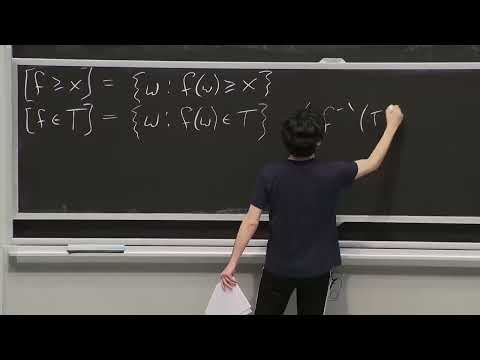
В рамках курса Массачусетского технологического института (MIT OpenCourseWare) преподаватель Бринмор Чэпмен представляет глубокий анализ одного из самых неоднозначных понятий теории вероятностей — случайных величин. Вопреки исторически сложившемуся названию, эти объекты не содержат в себе элемента случайности и не являются переменными в привычном смысле. Лектор подробно объясняет математическую суть концепции, иллюстрирует её прикладное значение на примере создания выигрышных алгоритмов и демонстрирует силу математической аппроксимации для сложных распределений.
🎲 Парадокс названия: почему случайная величина вовсе не случайная 0:00
В начале своего выступления Бринмор Чэпмен сразу обращает внимание аудитории на лингвистический парадокс: термин «случайная величина» (random variable) является очевидным мисномерном, закрепившимся в науке исключительно по историческим причинам. На самом деле этот математический объект не является ни случайным, ни переменным. С технической точки зрения, случайная величина — это обыкновенная детерминированная функция, которая отображает элементы пространства исходов случайного эксперимента в множество вещественных чисел.
Для демонстрации этого тезиса Чэпмен предлагает рассмотреть классический мысленный эксперимент с одновременным подбрасыванием трех симметричных, физически независимых монет. Пространство исходов данного эксперимента представляет собой упорядоченные тройки, состоящие из «орлов» (heads) и «решек» (tails) — всего существует восемь равновероятных комбинаций.
На этом пространстве исходов можно определить несколько различных случайных величин:
- Функция $f(\omega)$, возвращающая точное количество выпавших «орлов» в исходе.
- Функция $g(\omega)$, принимающая значение 1, если при первом броске выпал «орел», и 0 в противном случае.
- Функция $h(\omega)$, возвращающая 1, если результаты всех трех бросков совпали, и 0 во всех остальных исходах.
Каждая из этих функций берет конкретный, уже зафиксированный исход эксперимента и по строгим правилам сопоставляет ему число, что полностью исключает элемент неопределенности на этапе работы самой функции.
📊 Индикаторы и порождение новых событий 5:06
Особое место в теории вероятностей занимают функции, подобные $g(\omega) и h(\omega)$, область значений которых ограничена строго нулем и единицей. Преподаватель дает им фундаментальное определение — индикаторы, или бинарные случайные величины. По словам Чэпмена, индикаторы и классические случайные события находятся в неразрывной математической взаимосвязи.
Любой индикатор естественным образом порождает событие: подмножество исходов, на которых функция принимает значение 1, эквивалентно наступлению исследуемого события, а подмножество исходов со значением 0 формирует его дополнение. Справедливо и обратное утверждение.
Для любого произвольного события $A$ можно сконструировать собственный индикатор, обозначаемый в математической литературе как $\mathbb{1}_A$. Данная функция будет равна единице для всех исходов, входящих в подмножество $A$, и нулю для исходов вне его.
Обобщая эту логику на любые случайные величины, Чэпмен вводит стандартную вероятностную нотацию. Если имеется функция $f$ и некоторое число $x$, математики могут зафиксировать событие, записываемое как $f = x$. Под этой лаконичной записью скрывается полноценное множество исходов эксперимента $\omega$, для которых выполняется равенство $f(\omega) = x$. Аналогичным образом конструируются более сложные предикаты, например, события вида $f \ge x$ или утверждение о принадлежности значения функции некоторому подмножеству вещественных чисел.
🔗 Условная вероятность и тонкости независимости 11:22
Поскольку математические выражения, построенные на основе случайных величин, по сути описывают классические события, к ним применимы все базовые инструменты теории вероятностей, включая кондиционирование (вычисление условной вероятности) и анализ независимости. Чэпмен иллюстрирует условную вероятность на примере ранее созданных функций для трех монет. Если необходимо найти вероятность того, что функция количества «орлов» $f$ равна двум, при условии, что индикатор совпадения всех монет $h$ равен единице, математическая запись примет вид $P(f=2 \mid h=1)$.
Развернув формулу условной вероятности через отношение пересечения событий к вероятности условия, становится очевидно, что искомое значение равно нулю. По мнению лектора, этот результат интуитивно понятен: если известно, что все три монеты упали одинаково, то выпадение ровно двух «орлов» становится физически невозможным.
