BLEURT: Инновационный подход к оценке качества генерации текста 0:00
Исследователи из Google представили BLEURT (Bilingual Evaluation Understudy with Representations from Transformers) — новую метрику для оценки качества автоматического перевода и других задач генерации текста. В отличие от классических методов, основанных на простом подсчете совпадений n-грамм, BLEURT использует предобученную модель BERT, адаптированную для моделирования человеческих оценок. Ведущий канала Янник Килхер отмечает, что хотя подход выглядит многообещающе, методология оценки «дрейфа» модели вызывает вопросы из-за архитектурного однообразия современных систем.
Проблема традиционных метрик 1:07
Для оценки качества машинного перевода десятилетиями использовались такие метрики, как BLEU и ROUGE. Их работа основана на сопоставлении n-грамм — коротких фрагментов текста из 3–4 слов — в переводе системы и в «золотом стандарте», созданном человеком.
По мнению Янника Килхера, эти методы имеют ряд существенных недостатков:
- Эвристическая природа: Они не учитывают семантику, а лишь поверхностное сходство текста.
- Снижение корреляции: С появлением современных нейросетевых моделей (особенно на базе архитектуры Transformer) системы перевода стали настолько качественными, что традиционные метрики перестали адекватно отражать реальное восприятие качества людьми.
- Ненадежность: При сравнении двух высококлассных моделей BLEU часто выдает оценки, которые расходятся с вердиктами лингвистов.
Методология BLEURT: зачем нужно «прайминг» 5:09
BLEURT превращает задачу оценки качества в задачу машинного обучения. Модель принимает на вход пару «исходный текст / перевод системы» и предсказывает оценку, которую поставил бы человек. Однако авторы столкнулись с проблемой дефицита данных: человеческие оценки дороги, а их количество ограничено.
Для решения этой задачи исследователи предложили новую схему предобучения, которую Янник Килхер называет «праймингом» (priming):
- Маскированное языковое моделирование: Базовый этап, позволяющий BERT выучить структуру языка.
- Синтетический «прайминг»: На этом этапе модель обучается на миллионах синтетических пар предложений, которые создаются путем намеренного искажения оригинальных текстов (из Википедии).
- Тонкая настройка (Fine-tuning): Итоговое обучение на реальных человеческих оценках.
Для создания синтетических данных авторы использовали маскирование слов, обратный перевод (back-translation) и простое удаление токенов. Затем модель обучается предсказывать баллы по ряду вспомогательных метрик (BLEU, ROUGE, BERTScore и другие), что помогает ей «настроиться» на нюансы семантической близости.
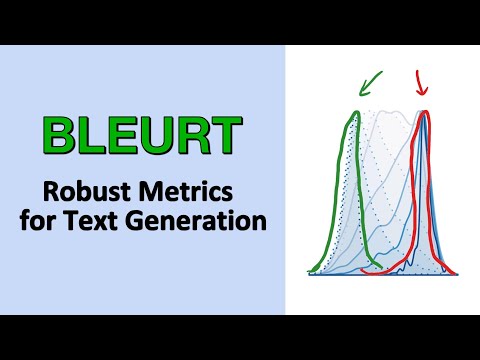
Анализ устойчивости к «дрейфу» данных 23:49
Авторы исследования утверждают, что BLEURT устойчив к распределенному сдвигу (distribution shift) — ситуации, когда качество моделей растет со временем, а данные для оценки устаревают. Для проверки этого они искусственно «перекосили» данные (skew factor), разделив их на очень качественные и очень плохие. Согласно результатам, даже при значительном сдвиге BLEURT сохраняет высокую корреляцию с человеческими оценками, превосходя стандартные метрики.
Критический взгляд и риски 27:01
Несмотря на заявленную эффективность, Янник Килхер высказывает ряд критических замечаний:
- Искусственность тестов: Искусственное разделение данных на «плохие» и «хорошие» не полностью моделирует реальный прогресс технологий.
- Архитектурный застой: По мнению ведущего, главная проблема в том, что BLEURT, системы перевода и вспомогательные метрики (Entailment, Back-translation) — это всё нейросети на базе Transformer.
- Систематическая ошибка: Килхер полагает, что если все эти системы совершают одни и те же «архитектурные» ошибки, они будут «одобрять» друг друга, создавая иллюзию качества. Он сравнивает это с попыткой получить бесконечную энергию, воткнув вилку удлинителя в его собственную розетку.
В заключение автор обзора отмечает, что, несмотря на риски, инструмент доступен разработчикам, и его стоит использовать для оценки собственных моделей в связке с регулярным человеческим контролем.




