«Картинка стоит 16x16 слов» — этот парафраз классической пословицы лег в основу архитектуры Vision Transformer, превратившей визуальные образы в понятный машинам цифровой континуум. Пока индустрия подсаживается на масштабирование как на «чертовски сильный наркотик», ведущие инженеры пытаются понять, почему нейросети с миллиардами параметров все еще пасуют перед задачами, которые человек решает в мгновение ока. Путь от простых классификаторов к нативному мультимодальному интеллекту оказывается гораздо сложнее, чем простая склейка зрения и текста.
👁️ Эволюция компьютерного зрения: от индивидуальных смыслов к общему ИИ 0:00
Мотивация создания VLM: от практических задач к ИИ общего назначения 9:12
Интеграция различных модальностей в искусственный интеллект долгое время оставалась сугубо исследовательской задачей, однако к концу 2024 года ситуация кардинально изменилась. Эксперт в области ИИ и представитель компании Veratai Вилл Хардман (Will Hardman) отмечает, что разработчики сейчас находятся на пороге взрывного роста прикладного использования Vision Language Models (VLM). Если созданием ИИ-решений на базе больших языковых моделей (LLM) занимаются уже очень многие, то визуально-языковые модели пока остаются недооцененным инструментом, потенциал которого в полной мере раскроется в ближайшем будущем.
Спектр коммерческого и индустриального применения VLM огромен и охватывает самые разные сферы:
-
Медицина: интеллектуальные ассистенты могут анализировать диагностические изображения (снимки МРТ, КТ) параллельно с изучением полной истории болезни пациента, выдавая ценные подсказки для практикующих врачей.
-
Модерация контента: автоматические системы на платформах социальных медиа способны одновременно сканировать изображения и текст на предмет потенциально опасного или нежелательного контента.
-
Каталогизация и поиск: крупномасштабное индексирование архивных материалов или товарных каталогов значительно упрощается, когда система «понимает» продукт на основе как его визуального представления, так и текстового описания.
-
Страхование: модели автоматизируют оценку ущерба, сопоставляя фотографии поврежденных автомобилей со словесными отчетами клиентов, проверяя их на предмет соответствия и выявляя аномалии.
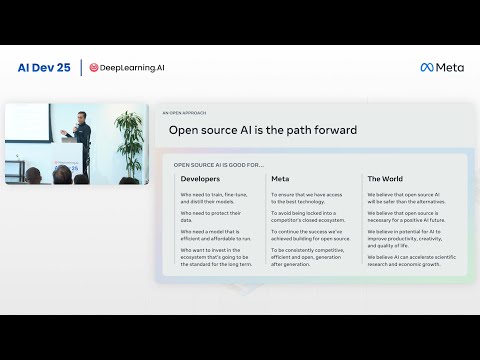
Однако, помимо очевидной коммерческой выгоды, создание VLM преследует две глобальные цели. Первая носит сугубо практический характер и ориентирована на будущее робототехники. Научившись эффективно объединять зрение и текст, исследователи прокладывают путь к интеграции других сенсорных каналов — звука, тактильных данных и лидаров. Это критически важно для создания антропоморфных роботов, способных выполнять сложные бытовые задачи, например, приготовить ужин.
Вторая цель — более глубокая и философская. Ученые пытаются понять, является ли мультимодальное восприятие обязательной ступенью на пути к созданию сильного искусственного интеллекта (AGI). С одной стороны, передовые текстовые модели уже демонстрируют сложные абстрактные рассуждения и строят детальные модели мира без всякого визуального подкрепления. С другой стороны, объединение информации из разных модальностей способно обеспечить качественный трансформационный скачок в способности ИИ понимать окружающую реальность. Как подчеркивает Вилл Хардман, даже если создание текстового AGI теоретически возможно, мультимодальный подход в любом случае станет путем наименьшего сопротивления для индустрии.
