В новом видео Уэс Рот (Wes Roth) анализирует научную работу «Agents of Change», посвященную созданию самосовершенствующегося ИИ-агента для игры в «Колонизаторы» (Settlers of Catan). Автор рассматривает, как архитектура на базе больших языковых моделей (LLM) позволяет ИИ самостоятельно переписывать свой код и промпты, достигая значительных успехов в сложной стратегической среде с элементами неопределенности.
🏗️ Что такое ИИ-агенты и зачем им «строительные леса» 0:00
Уэс Рот начинает с обсуждения терминологии, отмечая, что термин «ИИ-агенты» (AI agents) может быть не самым удачным, но на данный момент он является общепринятым . По словам ведущего, современные агенты строятся на базе больших языковых моделей с использованием так называемого «скаффолдинга» (scaffolding) — программной обвязки или архитектуры, которая позволяет модели писать код, вести заметки и использовать внешние инструменты .
Этот подход уже доказал свою эффективность в ряде знаковых проектов:
- Alpha Evolve от Google DeepMind.
- Darwin Goal machine — самосовершенствующийся агент для написания кода .
- Voyager от Nvidia — агент, который учился играть в Minecraft, самостоятельно создавая библиотеку навыков на JavaScript .
Рот подчеркивает, что «скаффолдинг» — это инструменты, документация и возможности, которые мы даем модели, чтобы она понимала свою задачу и могла улучшать собственные действия .
🎲 «Колонизаторы» как испытание для стратегического мышления 1:17
Выбор игры Settlers of Catan (в России известна как «Колонизаторы») для тестирования ИИ не случаен. По мнению Рота, это сложная игра, сочетающая в себе математику, стратегию и ведение переговоров .
Ведущий выделяет ключевые отличия этой среды от классических шахмат или го:
- Тип информации: Шахматы и го — игры с полной информацией, где все состояние доски известно. В «Колонизаторах» присутствует частичная наблюдаемость и элементы случайности (броски кубиков) .
- Долгосрочная когерентность: Одной из главных проблем современных LLM является неспособность придерживаться долгосрочных стратегий. Они могут быть эффективны на старте, но со временем «теряют нить повествования» .
- Динамика: Агентам необходимо постоянно адаптироваться к действиям оппонентов и меняющимся ресурсам .
Для симуляции игры исследователи использовали Katanatron — открытый фреймворк на языке Python, позволяющий быстро прогонять игровые партии с участием ботов .
🤖 Архитектура «Agents of Change»: четыре роли одного ИИ 7:11
В обсуждаемой работе представлена многоагентная структура, где за разные аспекты самосовершенствования отвечают специализированные роли . Уэс Рот детально разбирает, как функционирует этот «рецепт» эффективного агента:
- Analyzer (Анализатор): Оценивает игровой процесс, выявляет слабые места и готовит отчеты для улучшения стратегии .
- Researcher (Исследователь): Самый интересный, по мнению Рота, компонент. Этот агент делает поисковые запросы в сети (например, на Reddit), чтобы найти лучшие человеческие стратегии для «Колонизаторов» .
- Coder (Кодировщик): Получает предложения по изменениям и переводит их в конкретный программный код, обновляя логику игрока .
- Player (Игрок): Непосредственно участвует в матче, используя текущую версию кода и промптов .
Важным элементом успеха системы ведущий считает постоянное напоминание модели о состоянии игрового поля в каждом промпте. По его словам, проекты вроде Vending Bench проваливались именно из-за того, что ИИ со временем забывал контекст, в то время как напоминания (как в Voyager) позволяют сохранять концентрацию на задаче .
💻 Технические детали и ход эксперимента 11:58
Исследование примечательно тем, что оно доступно для воспроизведения. Сбор данных осуществлялся на стандартном оборудовании:
- MacBook Pro 2019 (16 ГБ ОЗУ).
- MacBook M1 Max 2021 (32 ГБ ОЗУ).
- Общее время экспериментов составило около 60 часов .
Для тестирования были выбраны три модели: GPT-4o, Claude 3.7 и Mistral Large (открытая модель через API) . В качестве базового противника использовался классический алгоритм Alpha-Beta Search — сильный логический бот, не использующий нейросети . Чтобы результаты были сопоставимыми, исследователи фиксировали «сиды» (random seeds) для генерации игровых полей .
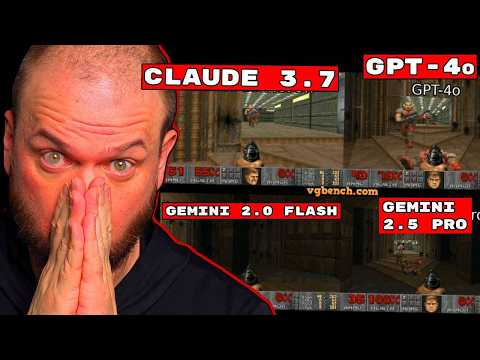
📈 Результаты: триумф Claude 3.7 и провал Mistral 13:30
Результаты эксперимента наглядно показали, что успех самосовершенствования критически зависит от качества базовой языковой модели .
Основные показатели прогресса (улучшение относительно базового агента):
- Claude 3.7 Sonnet: Показала феноменальный результат, достигнув 95% улучшения при использовании эволюции промптов . Модель смогла разработать детальные планы по размещению поселений и расстановке приоритетов в ресурсах .
- GPT-4o: Продемонстрировала умеренный прогресс — около 36% улучшения в архитектуре Agent Evolver .
- Mistral Large: Оказалась наименее эффективной, показав падение производительности на 31% в некоторых тестах .
Уэс Рот отмечает, что процесс улучшения не останавливался даже к 10-й итерации эволюции, хотя основной рывок происходил в районе 7-го шага . По мнению автора, если бы у исследователей было больше вычислительных ресурсов и времени, результаты могли быть еще более впечатляющими .
🔮 Будущее самообучающегося ИИ 15:34
Завершая обзор, Уэс Рот цитирует Сэма Альтмана: предпринимателям стоит строить бизнес так, чтобы он становился лучше автоматически по мере совершенствования базовых ИИ-моделей . Проект «Agents of Change» является практическим подтверждением этого тезиса.
Ведущий делает следующие выводы:
- Рекурсивное самосовершенствование: Мы видим работающий рецепт создания систем, которые автономно диагностируют свои ошибки и исправляют их .
- Доступность: Эксперименты такого уровня сложности теперь можно проводить на домашнем ноутбуке за считанные дни .
- Игры как полигон: Использование сложных настольных игр позволяет тестировать навыки планирования и теории игр, которые напрямую применимы в бизнесе и программировании .
По словам Рота, мы живем в «захватывающее время», когда ИИ начинает не просто выполнять команды, а самостоятельно искать пути к совершенству .