Команда исследователей из DeepMind представила NFNets — новое семейство сверточных нейросетей для распознавания изображений, способных эффективно обучаться без использования пакетной нормализации (Batch Normalization). Известный исследователь искусственного интеллекта и популярный научный блогер Янник Кильхер (Yannic Kilcher) подробно разобрал предложенный авторами метод адаптивного отсечения градиентов (AGC), а также указал на ряд скрытых архитектурных зависимостей новой модели. Обзор предлагает критический анализ того, действительно ли разработчикам удалось полностью избавить глубокое обучение от недостатков классического Batch Norm.
🛑 Проблема пакетной нормализации: почему её хотят заменить 2:41
Пакетная нормализация (Batch Normalization) давно стала стандартом в глубоком обучении, однако она имеет серьезные изъяны, усложняющие масштабирование моделей. Как объясняет Янник Кильхер, при прохождении данных через слои нейросети их распределение неизбежно искажается. Особенно сильно на это влияют нелинейные функции активации вроде ReLU, которые отсекают отрицательную часть сигнала, из-за чего промежуточные представления данных теряют центрирование. Batch Norm решает эту проблему, вычисляя среднее значение и дисперсию для каждого текущего мини-пакета (mini-batch) и стандартизируя данные перед передачей на следующий слой.
Согласно анализу авторов статьи из DeepMind, Batch Norm обладает тремя ключевыми практическими недостатками:
- Высокая вычислительная стоимость: эта операция является на удивление дорогой операцией, которая требует постоянного подсчета статистик и их сохранения в памяти для последующего обратного распространения ошибки, что существенно увеличивает время оценки градиента в некоторых сетях.
- Рассогласование между обучением и инференсом: во время тестирования модели пакетная зависимость нежелательна, так как система должна выдавать стабильный результат для одного изолированного примера. Для этого разработчикам приходится создавать специальные буферы для расчета скользящего среднего, что вводит скрытые гиперпараметры (например, скорость затухания среднего), требующие тонкой настройки.
- Нарушение независимости примеров в пакете: это самый критический недостаток, поскольку поведение модели начинает напрямую зависеть от того, какие еще изображения оказались в текущем мини-пакете.
Из-за нарушения независимости размер пакета начинает критически влиять на стабильность обучения: большие пакеты дают хорошую аппроксимацию истинного среднего, тогда как малые пакеты (например, всего из трех элементов) приводят к зашумленным оценкам. По словам Кильхера, распределенное обучение в условиях параллелизма данных (data parallelism) становится из-за этого крайне громоздким. При разделении одного пакета на несколько машин инженерам приходится постоянно передавать статистики Batch Norm между серверами, чтобы получить среднее по всему батчу, что усложняет вычисления. Это приводит к плохой воспроизводимости кода на разном оборудовании и частым ошибкам реализации.
Кроме того, Янник Кильхер отмечает специфический крайний случай, когда Batch Norm позволяет сети «жульничать» на этапе обучения. Например, при прогнозировании временных рядов или в языковом моделировании, когда одна последовательность нарезается на перекрывающиеся обучающие сэмплы, информация о метках может неявно утекать из одного примера в другой через агрегированные статистики пакета.
⚙️ Что делает Batch Norm полезным и как это повторить 13:30
Перед тем как полностью убрать пакетную нормализацию, авторам исследования необходимо было понять, какие именно полезные функции она выполняет. Исследователи выделили четыре фундаментальных преимущества Batch Norm, которые обеспечивают стабильность современных архитектур:
- Неявное уменьшение масштаба остаточной ветви (residual branch), что смещает баланс силы сигнала в пользу функции идентичности (identity function) и стабилизирует обучение.
- Устранение смещения среднего значения (mean shift), вызываемого нелинейными активациями вроде ReLU.
- Эффект регуляризации за счет естественного шума в статистиках пакета, помогающий бороться с переобучением.