Архитектура Vision Transformers: как научить нейросеть читать изображения 13:50
Фундаментом для современных визуально-языковых систем стала архитектура Vision Transformer (ViT), которая перевернула традиционные подходы к компьютерному зрению. До ее появления доминирующей технологией были сверточные нейросети (CNN), которые последовательно накладывали фильтры для извлечения признаков из картинок. Переломный момент наступил в 2020 году с выходом канонической статьи инженеров Google под названием «An Image is Worth 16x16 Words» («Картинка стоит 16x16 слов»). Исследователи задались вопросом: можно ли адаптировать стандартный рецепт текстового трансформера для работы с графикой?
Решение оказалось элегантным и прямолинейным:
-
Входное изображение жестко разбивается на сетку из неперекрывающихся квадратных патчей, например, размером 16x16 пикселей.
-
Полученные патчи вытягиваются в одномерные векторы и пропускаются через слой линейного эмбеддинга, который преобразует их в последовательность визуальных токенов.
-
Эти токены подаются на вход стандартного кодировщика (Transformer encoder), где применяется механизм полного внимания (all-to-all attention) — каждый кусочек изображения может напрямую взаимодействовать и соотноситься со всеми остальными кусочками.
Изначально ViT обучался по аналогии с текстовой моделью BERT: к началу последовательности добавлялся специальный токен классификации ([CLS]), а итоговый вектор на выходе использовался для определения категории объекта на картинке. Главный вывод исследования заключался в том, что при масштабном увеличении объема данных и параметров трансформеры начинают уверенно побеждать классические сверточные сети.
Для последующей интеграции ViT в сложные мультимодальные модели VLM архитектуру пришлось немного модифицировать. Вместо использования одного лишь классификационного вектора разработчики начали извлекать всю последовательность скрытых состояний (hidden states) трансформера, превращая ее в полноценный закодированный образ картинки.
При этом архитектура ViT накладывает ряд важных конструктивных ограничений. Во-первых, разрешение обрабатываемых изображений изначально фиксировано — в классических моделях оно составляло всего 224x224 пикселя. Во-вторых, количество получаемых токенов строго ограничено: нехитрая математика показывает, что картинка 224x224, разбитая на патчи 16x16, дает на выходе ровно 196 визуальных токенов. В индустрии прижилась специальная маркировка таких кодировщиков: например, модель уровня ViT-H/16 означает категорию «Huge» (около 600 миллионов параметров) с размером патча 16, а еще более крупные варианты обозначаются литерой G («Giant»).
Ведущий подкаста Нейтан Лабенц обращает внимание на принципиальное отличие токенизации в тексте и графике. В текстовых моделях используется жесткий, фиксированный словарь (достигающий 100 000 токенов), где каждому слову соответствует свой уникальный код. Визуальные же токены не квантуются и существуют в непрерывном пространстве (континууме), проходя через обучаемую матрицу трансформации. Лабенц вспоминает, как в ранних генерациях систем разработчикам приходилось вручную сжимать, обрезать и грубо искажать исходные изображения под формат 224x224, и поражается тому, насколько точными оставались модели даже на таких деформированных данных. Впрочем, Вилл Хардман обнадеживает: современные продвинутые V-L модели ушли далеко вперед от простых низкоразрешенных квадратов и используют куда более изощренные методы обработки графики высокого разрешения. Это заложило основу для появления таких прорывных подходов, как контрастивное обучение в CLIP, детальный разбор которого последует далее.
🖼️ Модель CLIP и контрастивное обучение модальностей 25:09
Модель CLIP от OpenAI стала каноническим решением в области машинного обучения, продемонстрировав, как эффективно можно выравнивать векторные пространства текста и изображений. Суть метода заключается в совместном обучении двух отдельных энкодеров — визуального (обычно Vision Transformer) и текстового (обычно Transformer-энкодер).
