В новом обзоре популярный исследователь машинного обучения Янник Килхер (Yannic Kilcher) разбирает свежую научную работу, авторы которой задались амбициозным вопросом: можно ли создать сильную генеративно-состязательную сеть (GAN) полностью без использования сверток? Рассматриваемая архитектура под названием TransGAN доказывает, что синергия двух трансформеров способна составить реальную конкуренцию классическим сверточным моделям. Килхер подробно анализирует устройство генератора, дискриминатора и три ключевые технические уловки, которые заставили эту систему работать.
🤖 Рождение TransGAN и особенности нейминга 0:00
До недавнего времени механизмы внимания и трансформерные блоки использовались в генеративно-состязательных сетях лишь как вспомогательные элементы, встроенные в традиционные сверточные архитектуры. Однако авторы рассматриваемой работы (Yifan Jiang, Chang availed, Changyang Wang) предприняли попытку построить генератор и дискриминатор исключительно на базе трансформеров. Созданная ими модель получила название TransGAN.
Янник Килхер с присущим ему юмором ирония по поводу названия, отмечая, что словосочетание «TransGAN» (созвучное с транс-сообществом) заставляет задуматься, в какой именно туалет должна ходить эта нейросеть. Тем не менее, если отбросить шутки, перед нами серьезное исследование, код которого уже выложен в открытый доступ. По словам Килхера, ключевой вопрос публикации формулируется предельно просто: способны ли мы построить мощную GAN-сеть, полностью свободную от сверточных слоев? В качестве основного полигона для испытаний разработчики выбрали датасет CelebA с разрешением изображений 64x64 пикселя, хотя заложенные метрики указывают на отличный потенциал масштабирования.
Авторы выделяют три главных вклада своего исследования:
- Разработка уникальной архитектуры модели (дискриминатор на базе ViT и генератор с прогрессивным апсемплингом).
- Создание специфической методики обучения, включающей три обязательных компонента (аугментация, вспомогательное обучение и локальная инициализация).
- Достижение конкурентоспособных результатов (метрики FID и Inception Score), позволяющих соперничать со state-of-the-art решениями.
🔍 Дискриминатор: картинка как набор слов 3:12
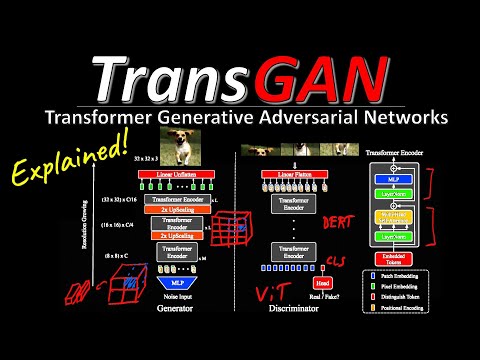
Концепция дискриминатора в TransGAN целиком позаимствована из знаменитой архитектуры Vision Transformer (ViT), описанной в статье «Картинка стоит 16x16 слов». На вход дискриминатора поступают как реальные изображения из датасета, так и фейковые изображения, созданные генератором.
Процесс обработки картинки (например, изображения собаки) выглядит следующим образом:
- Изображение разбивается на так называемые «суперпиксели» — небольшие квадратные патчи.
- Каждый патч «разворачивается» с помощью операции flattening в один длинный вектор.
- Полученные векторы интерпретируются нейросетью точно так же, как эмбеддинги слов в обычном текстовом предложении.
После этого к цепочке векторов применяется стандартный трансформерный энкодер, архитектурно похожий на модель BERT. Поскольку в трансформерах, в отличие от сверточных сетей, изначально отсутствует понимание пространственного расположения элементов (это сет-трансформация, а не последовательная структура), авторам приходится принудительно добавлять позиционное кодирование (positional encodings). В финале сети используется специальный [CLS]-токен, который и выносит вердикт: является ли изображение подлинным или его сгенерировала машина.
🧱 Генератор и борьба за память: прогрессивный Pixel Shuffle 5:53
Проектирование генератора оказалось более сложной задачей. Прямолинейный подход — попытаться предсказать независимые патчи картинки в обратном порядке — по мнению Килхера, обречен на провал, так как границы соседних патчей никогда не совпадут идеально. Для дискриминатора это не критично, ведь его цель — классификация, а не синтез. Но генератор обязан выдать бесшовную картинку целевого размера.
Главный враг трансформеров при работе с графикой — колоссальное потребление памяти и вычислительных ресурсов. Механизм self-attention связывает каждый токен со всеми остальными. Если пытаться связать каждый пиксель высокого разрешения со всеми остальными на протяжении множества слоев, то из-за квадратичной сложности $\mathcal{O}(N^2)$ система мгновенно исчерпает доступную память.