- Обеспечение эффективного обучения с большими пакетами благодаря сглаживанию ландшафта потерь, что позволяет увеличивать максимальный стабильный шаг обучения.
Попытки избавиться от нормализации предпринимались авторами и ранее в их работе на конференции ICLR, где они разработали структуру NF-ResNets (Normalizer-Free ResNets). В тех моделях исследователи пытались обойтись без Batch Norm, детально рассчитывая, как именно каждый блок нейросети изменяет дисперсию данных. Они ввели фиксированные константы $\alpha$ и $\beta$ (одна применяется до слоя, другая после), адаптированные под конкретную архитектуру, чтобы дисперсия оставалась неизменной при движении вглубь сети.
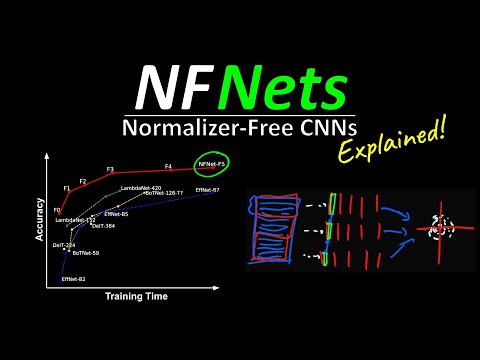
Хотя старые NF-ResNets успешно обучались при размере пакета 1024 и даже превосходили аналоги с Batch Norm на очень маленьких пакетах, при увеличении размера батча их стабильность падала. Главное, по оценке Кильхера, старая архитектура не могла сравниться по эффективности с передовыми моделями вроде EfficientNet. Новое исследование NFNets призвано исправить этот барьер.
📈 Адаптивное отсечение градиентов (AGC) — секретное оружие NFNets 10:43
Ключевым нововведением работы стало внедрение метода адаптивного отсечения градиентов (Adaptive Gradient Clipping, AGC). В классическом глубоком обучении ограничение величины градиента (gradient clipping) используется для предотвращения резких скачков весов, которые дестабилизируют оптимизаторы и портят momentum-термы или буферы Adam. Однако традиционный подход крайне чувствителен к жестко заданному порогу отсечения, поскольку он не адаптируется к масштабу самих параметров.
Метод AGC, предложенный специалистами DeepMind, работает иначе: он сопоставляет норму градиента с нормой самого весового коэффициента. Формула отсечения опирается на покомпонентное отношение нормы градиента к норме веса, на который этот градиент воздействует. Кильхер объясняет логику алгоритма на простом примере: если текущий вес мал, то и предлагаемое изменение должно быть небольшим; если же параметр изначально имеет большой масштаб, то сеть может позволить себе более крупные шаги оптимизации. Ведущий признает, что сравнение чистых норм — это лишь хорошая эвристика, не учитывающая направление вектора, однако на практике она работает на удивление эффективно.
Проведенные авторами тесты (ablations) наглядно показывают силу AGC. В то время как стандартные сети без нормализации мгновенно разрушаются (collapse) при превышении определенного размера пакета, интеграция адаптивного отсечения градиентов позволяет NFNets стабильно масштабироваться наравне с Batch Norm. При этом выявилась интересная зависимость: на малых пакетах можно выставлять высокий порог отсечения, но для работы с гигантскими батчами порог AGC необходимо существенно занижать во избежание коллапса.
🧠 Критический разбор Янника Кильхера: скрытые зависимости и старые проблемы 23:03
Несмотря на впечатляющие результаты NFNets, Янник Кильхер высказал жесткую критику в отношении некоторых теоретических заявлений авторов. Исследователь утверждает, что вопреки декларациям создателей, NFNets так и не смогли полностью ликвидировать зависимость процесса обучения от размера пакета.
Суть проблемы кроется в математической природе градиента. Конечный градиент веса представляет собой среднее арифметическое (или сумму) градиентов по всем индивидуальным примерам в мини-пакете. В больших батчах случайный шум усредняется и падает относительно полезного сигнала. Кильхер внимательно изучил исходный код авторов и обнаружил, что операция AGC применяется уже после того, как градиенты были усреднены по всему пакету.