Процесс обучения базируется на использовании огромного массива данных, собранных из интернета — пар «изображение и подпись». Ключевой инновацией стал контрастивный लॉस (loss function):
- Для каждой пары «изображение-подпись» в батче из $n$ элементов, модель стремится максимизировать косинусное сходство между соответствующими эмбеддингами.
- Для всех остальных $n^2 - n$ комбинаций в батче, которые не являются парами, модель, наоборот, штрафует сходство, «расталкивая» их векторные представления.
Вилл Хардман отмечает, что такой подход позволил отойти от ограниченных и жестко заданных классификационных датасетов вроде ImageNet, где модели соревновались лишь в точности предсказания фиксированного набора классов. CLIP же научился «понимать» визуальный контент в широком смысле, используя шумные веб-данные.
Несмотря на эффективность, CLIP обладал существенными ограничениями, связанными с качеством исходных данных:
- Шум в подписях: Поскольку веб-данные содержат самые разные описания (от шуток до строк из стихов), модель нередко сталкивалась с артефактами.
- Отсутствие эстетического сигнала: CLIP отлично считывал контент, но совершенно не учитывал качество изображения, что критически важно для коммерческих задач, где визуальная эстетика определяет успех маркетинговых материалов.
Впоследствии это привело к индустриальной одержимости фильтрацией данных по качеству, что стало лейтмотивом развития большинства последующих мультимодальных моделей. Ранее в разговоре они касались мотивации создания VLM, которая обсуждалась в первой главе.
🦩 Модель Flamingo и механизм Perceiver Resampler 35:23
Появление модели Flamingo от DeepMind в 2022 году часто называют «моментом GPT-3» для мира Vision Language Models (VLM). Flamingo задала базовый архитектурный паттерн для большинства современных моделей этого класса: использование предобученных и «замороженных» энкодеров для текста и изображений, соединенных через специально обученные слои кросс-внимания (cross-attention).
Архитектурные инновации 36:14
Основная задача заключалась в том, чтобы «подружить» визуальные токены с языковой моделью (в оригинале — Chinchilla). Для этого разработчики внедрили слои кросс-внимания, прослоенные между блоками трансформера. Однако здесь возникали две технические проблемы:
- Переменная длина визуальной последовательности: Количество токенов от изображений может варьироваться, в то время как механизм внимания требует фиксированных размерностей.
- Вычислительная сложность: Прямое вычисление всех связей между визуальными токенами и языковыми было бы слишком ресурсоемким.
Perceiver Resampler 38:02
Решением стал блок Perceiver Resampler — отдельный модуль, выступающий «адаптером» между визуальным энкодером и языковой моделью. Вместо вычисления громоздкой матрицы внимания для всей последовательности, модель использует 64 обучаемых вектора (латентных запроса).
- Perceiver Resampler сжимает любую визуальную информацию в фиксированный набор из 64 токенов.
- Это позволяет языковой модели всегда получать предсказуемый объем визуального контекста, сохраняя при этом эффективность обучения.
Хардман подчеркивает, что этот механизм работает удивительно эффективно, несмотря на кажущуюся интуитивную «хаотичность» процесса сжатия визуальных признаков в блендере слоев.
Роль «interleaved» данных 46:18
Одной из важнейших находок команды Flamingo стало использование так называемых interleaved (чередующихся) данных. Вместо простых пар «изображение-подпись», они обучали модель на веб-документах (HTML), где текст и изображения естественным образом перемежаются. Это позволило Flamingo демонстрировать впечатляющие результаты в формате few-shot (обучение на малом числе примеров), оставаясь при этом вычислительно эффективной, так как основные параметры языковой и визуальной моделей оставались неизменными.
🤖 Революция LLaVA: от проекционных матриц к синтетическим диалогам
[]
Разработчики модели LLaVA предложили архитектурное решение, которое радикально упростило создание мультимодальных систем. В отличие от Flamingo, которая опиралась на сложные слои кросс-внимания, команда LLaVA сделала выбор в пользу более прямолинейного авторегрессионного подхода.