Однако при переходе к понятию независимости случайных величин математический аппарат начинает заметно усложняться. Чэпмен подчеркивает принципиальное различие: две случайные величины $f$ и $g$ признаются независимыми тогда и только тогда, когда условие независимости выполняется для всех возможных пар значений $x$ и $y$, которые эти функции могут принять. Математически это выражается через равенство:
$$P(f = x, g = y) = P(f = x) \cdot P(g = y)$$
Для обычных событий достаточно проверить независимость одной конкретной пары подмножеств. Для случайных величин требуется тотальная квантификация по всей области значений. В качестве альтернативы лектор предлагает использовать эквивалентное определение через условную вероятность: знание того, какое именно значение приняла величина $g$, не должно менять безусловную вероятность для величины $f$.
Анализируя базовый пример с тремя монетами, Чэпмен вместе со студентами приходит к следующим выводам:
- Величины $f$ (количество «орлов») и $g$ (результат первого броска) зависимы, поскольку если $g = 0$ (первый бросок — решка), то общее число «орлов» $f$ заведомо не может быть равным трем.
- Величины $f$ и $h$ (индикатор совпадения) также демонстрируют жесткую зависимость, так как значение $h$ полностью предопределяется значением $f$.
- Пара величин $g$ и $h$ оказывается полностью независимой: знание результата первого броска никак не влияет на вероятность того, совпадут ли между собой оставшиеся монеты.
📈 От пространства исходов к распределениям: PMF и CDF 21:57
Историческое развитие математики привело к тому, что ученые научились абстрагироваться от сложной внутренней структуры исходного пространства исходов и переключили внимание непосредственно на поведение значений случайных величин. Инструментом для такой абстракции выступает понятие распределения, которое описывает вероятности, с которыми случайная величина принимает те или иные значения.
Для детального описания распределения дискретных случайных величин используется функция вероятностной массы (PMF), определяющая точную вероятность равенства функции конкретному числу: $p_f(x) = P(f = x)$. Чэпмен делает важную терминологическую ремарку: в некоторых учебниках, включая используемый в курсе MIT текст, эту функцию называют PDF (функцией плотности вероятности).
Однако лектор призыват разделять эти понятия. Плотность (PDF) необходима для непрерывных величин, где вероятность попасть в конкретную точку всегда равна нулю — подобно дротику, который никогда не попадет в идеальную математическую точку на мишени. Для дискретных же систем использование термина PMF является более строгим и корректным.
Параллельно с PMF вводится кумулятивная функция распределения (CDF), которая рассчитывается как вероятность того, что случайная величина не превысит заданное значение $x$:
$$F_f(x) = P(f \le x) = \sum_{y \le x} P(f = y)$$
Чэпмен наглядно демонстрирует поведение этих функций на базовых примерах:
- Для индикатора Бернулли PMF имеет вид двух пиков (в точках 0 и 1 с вероятностями $1-p$ и $p$ соответственно), а CDF представляет собой простую ступенчатую функцию.
- Для равномерной случайной величины, принимающей целые значения от 1 до $n$, PMF стабильно равна $1/n$ на всем интервале. Функция CDF в этом случае превращается в кусочно-постоянную ступенчатую структуру, которая совершает скачок вверх на величину $1/n$ при переходе через каждое целое число.
🍬 Задача о коробках с конфетами: как обыграть случайность 33:15
Чтобы продемонстрировать практическое могущество теории вероятностей в компьютерных науках, Бринмор Чэпмен предлагает студентам интерактивную задачу-игру. Представьте две закрытые коробки, в которые лектор поместил разное количество конфет (в диапазоне от 0 до 10). Задача игрока — выбрать коробку с наибольшим содержимым, разрешив при этом открыть и посмотреть внутрь только одной из них. На первый взгляд кажется, что шансы на успех детерминированно ограничены чистым угадыванием с вероятностью 1/2.
Чэпмен предлагает упростить условия: предположим, игроку гарантируют, что в одной из коробок точно больше 5 конфет, а в другой — меньше или равно 5. В таком сценарии стратегия становится тривиальной: игрок открывает случайную коробку, и если там обнаруживается более 5 конфет, он оставляет её себе. Если же конфет оказывается меньше, игрок уверенно забирает вторую коробку. Данная стратегия гарантирует стопроцентный выигрыш.
Но как действовать в условиях полной неопределенности, когда никакого априорного порога не задано? Решением становится внедрение искусственной случайности в сам процесс принятия решений. Чэпмен формулирует алгоритм: игроку необходимо случайным образом выбрать собственный порог (число от 0 до 10), притвориться, что этот порог истинен, и реализовать вышеописанную стратегию.
