Обучение представлениям: От сжатия данных к предсказанию будущего 0:00
Обучение представлениям (representation learning) представляет собой фундаментальный сдвиг в методологии глубокого обучения, где целью становится не просто аппроксимация функций, а формирование абстрактных, информативных «внутренних моделей» данных. В рамках лекции MIT OpenCourseWare Филип Изола рассматривает, как глубокие нейронные сети превращают сырые входные данные в структурированные векторы (эмбеддинги), и почему этот процесс становится основой современного искусственного интеллекта.
🎯 Концепция обучения представлениям 1:08
В основе обучения представлениям лежит идея того, что нейронная сеть послойно преобразует входные данные $x$ в более абстрактные формы $f(x)$, которые облегчают решение последующих задач.
- Кодирование (Encoding): Процесс преобразования сырых данных в компактные, семантически насыщенные векторы.
- Генеративное моделирование (Generative modeling): Инверсия кодирования — восстановление данных из абстрактных латентных переменных, что станет темой будущих занятий.
- X2Vec: Общий принцип перехода от данных любого типа (текст, изображения, звук, молекулы) к векторному представлению.
По мнению Изолы, популярная концепция «нейросети как чистого листа» (blank slate) является заблуждением. Современный подход заключается в предварительном обучении (pre-training) на колоссальных массивах данных для создания надежных репрезентаций, которые затем можно адаптировать под узкие задачи с минимумом усилий.
🧠 Анатомия нейросетей и их визуализация 6:24
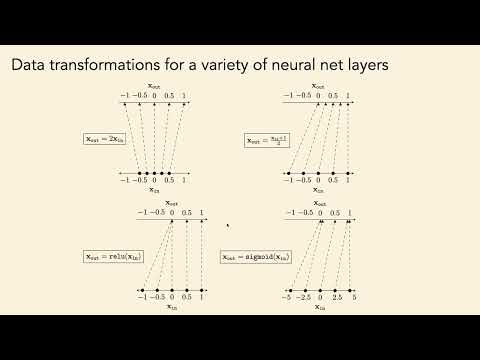
Изола предлагает взглянуть на функции нейронных слоев как на геометрические трансформации распределения данных:
- Linear: Аффинное преобразование, вращение и масштабирование пространства.
- ReLU: Вносит разреженность (sparsity), отображая отрицательные значения в ноль, что «схлопывает» пространство.
- L2 Norm / LayerNorm: Отображают данные на поверхность гиперсферы, обеспечивая стабильность числовых значений.
- Softmax: Приводит данные к симплексу, где значения суммируются в 1, что интерпретируется как вероятность принадлежности к классу.
Визуализация глубоких нейросетей (например, CLIP) показывает, как послойно происходит «разпутывание» (disentangling) сложных данных, пока семантика не становится линейно разделимой.
🔍 Интерпретируемость: Что находят нейроны? 21:28
Исследование внутренних состояний сетей (mechanistic interpretability) подтверждает, что глубокие модели во многом копируют принципы работы зрительной коры приматов:
- Первые слои: Детектируют простые признаки, такие как ориентированные края (edge detectors).
- Промежуточные слои: Сочетания признаков, распознавание геометрических примитивов (круги, пересечения).
- Глубокие слои: Распознавание сложных объектов, таких как лица людей или морды собак.
💾 Автокодировщики и сжатие 45:05
Автокодировщики — это «краеугольный камень» обучения представлениям. Они стремятся минимизировать ошибку реконструкции, пропуская данные через «узкое горлышко» (bottleneck) пониженной размерности.
- Связь с PCA: Линейный автокодировщик математически эквивалентен методу главных компонент (PCA). По сути, глубокий автокодировщик — это нелинейное обобщение PCA.
- Векторное квантование (VQ): Глубокая версия метода k-means, где кодировщик выдает не вектор, а «индекс» кластера.
🚀 Самообучение через предсказание (Self-Supervised Learning)
Сегодня наиболее эффективным подходом признано самообучение (self-supervised learning). Вместо меток, созданных человеком, сеть использует фрагменты самих данных для обучения:
- Претекст-задачи: Предсказание цвета (по ч/б изображению), заполнение пропущенных фрагментов (BERT, Masked Autoencoders), предсказание следующего слова или кадра.
- Эмпирическое превосходство: Маскированное предсказание (masked prediction) стабильно дает лучшие семантические представления, чем обычное автокодирование, что до сих пор остается предметом научных дискуссий и активных исследований.
Филип Изола завершает лекцию метафорой Яна Лекуна: «Представление мира — это основа интеллекта (весь «торт»), тогда как конкретные задачи обучения — лишь вишенка на нем».