Суть метода заключается в использовании простой проекционной матрицы, которая преобразует визуальные токены, полученные из CLIP-совместимого Vision Transformer, в пространство текстовых эмбеддингов. Эти токены затем «впрыскиваются» непосредственно в поток декодера языковой модели, а не обрабатываются отдельными механизмами внимания. В исходной архитектуре LLaVA все текстовые токены, поступающие в языковой бэкенд, просто дополнялись (prepended) визуальными токенами, превращая процесс обучения в последовательную обработку визуальных и текстовых данных.
Однако у такого подхода есть свои нюансы. Во-первых, при генерации длинных последовательностей визуальных токенов, модель вынуждена «разворачивать» их все в декодере, что делает их частью общего механизма внимания. Во-вторых, использование линейного слоя (проекционной матрицы) требует значительно меньше параметров, чем механизмы кросс-внимания. Если этого оказывается недостаточно для точного выравнивания модальностей, разработчикам приходится дообучать саму языковую модель, что создает риск «катастрофического забывания» навыков, приобретенных моделью ранее. Тем не менее, возможность «обмануть» языковую модель, подавая изображения как текстовые эмбеддинги, остается одним из самых впечатляющих достижений этой архитектуры.
Главным вкладом разработчиков LLaVA стала методика генерации инструктивных данных. Используя 200 000 изображений из датасета COCO (от Microsoft, 2014 г.) с описаниями и ограничивающими рамками (bounding boxes), команда задействовала GPT-4 для синтеза сложных диалогов. С помощью специально разработанных шаблонов модель «притворялась», что видит изображение, и создавала вопросы, требующие как простых ответов, так и глубокого логического рассуждения.
Процесс обучения модели включал два этапа:
- Предварительное обучение на 600 000 пар «изображение-подпись» для выравнивания модальностей.
- Инструктивное дообучение (fine-tuning) на 150 000 синтетических примеров, включающих многоходовые разговоры и вопросы по конкретным областям изображения.
Такой «умный» подход к созданию данных позволил LLaVA превзойти все существовавшие на тот момент модели по качеству визуального мышления и conversational-способностям.
📊 Бенчмарк MMMU: измерение «интеллекта» в мультимодальности
[]
Для объективной оценки того, насколько «умной» является мультимодальная модель (VLM), Вилл Хардман выделяет бенчмарк MMMU (Massive Multidiscipline Multimodal Understanding) как наиболее актуальный. Его можно рассматривать как своего рода мультимодальный аналог классического теста MMLU.
Бенчмарк был разработан для измерения трех ключевых навыков:
- Восприятие (Perception): способность увидеть детали на изображении.
- Знания (Knowledge): обладание экспертными знаниями о предмете на изображении.
- Логика (Reasoning): способность делать выводы на основе увиденного.
Материал для MMMU был собран студентами из университетских учебников, лекций и онлайн-ресурсов. Всего бенчмарк включает около 11 000 вопросов, охватывающих 30 различных дисциплин — от истории и медицины до сложной электроники и музыкальных партитур. Вопросы обычно представлены в виде тестов с четырьмя вариантами ответов (A, B, C, D), где необходимо выбрать единственный верный.
На момент релиза в ноябре 2023 года лидером был GPT-4V с результатом 55%. Сейчас же ситуация изменилась: согласно данным Хардмана, OpenAI o1 уверенно возглавляет лидерборд, достигнув показателя в 78%. При этом стоит упомянуть, что ранее в разговоре они касались методов предобучения серии Qwen-VL, но MMMU остается критическим тестом для понимания того, насколько модель способна не просто распознавать объекты, но и рассуждать о них, эффективно интерпретируя визуальные токены.
