В классической теории машинного обучения существует догма: чем сложнее модель, тем выше риск переобучения. Однако современная практика глубокого обучения, где нейросети имеют миллиарды параметров, явно противоречит этому правилу. Исследователь ИИ Янник Кильхер (Yannic Kilcher) разбирает фундаментальную работу Михаила Белкина и соавторов, которая примиряет старую теорию с новыми реалиями через концепцию «двойного спуска» (Double Descent).
🧩 Парадокс классического машинного обучения 0:00
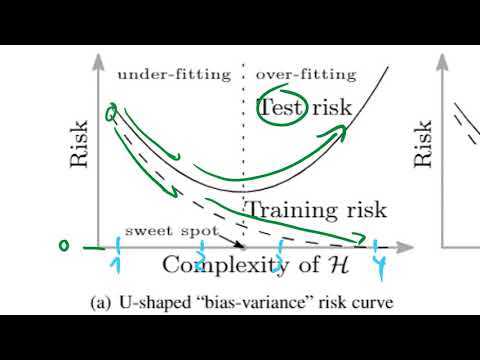
Классическое понимание машинного обучения строится на компромиссе между смещением и дисперсией (bias-variance trade-off) . По словам Янника Кильхера, фундаментальная проблема заключается в том, как мы интерпретируем сложность модели и её способность к обобщению на новых данных .
Для иллюстрации Кильхер приводит пример с аппроксимацией функции по четырем точкам данных:
- Модель с одним параметром: Представляет собой прямую линию, проходящую через начало координат. Она описывает общую тенденцию, но имеет высокое смещение .
- Модель с двумя параметрами: Позволяет добавить смещение (bias term), благодаря чему линия проходит через центр данных более точно .
- Модель с четырьмя параметрами (полином четвертого порядка): В этой точке количество параметров совпадает с количеством точек данных. Модель идеально проходит через все обучающие примеры (нулевая ошибка на обучении) .
Согласно классическим учебникам, именно на этапе совпадения числа параметров и данных возникает критическое переобучение . Функция начинает «осциллировать» (сильно колебаться) между точками, и хотя на тренировочных данных ошибка равна нулю, на новых данных (test set) она становится катастрофически высокой .
📉 График «двойного спуска»: новая реальность 4:54
Главное открытие статьи Белкина, по мнению Янника Кильхера, заключается в том, что классический U-образный график ошибки — это лишь левая часть более сложной кривой . Авторы вводят понятие «порога интерполяции» (interpolation threshold) — это точка, в которой модель становится достаточно мощной, чтобы идеально подогнать (интерполировать) обучающие данные .
Ключевые тезисы концепции Double Descent:
- До порога интерполяции: Ошибка на тесте сначала падает (модель учится), а затем растет (модель начинает переобучаться), достигая пика .
- В точке порога: Модель едва справляется с интерполяцией данных, что приводит к созданию крайне нестабильных и сложных функций с высокой ошибкой на тесте .
- После порога (режим сверхпараметризации): По мере дальнейшего увеличения количества параметров ошибка на тестовых данных снова начинает снижаться .
Янник Кильхер подчеркивает, что этот эффект не вызван регуляризацией — он проявляется как естественное свойство обучения сверхбольших моделей . Более того, регуляризация в этой логике может даже мешать, ограничивая модель в достижении зоны «двойного спуска» .
🔬 Эксперимент со случайными признаками Фурье 7:54
Для доказательства своей гипотезы авторы использовали модель классификатора на основе случайных признаков Фурье (Random Fourier Features, RFF) . Эта модель удобна тем, что позволяет точно контролировать количество параметров.
Механика модели RFF:
- Входные данные $X$ пропускаются через фиксированные случайные векторы $V$ .
- Результат преобразуется экспоненциальной функцией .
- Обучаются только веса финального линейного классификатора поверх этих признаков .
В экспериментах на датасете MNIST исследователи увидели четкое подтверждение теории: ошибка падала, затем резко взлетала в районе 10 000 параметров (что коррелирует с объемом данных) и после этого плавно снижалась . При бесконечном увеличении числа параметров точность модели приближается к пределу, который дает ядерный метод опорных векторов (Kernel SVM) с гауссовым ядром .
🧠 Почему это работает: роль низкой нормы и гладкости 11:50
Янник Кильхер объясняет физику процесса через «норму» решения. В точке порога интерполяции норма весов (их совокупная величина) достигает максимума, что соответствует очень «дерганой» и сложной функции .
Однако в режиме сверхпараметризации происходит следующее:
- У модели появляется избыточное пространство решений, позволяющее идеально подогнать тренировочные данные множеством способов .
- Алгоритмы вроде стохастического градиентного спуска (SGD) обладают встроенным индуктивным смещением — они склонны находить решения с «низкой нормой» .
- Решение с низкой нормой в пространстве параметров соответствует гладкой (smooth) функции в пространстве данных .
Таким образом, сверхбольшая модель не просто запоминает данные, а находит наиболее простую и гладкую кривую, которая проходит через все точки . Эта гладкость и обеспечивает хорошую обобщающую способность на новых примерах .
🌲 Подтверждение на нейросетях и случайных лесах 15:49
Феномен двойного спуска оказался универсальным. Авторы продемонстрировали его на различных архитектурах:
- Нейронные сети: Однослойная сеть на MNIST показала аналогичный всплеск ошибки на пороге интерполяции и последующее улучшение при росте скрытого слоя .
- Деревья решений и случайные леса: Тот же эффект наблюдается при увеличении сложности деревьев до состояния полной интерполяции обучающей выборки .
Янник Кильхер отмечает, что работа дает новый взгляд на то, почему современные гигантские модели работают так хорошо . Ранее этот эффект не замечали по двум причинам:
- Исследователи классических методов обычно работали в режиме недообучения или небольшой перегрузки, не заходя далеко за порог интерполяции .
- В глубоком обучении инженеры сразу строят настолько огромные сети, что они оказываются далеко в «правой части» графика. Пик ошибки в таком случае просто пролетают мимо, видя только постоянное улучшение результатов при росте модели .