По мнению Кильхера, это приводит к следующим неявным эффектам:
- Если в батче из 4 элементов окажется один аномальный пример, он вызовет резкий всплеск среднего градиента всего батча, и порог отсечения должен быть достаточно высоким, чтобы поймать его.
- Если тот же аномальный пример попадет в батч из 1024 элементов, его вклад в среднее значение размоется, и для фильтрации этой аномалии порог отсечения придется делать значительно ниже.
Таким образом, делает вывод Кильхер, примеры внутри пакета остаются неявно взаимосвязанными, как и в случае с Batch Norm. Ведущий в шутку добавил, что эту проблему можно решить, если выполнять отсечение градиентов индивидуально для каждого примера до их усреднения, и иронично попросил будущих исследователей сослаться на его YouTube-канал, если эта идея поможет им написать новую статью.
Еще одна деталь, вызвавшая скепсис Кильхера, касается критики авторами разного поведения Batch Norm при обучении и инференсе. Он напоминает, что в архитектуре NFNets активно используется Dropout. По словам Кильхера, Dropout обладает ровно тем же свойством — его поведение во время тренировки кардинально отличается от работы на этапе тестирования, поэтому обвинения в адрес Batch Norm выглядят здесь несколько непоследовательно.
⚡ Архитектура NFNet и её реальная производительность на железе 30:05
Вторая половина научной работы посвящена масштабному автоматическому поиску архитектуры (architecture search) для построения максимально производительного блока нейросети. Разработчики спроектировали два новых типа блоков для ResNet, содержащих константы $\alpha$ и $\beta$ для поддержания дисперсии. Кильхер критически замечает, что масштабный поиск архитектуры — это независимая задача, которую можно было успешно провести и для классических сетей с Batch Norm, поэтому не совсем понятно, какая доля успеха NFNets принадлежит именно отказу от нормализации, а какая — удачной геометрии блоков.
Тем не менее, с практической точки зрения NFNets демонстрируют выдающиеся результаты благодаря смене фокуса оптимизации. В отличие от EfficientNet, создатели которой стремились минимизировать количество теоретических операций (FLOPs), авторы NFNets оптимизировали модель под задержку обучения (training latency) на реальном железе — современных графических (GPU) и тензорных (TPU) ускорителях. Современные процессоры имеют жесткие архитектурные ограничения и не всегда могут эффективно использовать экономию на теоретических FLOPs.
Благодаря такому подходу NFNets устанавливают новые рекорды:
- Скорость обучения: для достижения той же точности, что и у EfficientNet-B7, сети NFNet требуется в 8.7 раза меньше времени при оценке задержки тренировки.
- Абсолютная точность: при одинаковой длительности обучения с EfficientNet-B7, модель от DeepMind показывает более высокую точность top-1 на ImageNet без привлечения сторонних датасетов.
- Трансферное обучение: NFNets заняли второе место в глобальном лидерборде ImageNet, уступив лишь методу с полуконтролируемым предварительным обучением на огромных объемах дополнительных данных. Янник сравнил погоню за рекордами в ImageNet со спидранами в видеоиграх, где теперь появились свои категории «без багов» (glitch-less) и «без экстра-данных».
В завершение обзора Кильхер выразил особый восторг по поводу приложения «Appendix E» к статье DeepMind, которое целиком посвящено негативным результатам. Там авторы честно перечислили целый лист идей, техник и конфигураций, которые они протестировали, но которые абсолютно не сработали. По мнению блогера, это невероятно полезный материал, показывающий начинающим специалистам, что даже ведущие мировые исследователи сталкиваются с огромным количеством неудач на пути к успеху. Исходный код проекта написан на фреймворке JAX и полностью открыт для сообщества.




