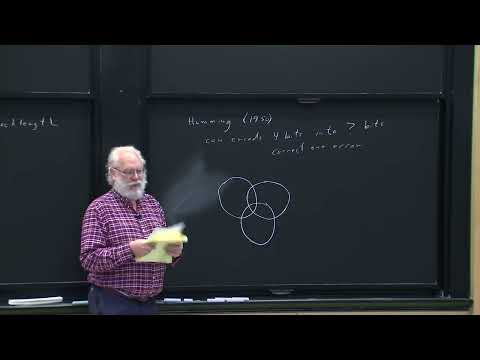
Искусство исправления: как работают коды Хэмминга 0:00
Теория кодирования — это фундамент надежной передачи данных в условиях шума. В лекции MIT OpenCourseWare профессор Питер Шор объясняет, как линейные коды, и в частности коды Хэмминга, позволяют обнаруживать и исправлять ошибки, возникающие при передаче сообщений через ненадежные каналы.
Теорема Шеннона и проблема поиска 0:28
В 1948 году Клод Шеннон доказал фундаментальную теорему о кодировании для каналов с шумом. Суть идеи заключается в следующем: если скорость передачи данных (отношение количества информационных бит $k$ к общему числу переданных бит $n$) меньше пропускной способности канала, то при увеличении длины блока $n$ вероятность ошибки стремится к нулю.
Однако реализация этого на практике сталкивается с трудностями:
- Для доказательства теоремы Шеннон использовал случайные коды.
- Поиск ближайшего кодового слова в случайном коде является NP-трудной задачей.
- Перебор всех возможных вариантов становится вычислительно невозможным при больших значениях $n$.
По словам профессора Шора, для практических систем необходимы специфические коды с эффективными алгоритмами декодирования, которыми и являются линейные коды.
Рождение кодов Хэмминга 6:23
Ричард Хэмминг в 1950 году разработал первый класс кодов, способных исправлять ошибки. Простейший из них кодирует 4 информационных бита в 7 бит, что позволяет исправить одну ошибку.
Механизм работы можно представить через диаграмму Венна:
- Сообщение из четырех бит ($a, b, c, d$) дополняется тремя проверочными битами четности.
- Эти биты размещаются в пересечениях кругов так, чтобы сумма в каждом круге (по модулю 2, через операцию XOR) была четной.
- Если при передаче происходит ошибка в одном бите, соответствующие круги будут показывать «нечетную» сумму, что позволяет однозначно вычислить позицию поврежденного бита.
Математика линейных кодов 15:31
Линейный код над полем $F$ — это совокупность строк, где любая линейная комбинация кодовых слов также является кодовым словом. Каждый такой код имеет:
- Генерирующую матрицу $G$: кодовое слово $c$ получается умножением сообщения $m$ на эту матрицу ($c = m \times G$).
- Минимальное расстояние $d$: минимальное количество позиций, в которых отличаются два различных кодовых слова.
Как отмечает профессор Шор, код способен исправить $t = \lfloor(d-1)/2\rfloor$ ошибок. Для линейных кодов расстояние $d$ совпадает с минимальным весом (количеством ненулевых элементов) любого ненулевого кодового слова.
Синдромное декодирование 1:02:02
Для автоматизации исправления ошибок используется проверочная матрица $H$, для которой выполняется условие $G \times H = 0$. Процесс декодирования выглядит так:
- При получении слова $c_{tilde}$ вычисляется синдром: $S = c_{tilde} \times H$.
- Если ошибка $e$ имела вес 1, то синдром равен соответствующему столбцу или строке матрицы $H$, что позволяет мгновенно локализовать сбой.
- Это делает алгоритм чрезвычайно эффективным для кодов Хэмминга, так как расчет синдрома не зависит от исходного сообщения.
Совершенные коды и код Голея 1:10:27
Совершенный код — это код, в котором все возможные синдромы однозначно соответствуют ошибкам веса $t$ или меньше. Коды Хэмминга являются совершенными.
Помимо них, существует лишь один другой класс бинарных совершенных кодов — код Голея (с длиной блока $n=23$ и $t=3$). Интересно, что, по словам Шора, этот код был обнаружен энтузиастом футбольных ставок, а позже математически связан с теорией конечных простых групп. Несмотря на свою элегантность, совершенных кодов в природе крайне мало, поэтому инженерам приходится использовать и другие подходы, такие как коды Рида — Соломона.




