В своём новом видеоразборе известный ИИ-исследователь Янник Кильхер (Yannic Kilcher) подробно анализирует научную работу «Planning to Explore via Self-Supervised World Models». Представленный авторами метод предлагает радикально изменить подход к обучению с подкреплением, внедрив концепцию автономного исследования среды без внешних наград с помощью латентных моделей мира. Это решение призвано избавить ИИ-агентов от узкой специализации и на порядки ускорить их адаптацию к широкому спектру прикладных задач.
🌍 Концепция обучения без наград: Новый взгляд на Reinforcement Learning 0:00
В классических системах обучения с подкреплением (Reinforcement Learning, RL) архитектура жестко завязана на пару «агент — среда». Агент совершает действия, среда меняет состояние и возвращает внешнюю награду, определяемую конкретной задачей. В качестве примера рассматривается симуляция Walker, где робот получает вознаграждение пропорционально пройденному вперед расстоянию и штрафуется за падения. Как отмечает Янник Кильхер, если обучать индивидуального RL-агента под каждую отдельную задачу, это потребует колоссального объема данных и вычислительных мощностей без возможности переиспользования опыта.
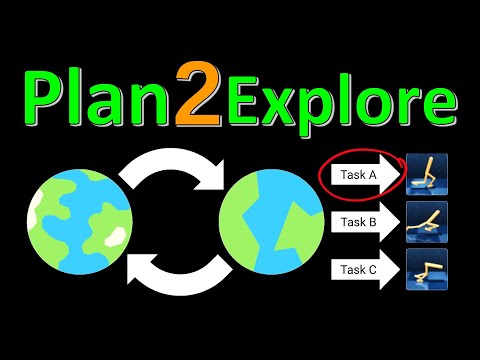
Вместо этого исследователи предлагают подход, аналогичный совместному предобучению (joint pre-training), которое давно стало стандартом в обработке естественного языка (NLP) и компьютерном зрении. Процесс разделяется на два этапа:
- Task-agnostic exploration (Автономное исследование): Агента бросают в среду, где полностью отсутствуют внешние награды. Он совершает произвольные действия, фиксируя отклики среды и формируя глобальную модель мира.
- Downstream tasks (Адаптация к задачам): В среду вводятся конкретные целевые задачи (бег вперед, бег назад, сальто). Скорость освоения этих задач напрямую зависит от качества знаний, накопленных на первом этапе.
🧠 Проблема «ретроспективной новизны» и модель внутренней мотивации 3:39
В условиях отсутствия внешних наград ключевым двигателем обучения становится внутренняя мотивация (intrinsic motivation). Базовую концепцию такого поиска можно сравнить с игрой Pac-Man, где все пространство условно заполнено невидимыми зелеными монетами. Когда агент посещает новое состояние, он «забирает» монету, и данная зона больше не приносит ему внутренней награды. Агент мотивирован искать исключительно неисследованные области.
Однако Янник Кильхер указывает на фундаментальный изъян стандартных алгоритмов без модели среды (model-free RL), который авторы статьи называют «ретроспективной новизной» (retrospective novelty):
«В рамках подходов model-free агент сначала совершает траекторию в среде, собирает данные в буфер и только затем рассчитывает показатель новизны. Получается, что новизна входа вычисляется уже после того, как агент его достиг. Нейросеть обучается стремиться в те зоны, которые были новыми на момент шага, но фактически перестали быть таковыми сразу после посещения».
В результате агент действует неэффективно, раз за разом возвращаясь в уже изученные локации. Чтобы преодолеть это ограничение, авторы Plan2Explore создали систему, способную оценивать будущую новизну состояний, в которых агент еще никогда не был.
🛠️ Архитектура Plan2Explore: Пошаговый алгоритм планирования 9:16
Главное технологическое новшество работы — это планирование в латентном (скрытом) пространстве на базе предобученной модели мира Dreamer. Модель Dreamer способна симулировать развитие событий будущего не в «физическом» пространстве пикселей, а внутри абстрактных векторов.
Технический процесс реализации алгоритма устроен следующим образом:
- Кодирование состояний: На каждом шаге агент принимает высокоразмерное наблюдение (например, кадр из симулятора) и пропускает его через сверточную нейросеть (CNN), получая компактный вектор признаков.
- Формирование истории: Вектор признаков объединяется с предыдущим скрытым состоянием через рекуррентную нейросеть (RNN), формируя текущее латентное состояние $H_t$.
