Инновации в голосовом интерфейсе: Джастин Уберти об OpenAI Realtime API
Голосовое общение — это фундаментальный способ взаимодействия между людьми, который постепенно становится ключевым интерфейсом для будущего взаимодействия с искусственным интеллектом. В ходе выступления на конференции DeepLearning.AI Джастин Уберти, руководитель направления инфраструктуры реального времени в OpenAI, подробно разобрал возможности и архитектуру OpenAI Realtime API. Основная цель технологии — обеспечить максимально естественное и быстрое общение, где задержка между репликами собеседника минимальна, создавая ощущение полноценного диалога в реальном времени.
🚀 Почему важна задержка и как работает Realtime API
Ключевым фактором успеха голосового агента является низкая задержка. Уберти отмечает, что в человеческих разговорах пауза между репликами составляет в среднем около 200 миллисекунд. Увеличение этого интервала часто заставляет участников диалога сомневаться в искренности или уверенности собеседника.
От «каскадной» модели к единому потоку
Традиционные системы голосового управления строились по «каскадному» принципу, который Уберти называет неэффективным и медленным:
- ASR (автоматическое распознавание речи): превращает звук в текст.
- LLM: обрабатывает текстовый запрос.
- TTS (текст-в-речь): озвучивает ответ.
Такая цепочка создает избыточность, так как каждая стадия требует работы собственного языкового модуля, а TTS вынужден использовать «поиск вперед» для определения нужной эмоциональной окраски. OpenAI Realtime API использует принципиально иной подход — speech-to-speech (речь-в-речь) на базе технологии GPT-4o:
- Входящий аудиопоток напрямую конвертируется в высокоразмерное пространство модели, минуя стадию транскрипции в текст.
- Модель генерирует ответ в виде набора данных, которые превращаются в аудио.
- Это позволяет сохранить паралингвистические характеристики — тон, акцент и интонации, которые были бы утрачены при классическом подходе.
🛠 Архитектура и инструменты разработки
Разработчики могут выбирать разные способы интеграции Realtime API в свои приложения. По словам Уберти, наиболее современным и эффективным решением является использование WebRTC.
- Преимущества WebRTC: прямое соединение клиента с API OpenAI обеспечивает автоматическое эхоподавление и шумоподавление.
- Безопасность: чтобы не раскрывать секретный API-ключ на клиенте, приложение запрашивает «эфемерный токен» на сервере, который действует 1 минуту.
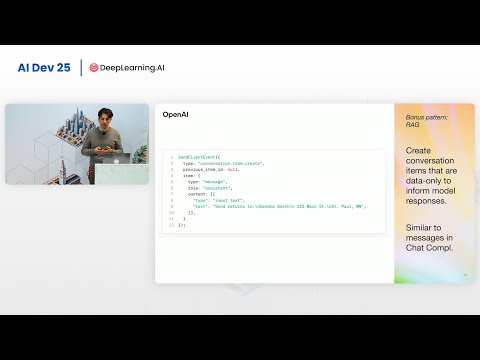
- Событийная модель: API работает на основе обмена событиями, такими как
response.create(запуск генерации) илиsession.update(изменение настроек агента).
🧠 Инструкции, роли и «промптинг» голосом
Одной из сильных сторон Realtime API является управляемость агента с помощью промптов, аналогичных тем, что используются в обычных LLM. Джастин Уберти подчеркивает, что глубокая модель обладает огромным объемом знаний о мире, что позволяет ей легко менять идентичность и стиль:
- Задание идентичности: четкое определение того, кто такой агент (например, «помощник в отеле» или «пират»).
- Тон и лексика: использование инструкций по стилю речи, включая добавление слов-паразитов для большей естественности.
- Специфические задачи: можно задать жесткие правила, такие как «никогда не обещай конкретный подарок» (на примере Санта-AI).
🛡 Безопасность и «guardrails»
Для корпоративных решений критически важно наличие «защитных барьеров» (guardrails), чтобы предотвратить нежелательное поведение модели, например, попытки пользователя «взломать» агента через команды типа «игнорируй все предыдущие инструкции».
Уберти предлагает метод фильтрации транскрипта в реальном времени: так как модель генерирует текст быстрее, чем происходит озвучивание, система может успеть остановить воспроизведение, если обнаружит в тексте «запрещенные слова».
💡 Будущее: Reasoning-модели и оркестрация
Спикер признает, что текущая модель GPT-4o, оптимизированная под скорость, не обладает способностями к глубокому рассуждению, которыми славятся модели серии o1 или o3. Однако в будущем OpenAI планирует «навести мосты» между моделями реального времени и моделями глубокого рассуждения.
Демонстрация Уберти показала потенциал «vibe coding», где голосовой агент выступает в роли координатора: он принимает запрос от пользователя, а затем делегирует сложную задачу (например, написание кода игры) модели o3-mini, которая возвращает результат для отображения.




