TAPAS: революция в работе с таблицами через предобучение 1:52
В данном разборе Янник Килчер (Yannic Kilcher) анализирует исследовательскую работу «TAPAS: Weakly Supervised Table Parsing via Pre-training», авторы которой предлагают инновационный подход к извлечению ответов из табличных данных с помощью нейронных сетей. Вместо классического написания SQL-запросов, которое часто бывает хрупким, исследователи предлагают использовать единую модель глубокого обучения, способную «понимать» таблицу как естественный язык и выполнять над ней вычисления.
🧠 Суть задачи и проблемы табличного парсинга 2:17
Задача «табличного парсинга» заключается в том, чтобы, имея таблицу и вопрос пользователя, найти верный ответ. По мнению Килчера, это сложная задача, так как вопросы могут принимать разные формы:
- Выбор ячейки (cell selection): когда ответ содержится непосредственно в таблице (например, имя чемпиона по количеству побед).
- Скалярный ответ (scalar answer): когда требуется вычислить значение, которого нет в таблице (например, среднее арифметическое).
- Амбивалентные ответы: ситуации, когда ответ — число, которое может присутствовать в таблице, но требует вычислений (например, подсчет строк, где значение равно 1).
Раньше для таких задач требовалось извлекать заголовки, определять типы данных и переводить запрос в SQL, что, по словам ведущего, является «хрупким» подходом, уступающим методам глубокого обучения.
🏗 Архитектура модели TAPAS 6:28
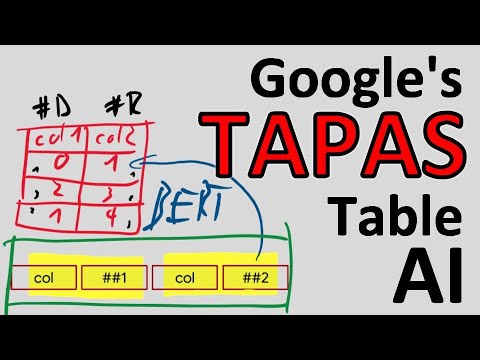
Модель TAPAS основывается на архитектуре Transformer (аналогичной BERT) и обрабатывает таблицу не как структуру данных, а как последовательность естественного языка. Ключевые особенности входных данных:
- Сериализация: Таблица превращается в одну длинную строку текста.
- Специальные эмбеддинги: Чтобы модель понимала структуру, авторы добавили новые типы векторных представлений (embeddings):
- Колоночные и строчные (column/row embeddings): указывают модели, в какой строке и столбце находится токен.
- Ранговые (rank embeddings): позволяют модели быстрее находить «лучшие», «худшие» или «топ-N» значения, так как для каждого столбца вводится информация о ранжировании данных.
Модель состоит из двух основных компонентов: классификатора агрегации (выбирает действие: count, sum, average или none) и селектора ячеек.
📉 Обучение на слабых сигналах 18:46
Самым интересным и «почти невозможным» аспектом модели Килчер называет процесс обучения. Поскольку у модели есть только вопрос и итоговый ответ (без промежуточных шагов), она обучается с помощью «мягких решений» (soft decisions):
- Модель делает предсказания вероятностей для операций (например, 0.1 на
count, 0.3 наsum, 0.6 наaverage). - Затем вычисляются все три варианта ответа, и итоговый результат представляет собой взвешенную сумму.
- Функция потерь (loss function) рассчитывает квадратичную ошибку между полученным результатом и верным ответом.
Ведущий отмечает, что это работает как задача обучения с подкреплением при слабом сигнале: через огромное количество примеров модель учится связывать вопросы с конкретными ячейками и математическими операциями.
📊 Итоги и перспективы 30:49
Янник Килчер признается, что скептически относился к масштабируемости такого подхода, однако результаты модели TAPAS превосходят все существующие аналоги на большинстве наборов данных. Хотя в видео обсуждаются лишь три типа операций, потенциальное расширение на десятки функций может привести к неопределенности в распределении весов, что остается предметом для будущих исследований. Тем не менее, как подчеркивает Килчер, авторы выложили код в открытый доступ, и метод уже демонстрирует высокую эффективность в задачах, требующих контекстно-зависимых ответов.




