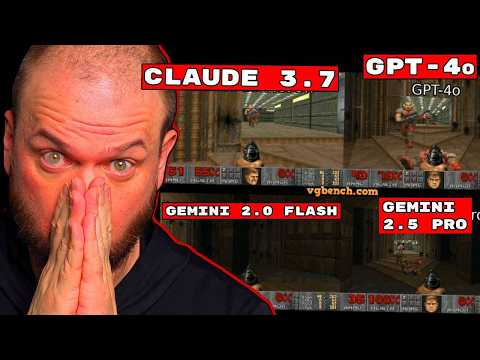
Компания Google представила масштабное обновление своей экосистемы искусственного интеллекта во главе с новой моделью Gemini 2.0. Известный технологический блогер и аналитик Уэс Рот (Wes Roth) подробно разобрал ключевые анонсы, включая продвинутого голосового ассистента Astra, автономного браузерного агента Project Mariner и новые возможности пространственного мышления моделей. По мнению автора, эти релизы наглядно демонстрируют наступление эры, когда ИИ превращается в полноценную операционную систему, меняющую повседневную жизнь человека.
🎙️ Проект Astra: универсальный голосовой помощник и повседневный компаньон 0:00
Развитие мультимодальных технологий позволило Google существенно модернизировать проект Astra. Уэс Рот поделился личным опытом использования ранней версии этого ассистента в режиме реального времени. Модель способна мгновенно распознавать и анализировать окружающую обстановку через камеру смартфона. В качестве примера ведущий показал, как Astra безошибочно распознала распечатанный план подготовки к лос-анджелесскому марафону 2025 года, вычленила из него типы тренировок и дала практический совет взять с собой 3–4 энергетических геля для 10-мильной пробежки.
Помимо анализа документов, Astra может выступать в роли интерактивного кулинарного тренера. Ассистент способен вести пользователя по рецепту шаг за шагом, оценивать через камеру точность нарезки продуктов (например, подтвердить, что ингредиенты нарезаны кусками примерно в 1 дюйм) и давать критические замечания.
Среди ключевых особенностей обновленной Astra выделяются следующие возможности:
- Долговременная память в рамках контекста: ассистент помнит детали прошлых бесед, например, рецепт сока из сельдерея с добавлением имбиря, обсуждавшийся ранее.
- Контекстуальные рекомендации: на основе уровня физической активности пользователя ИИ подбирает оптимальное меню (так, после тяжелой тренировки Astra порекомендовала креветки с кукурузной кашей и ветчиной тассо).
- Распознавание неочевидных объектов физического мира: ИИ легко идентифицировал пушистую ветрозащиту для микрофона, объяснив ее назначение на открытом воздухе.
По мнению Уэса Рота, в будущем подобные ИИ-помощники станут постоянными спутниками людей, функционируя через беспроводные наушники или смарт-очки дополненной реальности. Подобные системы смогут давать подсказки в реальном времени, помогать в навигации и даже генерировать остроумные ответы в диалогах.
🎮 ИИ-ассистенты в гейминге: коучинг без предварительной интеграции 6:43
Одним из самых зрелищных сценариев применения Gemini 2.0 стала демонстрация работы игрового агента. В отличие от классических ботов, этот ИИ не имеет прямого доступа к коду игры или специальной пост-тренировочной интеграции. Он функционирует исключительно за счет обработки видеопотока с экрана, аудиодорожки игрока и оперативного поиска информации в сети.
В рамках демонстрации ИИ-помощник успешно координировал действия игрока в режиме реального времени:
- Отслеживание квестов: агент зафиксировал текущие еженедельные задачи (собрать 300 гемов и уничтожить 10 боссов) и напоминал о них по ходу матча.
- Анализ игровой меты: по запросу пользователя ИИ мгновенно проанализировал обсуждения на платформе Reddit и выделил наиболее эффективных персонажей текущего патча (включая Шелли из S-тира, а также Джесси и Ледяного мага из А-тира).
- Тактическое планирование: ИИ рассчитал оптимальный состав армии (8 Гигантов в качестве танков, 6 Магов для уничтожения ключевой обороны, 10–12 Варваров для отвлечения внимания и Стрелки на оставшиеся места).
- Наведение на цель: модель оценила архитектуру вражеской базы и порекомендовала атаковать с южной стороны для прямого выхода на Ратушу.
Уэс Рот отметил, что ранее тестировал десктопное приложение ChatGPT со схожими задачами в игре Factorio. По его оценке, решение от OpenAI показало себя эффективно при ответах на вопросы о горячих клавишах, однако уступало разработке Google, поскольку ChatGPT не мог «видеть» игровой стрим напрямую и требовал больше времени (на пару секунд дольше) на извлечение контекста из памяти. Единственным спорным элементом гейминг-демо от Google ведущий назвал встроенный генератор шуток, посчитав юмор ИИ излишним.
🌐 Project Mariner: автономная автоматизация браузерных задач 16:57
Для корпоративного и повседневного использования Google разрабатывает Project Mariner — исследовательский прототип автономного агента, выполненный в виде экспериментального расширения для браузера Chrome. Его ключевое отличие от простых парсеров заключается в способности имитировать поведение человека: кликать по ссылкам, скроллить страницы, читать информацию и выстраивать цепочки рассуждений.
