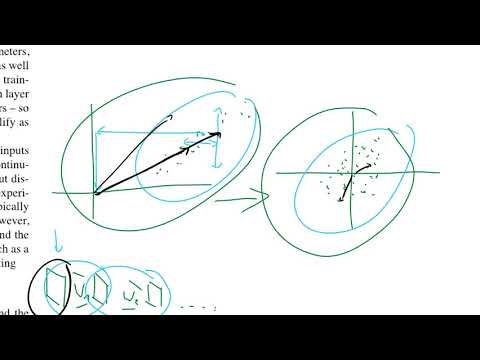
Известный исследователь искусственного интеллекта Янник Килхер разбирает классическую научную работу 2015 года «Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift», авторами которой являются Сергей Иоффе и Кристиан Сегеди. Этот материал посвящен детальному анализу механики пакетной нормализации — технологии, которую сегодня большинство разработчиков интегрируют в архитектуры нейросетей по умолчанию. По мнению ведущего, несмотря на повсеместное использование, реальные принципы работы этого слоя часто остаются неверно понятыми, хотя именно они обеспечивают колоссальное ускорение сходимости моделей.
🔍 Скрытая проблема глубоких сетей и концепция «отбеливания» 0:00
В начале своего обзора Янник Килхер с иронией отмечает, что правильное произношение фамилий авторов статьи — задача не из простых, но сама публикация, несмотря на свой возраст, остается фундаментальной. В современной практике машинного обучения разработчики зачастую бездумно добавляют слои пакетной нормализации (Batch Normalization) в архитектуры, не до конца осознавая их внутреннее назначение.
Классическая многослойная нейросеть представляет собой последовательную композицию функций. Например, в простейшей двухслойной архитектуре функция потерь зависит от параметров первого слоя $\theta_1$ и второго слоя $\theta_2$. Процесс можно описать следующим образом:
- На вход подается исходный вектор данных, например, изображение.
- Данные проходят через первый слой, умножаясь на матрицу весов $W_1$, и преобразуются в промежуточное скрытое представление $H_1$.
- Полученное представление $H_1$ передается на следующий слой с весами $W_2$, превращаясь в $H_2$, и так далее.
С концептуальной точки зрения каждый отдельный слой глубокой сети можно рассматривать как изолированную систему машинного обучения, которая принимает на вход данные и пытается построить их эффективное преобразование.
В традиционном анализе данных перед началом обучения применяется процедура «отбеливания» (whitening). Представим двумерное облако точек, сильно вытянутое вдоль одной из осей, для которого нужно построить линейную регрессию. Если работать с исходным распределением, то вычисление скалярных произведений векторов всегда будет давать огромные значения, что усложнит сходимость классификатора. Процедура отбеливания решает эту проблему за счет двух шагов:
- Нахождение математического ожидания (среднего значения) распределения и его вычитание для центрирования данных.
- Деление полученного результата на стандартное отклонение по каждому направлению для масштабирования.
В результате облако данных становится сферическим и центрируется в начале координат, что существенно облегчает алгоритмам поиск оптимального решения.
Янник Килхер объясняет логику авторов статьи: если каждый слой нейросети по сути является самостоятельным методом обучения, почему бы не проводить такое «отбеливание» для каждого промежуточного слоя, а не только на самом входе системы? Однако наивный перенос этой концепции внутрь сети приводит к генерации артефактов обучения, поскольку процесс нормализации должен быть неразрывно связан с изменением весов.
🧮 Математика пакетной нормализации: среднее, дисперсия и предотвращение ошибок 5:10
Для решения проблемы авторы предлагают использовать так называемую нормализацию на основе статистики мини-батчей. Вместо анализа всего датасета вычисления производятся независимо для каждого измерения $D$-мерного входного вектора $X$ в рамках текущего пакета данных.
Алгоритм вычисления трансформации в рамках одного мини-батча, размер которого обычно составляет, например, 32 или 100 объектов, выглядит следующим образом:
- Вычисляется эмпирическое среднее значение мини-батча $\mu_B$ для конкретного слоя.
- Рассчитывается эмпирическая дисперсия мини-батча $\sigma_B^2$.
- Производится преобразование элементов: из каждого значения вычитается среднее, а результат делится на корень из дисперсии.
При делении к значению дисперсии обязательно добавляется небольшая константа $\epsilon$ (эпсилон). По словам ведущего, этот параметр необходим исключительно для предотвращения числовых ошибок и исключения деления на ноль, если дисперсия окажется слишком малой. Данная математическая операция переводит данные в стандартизированный вид, аналогичный входному отбеливанию.
⚙️ Параметры Gamma и Beta: как вернуть гибкость распределению 7:31
Прямая нормализация скрытых слоев таит в себе опасность: она лишает сеть возможности осуществлять тождественное преобразование (identity transform), которое является базовым сценарием, когда слою выгодно передать данные дальше без изменений. Тождественное преобразование при чистой нормализации возможно только в идеальном случае, если среднее изначально равно нулю, а дисперсия — единице.
Чтобы вернуть архитектуре выразительную способность, авторы вводят два новых обучаемых параметра для каждого измерения скрытого представления:
- Скалярный множитель $\gamma$ (гамма), отвечающий за масштабирование распределения.
- Скалярное слагаемое $\beta$ (бета), отвечающее за сдвиг распределения.