- Воображаемые траектории: Используя текущее латентное состояние, модель Dreamer способна генерировать множество альтернативных сценариев будущего в латентном пространстве без реального взаимодействия со средой.
- Расчет латентного разногласия (Latent Disagreement): Для предсказания признаков следующего шага создается ансамбль из $K$ независимых предсказывающих моделей с разной начальной инициализацией параметров. Они принимают воображаемое латентное состояние и воображаемое действие, выдавая свои прогнозы будущих признаков.
- Генерация награды через дисперсию: Если модели ансамбля выдают схожие результаты, значит, этот переход полностью детерминирован и хорошо изучен системой, а математическая дисперсия (разброс) между ними близка к нулю. Если прогнозы сильно расходятся, это свидетельствует о высокой неопределенности. Именно эта величина дисперсии используется в качестве внутренней награды, заставляя политику агента целенаправленно искать зоны максимального разногласия.
📊 Теоретическое обоснование и скрытые допущения теории 16:29
Авторы исследования подкрепляют концепцию латентного разногласия строгой математической базой, увязывая её с максимизацией ожидаемого прироста информации (Information Gain). Взаимная информация декомпозируется на два ключевых элемента: общую неопределенность системы и внутреннюю стохастичность самой среды (хаотичные факторы, вроде ветра или шума сенсоров).
По словам Янника Кильхера, здесь кроется важное теоретическое допущение:
«Модель исходит из предположения, что уровень естественного шума во всех переходах среды примерно одинаков. Из этого делается вывод, что если мы можем предсказать состояние А лучше, чем состояние Б, то идти нужно в Б, поскольку именно там наша модель еще не дообучилась».
Ведущий подчеркивает, что в реальном мире это допущение не выдерживает критики, так как различные области пространства обладают принципиально разным уровнем хаотичности.
🧐 Критический разбор Янника Кильхера: Внутренние противоречия 22:01
Янник Кильхер высказывает аргументированный скептицизм относительно некоторых заявлений авторов статьи и внутренней логики архитектуры:
- Проблема глубины планирования: В тексте декларируется цель максимизации долгосрочной новизны, однако на практике в формулах максимизируется лишь неопределенность на первом шаге после выбора действия. По мнению ведущего, полноценное планирование обязано агрегировать суммарную неопределенность по всей цепочке будущих воображаемых шагов.
- Рекурсивный возврат к Model-Free методам: Жестко критикуя методы без модели за их ретроспективность, авторы для выбора оптимального действия внутри «воображения» интегрируют стандартный алгоритм Actor-Critic с функцией ценности (Value Function). Кильхер иронизирует, что это переносит проблему ретроспективности на один уровень абстракции глубже — агент обучается на ретроспективных данных из воображаемой модели мира.
- Ловушка «шумного телевизора»: Метод критически уязвим к качеству инициализации ансамбля. В сложных условиях реального мира агент рискует навсегда застрять перед любым источником случайного шума, так как модели ансамбля никогда не смогут прийти к согласию относительно хаотических данных.
📈 Анализ результатов: Триумф в симуляциях 26:50
Несмотря на теоретические замечания ведущего, экспериментальные результаты Plan2Explore демонстрируют превосходные показатели на стандартных бенчмарках. Авторы оценивали алгоритм в двух сценариях:
- Zero-shot адаптация (Офлайн-обучение): Агент собирал данные без наград, траектории сохранялись в буфер, а затем ретроспективно размечались под конкретную задачу. В этом тесте Plan2Explore разгромил другие методы внутренней мотивации и вплотную приблизился к показателям алгоритма Dreamer, который изначально обучался со сквозным доступом к целевой награде.
- Few-shot адаптация (Онлайн-дообучение): После долгой фазы слепого поиска агенту открывали доступ к внешнему вознаграждению для быстрой донастройки. В ряде тестов предобученный Plan2Explore совершил резкий скачок и даже превзошел полностью контролируемый Dreamer. Как поясняет Кильхер, это связано с тем, что классический Dreamer быстро застревал в локальных оптимумах среды, тогда как Plan2Explore накопил фундаментальные знания о физике мира и избежал этой ловушки.
В финальном резюме Янник Кильхер призывает относиться к результатам с долей осторожности, поскольку современные RL-симуляторы искусственно обеднены разработчиками. В них практически отсутствует фоновый шум, а любые нетривиальные действия робота (например, удержание баланса) неявно ведут к выполнению итоговой задачи. Тем не менее, публикация исходного кода авторами признается важным шагом для открытого научного сообщества.