🧬 Иерархия обучения и магия разрешения: Путь Qwen и InternVL 1:15:35
В современной гонке мультимодальных моделей (VLM) наметились два лидера, чьи подходы к обучению стали эталонными: серия Qwen-VL от Alibaba и InternVL от Shanghai AI Lab. Если ранние модели вроде LLaVA, о которых мы говорили ранее, полагались на простую проекцию визуальных признаков в языковое пространство, то новые игроки внедрили сложную многоэтапную систему «взросления» нейросети.
Qwen-VL: Трехэтапная эволюция и OCR-мудрость 1:16:14
Как отмечает Вилл Хардман (Will Hardman), главной инновацией команды Alibaba в модели Qwen-VL стало разделение процесса предобучения на три четких фазы. Это позволило решить фундаментальную проблему: как научить модель видеть детали, не «сломав» при этом её языковые способности.
- Этап 1: Совмещение пространств. На этом шаге языковая модель (LLM) остается полностью замороженной. Обучаются только Vision Transformer (ViT) и связующий модуль-коннектор. Используются стандартные изображения размером 224x224 точки. Цель — научить визуальный энкодер «разговаривать» на языке смыслов, понятных декодеру.
- Этап 2: Мультизадачное «размораживание». Здесь происходит самое интересное — LLM размораживают, а разрешение изображений увеличивают до 448x448. В обучающую выборку подмешивают синтетические данные OCR (распознавание текста) и визуального заземления (visual grounding).
- Этап 3: Финальная полировка (SFT). На последней стадии используется высококачественный набор данных для настройки инструкций (Supervised Fine-Tuning), созданный с помощью «self-instruct» методов.
Особое внимание Вилл уделяет тому, почему на втором этапе критически важно продолжать подавать модели чисто текстовые данные. Если этого не делать, в процессе обратного распространения ошибки через всю сеть (backpropagation) механизм внимания может «перекоситься» в сторону визуальных задач, и модель растеряет свои навыки логического рассуждения в тексте. В итоге Qwen 2 VL сегодня на равных соревнуется с закрытыми гигантами от OpenAI и Google в тестах вроде MMMU.
InternVL: Гигантские энкодеры и контрастивное будущее 1:26:29
Серия InternVL от OpenGV Lab (Шанхайская лаборатория ИИ) пошла еще дальше в вопросах масштабирования. Вилл Хардман называет их ведущими представителями open-source сегмента. Если стандартные визуальные энкодеры (например, из семейства CLIP, упомянутых в главе 2) имеют около 600 миллионов параметров, то InternVL представила монструозный ViT на 6 миллиардов параметров.
Инновация первой версии InternVL заключалась в методе обучения этого энкодера. Вместо того чтобы просто копировать архитектуру CLIP, авторы использовали замороженный декодер Llama 7B для контрастивного обучения. Они заставляли энкодер подстраиваться под внутренние представления уже обученного мощного языкового ядра. Такой подход создал «идеально выровненный» визуальный модуль, который позже можно было подключать к любой другой LLM.
Вилл подчеркивает разрыв в эффективности: в то время как Qwen 2 VL поглощала 1,5 триллиона токенов, InternVL достигла впечатляющих результатов всего на 120 миллиардах токенов смешанных данных.
Динамическое разрешение: Как «нарезать» картинку без потери смысла 1:36:50
Одной из самых острых проблем VLM долгое время была фиксированная «сетка» зрения. Изображения либо сжимались до квадрата, теряя детали, либо обрезались. В версии InternVL 1.5 была представлена стратегия Dynamic High Resolution.
Суть метода заключается в динамическом тайлинге:
- Система анализирует аспектное соотношение сторон картинки (например, панорама или длинный скриншот).
- Изображение разбивается на блоки размером 448x448. Количество блоков (1x2, 4x2, 4x4) зависит от разрешения исходника.
- Параллельно создается уменьшенная копия всего изображения («thumbnail»), которая конкатенируется с набором детальных блоков.