После этапа жесткой нормализации стандартизированное значение умножается на $\gamma$, а затем к нему прибавляется $\beta$. Сеть фактически обучается оптимальным образом сдвигать и масштабировать свои активации.
По мнению Янника Килхера, такой подход может показаться избыточным: сначала мы центрируем данные, а затем позволяем сети снова смещать их. Однако это невероятно мощный инструмент. Если алгоритм обратного распространения ошибки решит, что исходное ненормализованное распределение было более полезным для решения задачи, параметры $\gamma$ и $\beta$ позволят полностью или частично вернуться к нему, либо трансформировать распределение в любую другую форму.
Данное нововведение имеет важное практическое следствие для проектирования архитектур. Обучаемый параметр $\beta$ выполняет ту же функцию, что и традиционный параметр смещения (bias) в полносвязных или сверточных слоях. Из-за этого, если слой пакетной нормализации размещается сразу после сверточного или полносвязного слоя, рассчитывать стандартный bias становится бессмысленно. Полносвязный или сверточный слой в таком случае настраивается без использования смещения, что экономит вычислительные ресурсы.
📉 Проблема детерминизма на этапе тестирования 12:01
Внедрение пакетной нормализации порождает серьезную проблему: сеть теряет способность к детерминированному выходу на этапе тестирования (inference). Механика Batch Norm во многом напоминает слой Dropout — в обоих случаях поведение сети начинает зависеть от случайных факторов. В случае с Batch Norm значение выхода для конкретного примера зависит не только от него самого, но и от того, какие еще объекты случайным образом попали вместе с ним в текущий мини-батч.
Для восстановления воспроизводимости результатов авторы применили изящный математический трюк:
- В процессе обучения модели система непрерывно рассчитывает и сохраняет скользящее среднее (running average) для математического ожидания и дисперсии по всем батчам.
- На этапе тестирования, когда мини-батчей больше нет и объекты могут поступать поодиночке, случайные значения батч-статистик заменяются на эти накопленные глобальные скользящие средние.
Янник Килхер подчеркивает, что современные библиотеки глубокого обучения автоматически управляют этим процессом с помощью переключения режимов работы слоя (train mode / test mode). Разработчику критически важно следить за корректной установкой флагов режима, иначе Batch Norm начнет использовать неверные статистики, что полностью разрушит логику работы модели.
🔄 Обратное распространение ошибки через Batch Norm 14:09
Поскольку слой нормализации интегрирован непосредственно внутрь сети, критически важно гарантировать возможность вычисления градиентов на каждом этапе. Янник Килхер подробно визуализирует вычислительный граф процесса, чтобы продемонстрировать полную дифференцируемость алгоритма.
Градиент функции потерь поступает на выход слоя $Y_i$. Вычисление производных для параметров $\gamma$ и $\beta$ является относительно простой задачей, так как пути градиента от них ведут напрямую к выходу. Сложнее обстоит дело с вычислением производной по входному значению $X_i$, поскольку граф содержит три разветвляющихся пути:
- Прямой путь от нормализованного значения $\hat{X}$ обратно к $X_i$.
- Путь через вычисленное эмпирическое среднее $\mu_B$.
- Путь через вычисленную эмпирическую дисперсию $\sigma_B^2$.
Для корректного вычисления итогового градиента алгоритм обратного распространения ошибки должен рассчитать производные по всем промежуточным узлам, включая дисперсию и среднее, и просуммировать вклады от всех трех путей, выходящих из точки $X_i$. Суммирование градиентов обусловлено стандартным правилом дифференцирования многопутевых графов. Тот факт, что вся цепочка операций является строго дифференцируемой, позволяет без проблем обучать глубокие сети сквозным методом (end-to-end) с использованием градиентного спуска.
🚀 Результаты: ускорение обучения и преодоление внутреннего ковариационного сдвига 23:25
Рассматривая результаты экспериментов, Килхер напоминает, что статья была опубликована в 2015 году, когда размеры нейросетей и наши знания об их оптимизации были значительно скромнее текущих стандартов. Тем не менее, авторам удалось наглядно доказать, что модели с пакетной нормализацией достигают аналогичных показателей точности за радикально меньшее количество шагов оптимизации.
В отсутствие Batch Norm графики активации слоев на начальных этапах демонстрируют колоссальные флуктуации. Причина кроется в феномене внутреннего ковариационного сдвига (internal covariate shift):
- Когда в процессе обучения меняются веса первого слоя $W_1$, это полностью сдвигает распределение данных, поступающих на последующие слои.
- В результате веса более глубоких слоев, например, $W_3$, которые только что адаптировались под определенный характер входов, мгновенно оказываются устаревшими.
- Слоям приходится заново переобучаться под изменившееся распределение, что резко замедляет сходимость всей системы.
Слой Batch Norm полностью ликвидирует эту проблему, стабилизируя распределение на каждом этапе и позволяя исследователям использовать кратно более высокие скорости обучения (learning rates) без риска взрыва или затухания градиентов. В завершение обзора Янник Килхер делится важным практическим наблюдением: несмотря на доказанную эффективность, на практике пакетная нормализация иногда по непонятным причинам может не давать ожидаемого результата, поэтому её окончательное внедрение всегда остается вопросом живого эксперимента.




