Типичное декодирование: новый взгляд на генерацию естественного языка 🧠 0:00
В современном мире больших языковых моделей (LLM) качество генерации текста напрямую зависит от стратегии декодирования — того, как именно модель выбирает следующее слово из вероятностного распределения. Янник Килхер (Yannic Kilcher) в своем обзоре научной статьи «Typical Decoding for Natural Language Generation» (авторы: Клара Майстер, Тьяго Пиментель, Джон Вихер и Райан Коттерелл) разбирает альтернативный подход под названием «типичное семплирование» (typical sampling). Основная проблема существующих методов, таких как beam search, top-k и nucleus sampling (top-p), заключается в их склонности либо к «безопасным», но скучным результатам, либо к генерации несвязных фрагментов, что делает работу моделей менее «человекоподобной»,.
⚖️ Теоретические основы: почему мы говорим именно так? 17:09
В основе метода лежит гипотеза о том, что люди при общении интуитивно балансируют между двумя крайностями: передачей максимального объема информации и риском быть неправильно понятыми.
- Информационная ценность: В теории информации ценность сообщения определяется его «неожиданностью» (отрицательный логарифм вероятности). Если фраза предсказуема, она несет мало новой информации.
- Ожидаемая информация: Согласно гипотезе статьи, люди стремятся выбирать слова так, чтобы их личная информационная ценность была максимально близка к «ожидаемой» информационной ценности (условной энтропии),.
- Понятие типичности: Типичное сообщение — это не обязательно самое вероятное, а то, которое соответствует ожидаемому распределению. Именно этот баланс делает человеческую речь интересной, но при этом понятной.
🛠 Как работает типичное семплирование 36:34
В отличие от классических методов, которые принудительно выбирают наиболее вероятные токены, типичное семплирование использует динамический подход:
- Расчет энтропии: Модель вычисляет условную энтропию для текущего шага декодирования.
- Выбор слов: Вместо того чтобы брать топ-K слов или слова с суммарной вероятностью P, алгоритм выбирает те варианты, информационная ценность которых наиболее близка к вычисленному значению энтропии.
- Пороговое значение (Tau): Пользователь задает параметр $\tau$ (порог вероятностной массы), который определяет, какой объем распределения мы рассматриваем.
Этот метод особенно эффективен там, где существует огромное количество вариантов продолжения текста (например, в творческом письме или сторителлинге), тогда как для строго детерминированных задач (машинный перевод) он может быть менее полезен.
🧪 Оценка и скепсис ведущего 40:49
Янник Килхер отмечает, что метод показывает многообещающие результаты, но призывает к осторожности:
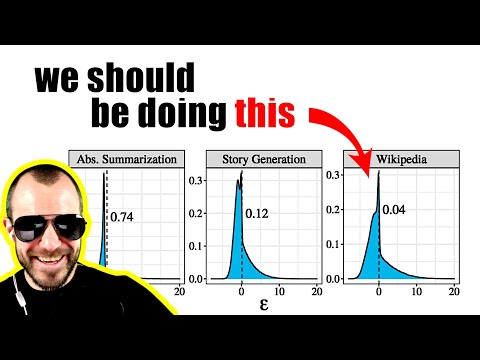
- Гиперпараметры: Для различных задач (сторителлинг против суммаризации) авторы статьи используют разные значения $\tau$, что требует дополнительной настройки.
- Вопросы к методологии: Килхер ставит под сомнение использование абсолютной разности между ожидаемой и реальной информацией в качестве метрики. Также он отмечает, что если LLM уже обучены на человеческих текстах, которые «типичны» по своей природе, возникает вопрос: почему простая выборка из модели не дает того же результата?
- Сравнение с аналогами: В задачах суммаризации типичное семплирование оказалось более сбалансированным: в отличие от него, top-k часто «теряет» важные детали, а nucleus sampling иногда склонно к галлюцинациям.
В конечном итоге, ведущий признает, что мы действительно нуждаемся в более гибких методах декодирования. Хотя к конкретной математической формулировке типичного семплирования остаются вопросы, сама идея адаптивного выбора слов на основе информационной теории выглядит крайне перспективной для будущего NLP.