Чтобы языковая модель не «захлебнулась» от огромного количества визуальных токенов, применяется метод Pixel Shuffle. Вилл объясняет это как способ сжатия, где пространственные измерения (ширина и высота) перераспределяются в измерение глубины тензора. Это позволяет значительно сократить число токенов, сохраняя при этом информацию о мелких деталях, таких как текст в документах.
Интересно, что подобная логика, судя по всему, лежит в основе и проприетарных моделей. Вилл указывает на ценообразование GPT-4V: наличие режима «low resolution» с фиксированной ценой в 75 токенов идеально соответствует концепции «thumbnail» (глобального вида), тогда как режим «high resolution» масштабирует стоимость кратно плитками 512x512. Это намекает на то, что лидеры рынка используют схожие архитектурные хитрости для работы с произвольными форматами изображений.
🚀 Эволюция эффективности: прогрессивное масштабирование InternVL 2.5 и кросс-внимание в Llama 3 Vision 1:44:02
Прогрессивное масштабирование в InternVL 2.5: революция вычислительной эффективности 1:44:02
В то время как индустрия привыкла решать задачи улучшения мультимодальных моделей простым увеличением масштаба данных и вычислительных мощностей, создатели серии InternVL предложили принципиально иной подход. Вилл Хардман (Will Hardman) выделяет стратегию прогрессивного масштабирования (Progressive Scaling), реализованную в версии InternVL 2.5, как один из самых ярких технологических прорывов последнего времени. Эта стратегия успешно решает ключевую проблему обучения больших мультимодальных систем — колоссальные затраты на одновременную сонастройку огромного визуального кодировщика и гигантской языковой модели с нуля.
Суть метода заключается в поэтапной замене текстового бэкэнда на более крупный прямо в процессе обучения. Разработчики InternVL создали несколько классов моделей: базовую версию на 7 миллиардов параметров, среднеразмерную и флагманскую модель на 78 миллиардов параметров. Вместо того чтобы сразу подключать визуальный кодировщик (Vision Transformer) к самой тяжелой языковой модели, они сначала выравнивают его с самой маленькой текстовой сетью. На этом этапе модель обучается до ранней сходимости. Затем меньший текстовый бэкэнд «вынимается», на его место интегрируется модель следующего класса, и предобучение продолжается — вплоть до развертывания финальной 78-миллиардной языковой модели.
Как объясняет Вилл Хардман, интуиция за этим процессом кроется в динамике изменения свободных параметров. Когда параметров слишком много, алгоритму градиентного спуска требуется гораздо больше времени и данных, чтобы нащупать оптимальные локальные минимумы («бассейны») в пространстве поиска. Маленькая модель обладает меньшим количеством свободных параметров, поэтому она находит хорошие базовые решения намного быстрее и демонстрирует более высокую эффективность выборки (sample efficiency). Когда визуальный кодировщик уже научился базовому выравниванию и обученная система переносится на более крупную модель, процесс стартует не с нуля, а из уже найденной удачной точки поискового пространства. Это избавляет систему от необходимости блуждать по всему гигантскому ландшафту параметров большой модели.
Результаты этой оптимизации оказались ошеломляющими:
- Для достижения сопоставимого уровня потерь (complexity loss) при предобучении InternVL 2.5 потребовалось обработать всего 120 миллиардов токенов.
- В то же время её ближайший конкурент, модель Qwen 2 VL, для достижения аналогичных результатов был вынужден обработать около 1.4 триллиона токенов.
Таким образом, прогрессивное масштабирование экономит ресурсы сразу в двух измерениях: за счет снижения вычислительной сложности на первых этапах и за счет колоссального — почти двенадцатикратного — сокращения объема необходимого датасета. Эта стратегия вывела InternVL 2.5 на лидирующие позиции. На авторитетном бенчмарке MMMU 78-миллиардная модель заняла строчку сразу за o1, опередив майскую версию GPT-4o, оригинальную Claude 3.5 Sonnet и Gemini 1.5 Pro, а также показала выдающиеся результаты на тестах VQA и OCR Bench. Подобные подходы позволяют разработчикам заявлять о создании моделей фронтирного уровня при затратах, составляющих лишь однозначную долю процентов от бюджетов западных ИТ-гигантов.