В первой демонстрации агент автоматизировал рутинную рабочую задачу:
- ИИ считал список названий компаний, занимающихся скалолазанием, из таблицы Google Sheets.
- Автономно ввел поисковый запрос по первой компании (Benchmark climbing) в Google.
- Перешел на официальный сайт организации, нашел контактный email, зафиксировал его в памяти и перешел к следующей строке таблицы.
Второй сценарий задействовал мультимодальное понимание. Пользователь поручил агенту найти самого известного художника-постимпрессиониста, отыскать его яркую картину на платформе Google Arts & Culture, а затем добавить набор подходящих красок в корзину на Etsy. Прототип самостоятельно идентифицировал Ван Гога, зашел на веб-ресурс, проскроллил биографию до галереи работ, выбрал картину «Ирисы», после чего перешел на Etsy, вбил в поиск «яркие краски» и добавил в корзину акварель, ориентируясь на баланс цены и визуальной привлекательности.
Разработчики подчеркивают, что Project Mariner на текущем этапе работает строго в активной вкладке пользователя и не совершает фоновых действий без контроля. Перед финальной оплатой на Etsy агент приостановил работу и запросил подтверждение человека, что отражает концепцию безопасного ИИ «human-in-the-loop» (человек в контуре управления).
🎨 Родная мультимодальность Gemini 2.0 и генерация изображений в рамках диалога 22:14
Важным технологическим прорывом Gemini 2.0 Уэс Рот считает переход на полностью нативную мультимодальность. В отличие от существующих систем, где для распознавания текста, генерации картинок и анализа аудио используются разные состыкованные модели, Gemini 2.0 обрабатывает и выдает текстовые и графические токены в рамках единого унифицированного процесса.
Уэс Рот процитировал известного ИИ-исследователя Андрея Карпати (Andrej Karpathy), который утверждает, что искусственный интеллект вскоре сам станет операционной системой. Пользователям больше не придется вручную кликать мышью или использовать сложные интерфейсы — достаточно будет дать сквозную команду.
Эксперименты в Google AI Studio с моделью Gemini 2.0 Flash продемонстрировали следующие возможности сквозного редактирования:
- Трансформация объектов: по текстовому запросу «преврати эту машину в кабриолет» модель изменила крышу автомобиля на исходной фотографии, сохранив при этом абсолютно неизменным весь остальной фон (деревья, освещение, текстуру дороги), что обычно является проблемой для диффузионных нейросетей.
- Контекстное дополнение: ИИ смог продолжить диалог, одновременно генерируя текст с объяснением концепции и новое изображение машины, «заполненной пляжными вещами» и перекрашенной в летние цвета.
- Визуальное целеуказание: пользователь может просто обвести деталь на картинке (например, дверную ручку автомобиля) и написать «открой это» — Gemini 2.0 поймет пространственный контекст и сгенерирует изображение с открытой дверью.
- Генерация «невидимого» содержимого: получив снимок закрытой картонной коробки с надписью старой электроники на боку, модель смогла логически домыслить и сгенерировать точный ракурс «взгляда внутрь коробки», разложив там старые платы и провода.
🗺️ Мультимодальный Live API и 3D-пространственное мышление 27:14
В заключительной части обзора была продемонстрирована техническая сторона взаимодействия с Gemini 2.0 через Multimodal Live API в интерфейсе AI Studio. Разработчик Google по имени Тина показала приложение Gen Weather, использующее интеграцию с Google Maps API и Open Weather API. Благодаря сверхнизкой задержке (low latency) стримингового API, модель способна мгновенно озвучивать реальные сводки погоды, полностью оставаясь в рамках заданного персонажа — например, циркового зазывалы или калифорнийского серфера.
Параллельно Google развивает функцию пространственного понимания (Spatial Understanding). Экспериментальная модель Gemini 2.0 Flash способна не просто описывать фотографии, а с высокой скоростью выдавать точные координаты объектов.
В ходе тестов пространственного мышления были зафиксированы следующие результаты:
- Определение координат и связей: ИИ безошибочно определил точные границы (bounding boxes) для фигурок оригами на столе, а также логически сопоставил, какая тень принадлежит бумажной лисе, а какая — броненосцу.
- Поиск мелких объектов: модель успешно нашла на зашумленном снимке пару радужных носков, а затем локализовала носки с крошечными, частично смазанными принтами лиц.
- Интеграция с переводом: ИИ смог считать надписи на изображении и разметить объекты текстовыми указателями одновременно на японском и английском языках.
- Решение физических задач: по фотографии пролитой жидкости на столе Gemini 2.0 нашла точное местоположение пятна и указала координатами на лежащее в углу полотенце как на инструмент для уборки.
Главным новшеством разработчики называют появление предварительного 3D-пространственного понимания. С помощью специального Colab-блокнота разработчики могут загрузить обычную плоскую фотографию комнаты, а Gemini 2.0 вычислит расположение мебели в трехмерном пространстве и воссоздаст интерактивный план помещения с видом сверху, фактически превращая снимок в контролируемую 3D-модель.