Чтобы обойти это ограничение, создатели TransGAN внедрили архитектуру прогрессивного апсемплинга (увеличения масштаба):
- Входной вектор шума проходит через небольшой многослойный перцептрон (MLP), формируя начальную сетку размером всего 8x8 пикселей со множеством каналов информации.
- Эта сетка разворачивается в последовательность из 64 токенов (если проводить аналогию с текстом — в предложение из 64 слов) и подается в трансформер.
- Пройдя $M$ слоев трансформера, данные подвергаются апсемплингу: разрешение сетки удваивается (например, становится 16x16, а затем 32x32), но количество каналов пропорционально уменьшается.
Для апсемплинга используется алгоритм Pixel Shuffle. Изначально созданный для сверточных сетей, он позволяет перегруппировать каналы низкого разрешения в пиксели более высокого разрешения. Каждый раз, когда пространственное разрешение увеличивается в 2 раза по ширине и высоте, глубина каналов сокращается в 4 раза. В самом конце цепочки линейная проекция переводит оставшиеся каналы в финальные три цветовых канала (RGB). Подобный компромисс между плотностью пикселей и глубиной информации позволяет удерживать требования к памяти в разумных пределах.
🛠 Три трюка обучения: как заставить трансформеры генерировать 16:45
Эмпирические тесты авторов показали, что если замена генератора на трансформер проходит гладко, то одновременный перевод дискриминатора на трансформерную основу приводит к резкому падению качества генерации. Чтобы стабилизировать обучение и обойти эту проблему, исследователям пришлось прибегнуть к трем важным технологическим хитростям.
Первым спасительным кругом стала дифференцируемая аугментация данных (DiffAugment). Трансформеры лишены «врожденного» индуктивного смещения локальности (locality bias), присущего сверткам, и поэтому требуют колоссальных объемов данных. DiffAugment применяет к картинкам случайные трансформации (кадрирование, изменение яркости, поворот), но делает это через дифференцируемые функции. Это позволяет пропускать градиент обратно через функцию аугментации во время обновления генератора. Как наглядно демонстрируют графики из статьи, добавление DiffAugment драматически улучшает результаты TransGAN, переводя модель в высшую лигу.
🎯 Совместное обучение и «локальные» трансформеры против сверток 19:10
Второй трюк — введение вспомогательной self-supervised задачи для генератора, а именно задачи супер-разрешения (Super Resolution). Помимо классического состязательного процесса, в батчи подмешивают особые задания:
- Берутся реальные изображения из датасета и намеренно уменьшаются в качестве (даунсемплинг).
- Полученная низкоразрешенная картинка подается на вход генератору (что нетипично, ведь обычно генератор видит только случайный шум).
- Задача генератора — восстановить исходное изображение в высоком качестве, сравнивая результат с оригиналом через дополнительный лосс.
Третий, наиболее ироничный трюк — локально-зависимая инициализация self-attention (Locality-Aware Initialization). Поскольку сверточный приор (идея о том, что пиксели рядом важнее пикселей на другом конце экрана) доказал свою эффективность в CNN, авторы решили временно сымитировать его внутри трансформера. На ранних этапах обучения вводится специальная маска, запрещающая токенам «смотреть» куда-либо, кроме своих ближайших соседей. По ходу обучения маска постепенно уменьшается, расширяя поле зрения трансформера, пока в финале attention не становится полностью глобальным.
Янник Килхер откровенно высмеивает этот компромисс:
Мы заявляем, что строим GAN абсолютно без сверток, заменяя их линейной операцией, которая применяется ко всему изображению, но при этом заставляем её смотреть только на соседние пиксели! Потрясающе, свертки — для лузеров, мы за локально применяемые линейные трансформации.
Тем не менее Килхер признает эффективность подхода, хотя и предполагает, что вместо жесткого фиксированного расписания маски было бы умнее настроить адаптивную систему (например, в виде игры двух агентов), исключающую лишние гиперпараметры.
📈 Масштабирование до XL и возвращение к истокам 27:28
Финальным аккордом исследования стало классическое для эпохи трансформеров масштабирование: авторы просто увеличили количество слоев и размерность признаков, создав модель TransGAN-XL.
Результаты оказались впечатляющими. На датасете CIFAR-10 модель уступила лишь признанному титану сверточной генерации в лице StyleGAN v2. А на датасете STL-10 трансформерная архитектура и вовсе установила новый рекорд (state-of-the-art), обогнав все существовавшие сверточные аналоги.
В заключение Янник Килхер отмечает, что ему было приятно увидеть качественную работу, оперирующую «ностальгическими» разрешениями вроде 64x64 пикселя, на которых когда-то и зарождалась индустрия генеративных сетей. Авторам удалось доказать, что чистые трансформеры жизнеспособны в сфере генерации изображений, если правильно компенсировать отсутствие сверточных приоров продуманными трюками при обучении.