Архитектура кросс-внимания в Llama 3 Vision: сохранение языкового суверенитета 1:52:38
Долгое время в индустрии VLM доминировала авторегрессионная архитектура на основе самовнимания (self-attention), где визуальные токены просто внедряются в общий текстовый поток. Из-за этого могло показаться, что классическая архитектура кросс-внимания (cross-attention) окончательно ушла в прошлое. Однако выход моделей Llama 3 Vision от компании Meta опроверг это предположение.
В Llama 3 Vision разработчики применили модифицированный визуальный кодировщик ViT H14 на 600 миллионов параметров и интегрировали новые слои кросс-внимания непосредственно внутрь системы. Главной особенностью этого подхода стало то, что инженеры полностью заморозили базовую языковую модель Llama 3. В процессе предобучения, последующего инструктивного fine-tuning и даже на этапе оптимизации предпочтений (DPO) обучались исключительно новые слои кросс-внимания и сам Vision Transformer. К слову, применение алгоритма DPO для визуально-языковых моделей на тот момент было редким и передовым тактическим решением.
Вилл Хардман подчеркивает, что выбор в пользу кросс-внимания имел под собой железную логику: если вы используете стандартную decoder-only архитектуру, для улучшения связи модальностей вам неизбежно придется разморозить механизм внимания самого текстового декодера. Но в этот момент возникает колоссальный риск деградации или «размывания» исходных языковых навыков модели, на оттачивание которых были потрачены миллионы долларов. Заморозка основного бэкэнда Llama 3 позволила Meta полностью сохранить исходные текстовые возможности базовой модели. Учитывая масштаб 90-миллиардной версии Llama 3, добавление слоев кросс-внимания увеличило объем параметров примерно на 25%. Это дало колоссальное количество новых свободных параметров, достаточных для качественного выравнивания модальностей без вмешательства в текстовое ядро.
Для достижения фронтирного качества Meta инвестировала огромные ресурсы в подготовку данных:
- Проводилась тотальная очистка, дедупликация, фильтрация по качеству и десенситизация мультимодальных датасетов.
- Активно применялась синтетическая аугментация претрейн-микса с генерацией OCR-данных машинного происхождения, таблиц, графиков и LaTeX-документов.
- Общий объем обучающего бюджета составил около триллиона токенов.
Такой подход полностью оправдал себя: 90-миллиардная модель Llama 3.2 заняла второе место среди open-source решений на бенчмарке MMMU, вплотную приблизившись к InternVL 2.5. Это доказывает, что фронтирные результаты могут быть успешно достигнуты обоими путями.
Тем не менее, архитектура кросс-внимания имеет специфические ограничения. Ряд исследовательских команд отмечает, что она уступает decoder-only моделям в задачах точечного оптического распознавания символов (OCR). Причиной тому — использование механизмов фиксации размера визуальных токенов, которые производят мелкозернистое «перемешивание» (shuffling) токенов, что вредит восприятию мелкого текста. Кроме того, в индустрии существует консенсус, что сквозное мультимодальное рассуждение (reasoning) дается архитектурам со сквозным самовниманием легче: когда визуальные и текстовые токены изначально смешиваются в одной последовательности, механизму внимания проще строить глубокие логические связи.
В конечном счете, появление Llama 3 Vision во многом обусловлено внутренней организационной структурой Meta, где долгое время параллельно существовали независимые команды языковых и визуальных исследований. И хотя индустрия постепенно движется к тотальной унификации, данный подход стал великолепным примером того, как можно создать мощный мультимодальный продукт, сохранив стабильность и модульность базовых текстовых технологий.
