизм самовнимания позволяет им напрямую «пообщаться» друг с другом, чтобы модель поняла: перед ней человеческое лицо.
В парадигме XCiT коммуникация устроена иначе:
- Первый канал (feature channel) может отвечать за распознавание структур, похожих на глаза, по всему изображению.
- Второй канал может специализироваться на поиске элементов рта в любых участках кадра.
- Взаимодействие происходит не между конкретными точками пространства, а между этими глобальными концептами (каналами), помогая определить их совместную встречаемость.
После вычисления кросс-ковариационной матрицы к ней применяется операция Softmax, и результат умножается на матрицу значений ($V$). Однако, как подчёркивает Кильхер, в XCA эта операция применяется слева, а не справа. В итоге каждый токен проходит через эту динамически собранную матрицу абсолютно независимо от других токенов.
«Это в чистом виде динамическая $1 \times 1$ свёртка, где ядро свёртки вычисляется на основе всей последовательности целиком, — объясняет Янник Кильхер. — Однако как только ядро сформировано, никакого обмена информацией между токенами внутри этого слоя не происходит».
Именно поэтому ведущий сомневается в корректности термина «трансформер» и в шутку предлагает запустить хэштег #LeaveTransformersAlone («Оставьте трансформеры в покое»). По его мнению, сейчас индустрия склонна называть трансформером любую архитектуру, где есть динамические веса.
Сам блок XCiT состоит из трех последовательных шагов:
- Слой XCA (Cross-Covariance Attention): динамическая $1 \times 1$ свёртка по каналам.
- Локальное взаимодействие патчей (Local Patch Interaction, LPI): полноценная глубинно-разделяемая (depth-wise separable) свёртка, которая скользит по пространству последовательности. Именно она отвечает за физическое смешивание информации между соседними токенами, но требует крайне мало вычислительных ресурсов.
- Сеть прямого распространения (FFN): классический слой, который выполняет статическую (фиксированную, а не динамическую) $1 \times 1$ свёртку для трансформации каналов внутри каждого токена по отдельности.
🛠️ Инженерные хитрости и суровая реальность сходимости 27:58
Как отмечает Янник Кильхер, за красивой математической формулировкой скрывается огромная инженерная работа, без которой архитектура попросту отказывается обучаться. При детальном разборе авторы упоминают несколько критически важных компонентов.
Обязательными условиями для стабильной работы модели являются:
- L2-нормализация векторов: авторы применяют жесткое l2-нормирование для ключей и запросов до вычисления ковариации. Графики абляции (ablation studies) показывают, что без этой нормализации процесс обучения полностью ломается и модель выдает нулевую точность.
- Масштабирование температуры: в слое ковариации используется обучаемый параметр температуры, стабилизирующий распределение после Softmax.
- Блочно-диагональное внимание (Block-diagonal XCA): каналы не взаимодействуют в режиме «все со всеми». Их разбивают на изолированные группы (аналогично механизму Group Normalization в свёрточных сетях), и внимание вычисляется только внутри этих блоков признаков.
Ведущий делает вывод, что данные приемы лишний раз доказывают: XCiT — это эволюционное развитие идей ConvNet, дополненное современными инженерными трюками ИИ-сообщества.
📊 Результаты тестов и финальная критика 30:48
В плане практических результатов XCiT демонстрирует отличные показатели. Модели масштабируются линейно в зависимости от разрешения изображения, а потребление памяти графического процессора (GPU) у них оказывается даже более эффективным, чем у классического ResNet-50. Архитектура показывает паритет по точности с передовыми Vision Transformers и отлично проявляет себя в связке с алгоритмами самообучения (например, DINO). Исследования авторов доказывают, что именно слой XCA является главным «рабочим движком» всей системы — его удаление приводит к катастрофическому падению метрик.
Тем не менее Янник Кильхер высказал и финальную критику в адрес исследователей из Facebook AI Research. В начале статьи авторы громко заявляют, что избавились от квадратичной сложности и ограничений на длину последовательности. Однако на практике в экспериментах они всё равно продолжают использовать разбиение на патчи (минимальный размер — $8 \times 8$ пикселей).
Янник задается логичным вопросом: если архитектура обладает честной линейной сложностью и способна переваривать огромные последовательности, почему бы не отказаться от патчей вовсе и не начать обрабатывать изображения в их полном, оригинальном попиксельном разрешении? Возможно, разработчики предпочли направить сэкономленные ресурсы графических процессоров на увеличение количества параметров в других слоях сети.




