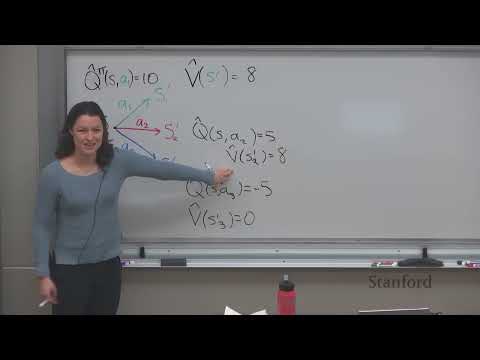Методы автономного обучения с подкреплением: От имитации к оптимизации 7:44
Автономное обучение с подкреплением (Offline RL) — это область машинного обучения, где агент учится принимать решения на основе заранее собранного набора данных, не имея возможности взаимодействовать с внешней средой в процессе обучения. В отличие от классического обучения с подкреплением (Online RL), где агент непрерывно собирает данные, «автономный» подход позволяет эффективно использовать существующие архивы опыта, что критически важно в сферах, где сбор новых данных дорог или небезопасен, таких как управление автомобилем или медицинские протоколы лечения.
⚖️ Основная проблема: Сдвиг распределения 17:34
Ключевой вызов в Offline RL связан со «сдвигом распределения» (distribution shift). В процессе обучения алгоритм стремится оптимизировать политику, отличающуюся от той (поведенческой политики, или $\pi_\beta$), которая собирала данные.
- Риск переоценки: При использовании стандартных методов (например, Soft Actor-Critic) агент может выбирать действия, отсутствующие в исходном наборе данных. Если для таких «невиданных» действий Q-функция инициализирована случайно, агент может ошибочно счесть их высокоэффективными, что ведет к катастрофическим результатам.
- Ограничение поддержки: Чтобы избежать ошибок, алгоритмы Offline RL должны ограничивать отклонение обучаемой политики от поведенческой, оставаясь в рамках известных данных.
🛠 Базовые подходы к обучению 26:39
Имитационное обучение (Imitation Learning) является простейшим решением, так как оно использует только те действия, которые уже представлены в данных. Однако оно не позволяет превзойти «эксперта», чьи данные были собраны. Более совершенные методы Offline RL способны «сшивать» (stitch) фрагменты различных траекторий, объединяя успешные участки из разных попыток для формирования оптимальной стратегии.
Advantage Weighted Regression (AWR) 44:11
Одним из наиболее эффективных и простых методов является Advantage Weighted Regression. Алгоритм работает в два этапа:
- Оценка функции ценности: Сначала обучается Value-функция с помощью регрессии методом Монте-Карло на сумму будущих вознаграждений.
- Взвешенное обучение политики: Политика обучается максимизировать вероятность действий, взвешенную по экспоненциальным значениям функции преимущества (advantage).
Этот подход позволяет неявно принуждать агента выбирать действия с высоким преимуществом, избегая при этом запросов к действиям вне набора данных, что обеспечивает стабильность обучения.
🧠 Продвинутая оптимизация: Implicit Q-Learning (IQL)
Для задач, где требуется более высокая точность, используется Implicit Q-Learning (IQL). Метод заменяет стандартную среднеквадратичную ошибку (MSE) на асимметричную функцию потерь (expected regression), что позволяет целенаправленно оценивать значение политики, превосходящей по качеству исходную поведенческую политику.
- Преимущества IQL:
- Отсутствие необходимости запрашивать действия вне распределения данных (out-of-distribution).
- Разделение процессов обучения актора и критика.
- Высокая эффективность при сочетании автономного предварительного обучения (pre-training) с последующей донастройкой (fine-tuning) в режиме реального времени.