Для расчета эффективности этого подхода применяется формула полной вероятности. Математический расчет выглядит следующим образом:
$$P(\text{выигрыша}) = P(\text{выигрыша} \mid \text{угадал порог}) \cdot P(\text{угадал порог}) + P(\text{выигрыша} \mid \text{не угадал}) \cdot P(\text{не угадал})$$
Если выбранный игроком порог случайно оказался верным разделителем между содержимым коробок (вероятность чего составляет как минимум 1/10), стратегия дает стопроцентную победу. Если же порог оказался ошибочным, игрок все равно побеждает в половине случаев — когда изначально выбранная коробка чисто случайно оказывается большей. Итоговая вероятность математически рассчитывается как:
$$1 \cdot \frac{1}{10} + \frac{1}{2} \cdot \frac{9}{10} = 0.55$$
Таким образом, общая вероятность успеха возрастает до 55%. По мнению Чэпмена, этот пример наглядно иллюстрирует концепцию вероятностных (рандомизированных) алгоритмов. Введение контролируемой случайности в детерминированные задачи позволяет кардинально повышать их эффективность и преодолевать жесткие ограничения стандартных подходов, что активно используется в современных алгоритмах обработки данных.
🪙 Биномиальное распределение и магия аппроксимации Стирлинга 47:39
В финальной части лекции Чэпмен переходит к разбору биномиального распределения $\text{Bin}(n, p)$, которое является базовой моделью для множества процессов в ИТ-индустрии, включая оценку надежности сложных систем и подсчет отказов независимых компонентов. Данное распределение описывает поведение случайной величины $X$, равной числу успешных исходов в серии из $n$ независимых испытаний, в каждом из которых успех достигается с фиксированной вероятностью $p$.
Функция вероятностной массы для биномиального распределения вычисляется по классической комбинаторной формуле:
$$P(X = x) = \binom{n}{x} p^x (1-p)^{n-x}$$
Она учитывает количество возможных последовательностей испытаний и индивидуальную вероятность каждой цепочки. Кумулятивная функция CDF в данном случае представляет собой обычную сумму значений PMF от нуля до целой части $x$. Однако на практике проведение таких прямых вычислений для больших выборок (например, при $n = 100$ и более) сопряжено с колоссальными вычислительными трудностями из-за расчета факториалов.
Для преодоления этой проблемы лектор демонстрирует метод аппроксимации с использованием знаменитой формулы Стирлинга для факториалов: $n! \approx \sqrt{2\pi n} (n/e)^n$. Заменяя в биномиальном коэффициенте каждый факториал его приближением и подставляя долю успехов $\alpha = x/n$, Чэпмен осуществляет ряд последовательных алгебраических преобразований. Переходя к логарифмическому базису, итоговую формулу PMF удается свести к изящному экспоненциальному виду:
$$f(\alpha n) \approx \frac{1}{\sqrt{2\pi \alpha(1-\alpha)n}} \cdot 2^{n \left[ \alpha \log_2 \frac{p}{\alpha} + (1-\alpha) \log_2 \frac{1-p}{1-\alpha} \right]}$$
Анализируя полученный показатель экспоненты, Чэпмен обращает внимание на его фундаментальное свойство: данное выражение всегда строго отрицательно, за исключением единственной точки, где доля успехов совпадает с истинной вероятностью ($\alpha = p$), превращая показатель в ноль. Это означает, что график распределения имеет четко выраженный пик в области математического ожидания и экспоненциально стремительно затухает при удалении в область экстремальных значений («хвосты» распределения).
Чтобы проиллюстрировать этот математический факт, Чэпмен приводит конкретные цифровые расчеты для серии из 100 подбрасываний монеты с вероятностью успеха 0.5:
- В центральной точке ($\alpha = 0.5$) вероятность получить ровно 50 «орлов» составляет около 8% ($0.08$).
- При смещении к хвосту распределения ($\alpha = 0.25$) вероятность получить ровно 25 «орлов» падает до ничтожно малой величины порядка $10^{-7}$.
Из этого экспоненциального затухания вытекает крайне парадоксальный и контрнтуитивный вывод теории вероятностей: в глубоком хвосте распределения вероятность получить точное пограничное значение оказывается выше, чем вероятность получить в сумме все значения, лежащие еще дальше за этим порогом. Математически вероятность экстремального выброса $P(X \le 24)$ оказывается строго меньше, чем вероятность единичного исхода $P(X = 25)$.
При этом в центре распределения действует прямо противоположная логика: вероятность получить менее 50 «орлов» составляет около 46%, что многократно превышает вероятность выпадения ровно 50 «орлов». Завершая занятие, Бринмор Чэпмен анонсирует, что подробный анализ этих пограничных зон и вычисление строгих математических границ для хвостов распределений (tail bounds) станут главными темами следующей лекции.