🔬 Архитектурный выбор: декодеры против кросс-внимания 2:05:57
Современные исследования, проведенные командами Hugging Face и Nvidia, ставят перед собой фундаментальный вопрос: как именно соединение визуального кодировщика и языкового декодера влияет на итоговую производительность мультимодальной модели? Систематический анализ показал, что выбор архитектуры кардинально меняет поведение системы.
В серии работ под общим названием «IDefics» исследователи из Hugging Face наглядно продемонстрировали, что если зафиксировать веса языковой модели и обучать только новые параметры (проекционную матрицу или слои кросс-внимания), то архитектура с кросс-вниманием показывает себя значительно лучше. Это ожидаемый результат, так как наличие дополнительных слоев дает больше обучаемых параметров. Однако ситуация меняется, если разрешить полное обновление параметров языкового бэкенда. При попытке обновить механизм внимания в базовой модели исследователи столкнулись с нестабильностью обучения, что вынудило их использовать LoRA (low-rank adapters). В этом сценарии авторегрессионные модели «декодер-только» показали более высокую эффективность.
Схожие выводы были получены компанией Nvidia в проекте NVLM. Сравнив «декодер-только» (вариант D) и архитектуру с кросс-вниманием (вариант X) при одинаковом количестве вычислительных операций (FLOPs), команда пришла к однозначному заключению: именно авторегрессионный подход обеспечивает наилучшее мультимодальное понимание, способности к рассуждению и результаты в задачах распознавания текста (OCR). При этом архитектура с кросс-вниманием сохраняет серьезное преимущество в эффективности обучения, так как она не требует «разворачивания» полной последовательности визуальных токенов непосредственно в декодере.
💡 Гибридный подход как новая надежда 2:12:20
Не ограничиваясь дихотомией «декодер против кросс-внимания», команда Nvidia протестировала гибридную архитектуру. Её концепция заключается в использовании авторегрессионного механизма для обработки текста и «миниатюр» изображений, в то время как высокодетализированные визуальные фрагменты (тайлы) подаются через кросс-внимание.
Этот подход позволяет совместить преимущества обеих схем: декодер удерживает контекст изображения вместе с текстом для качественного логического вывода, а кросс-внимание обеспечивает доступ к высокому разрешению без чрезмерной вычислительной нагрузки. Хотя «чистые» декодеры все еще лидируют в чистом OCR, гибридные модели показывают многообещающие результаты, в частности, опережая остальные архитектуры на валидационном сете бенчмарка MMMU. Хотя доминирование гибридных систем еще не стало общепринятым стандартом, эти данные указывают на то, что потенциал архитектурных поисков далеко не исчерпан.
🧠 Влияние мультимодальности на «чистый» интеллект 2:20:15
Одним из самых интригующих открытий в недавних исследованиях стал эффект влияния визуального обучения на текстовые навыки. Ранее в разговоре уже затрагивалась важность правильного подбора данных, но Nvidia пошла дальше, проанализировав, как добавление визуальной модальности меняет производительность моделей на классических текстовых бенчмарках (MMLU, Math, HumanEval).
Традиционно обучение на изображениях без тщательного перемешивания с чисто текстовыми данными приводило к деградации языковых способностей. Однако при использовании качественного датасета для супервизорного дообучения, включающего много математических задач в формате геометрических изображений, исследователи зафиксировали неожиданное улучшение. Модели стали лучше справляться с математическими задачами, представленными даже в чисто текстовом виде. Вилл Хардман сравнивает это с известной концепцией «вращателей фигур» (shape rotators), предполагая, что интеграция визуального восприятия дает языковой модели новые инструменты для абстрактного мышления, которыми она не обладала в рамках «текстовой изоляции». Этот феномен подкрепляет гипотезу о том, что путь к общему искусственному интеллекту (AGI) лежит через объединение как можно большего числа модальностей для создания максимально объемной картины мира.
🧩 Глазами человека и машины: бенчмарки VQA, DocVQA и тест-вспышка Blink 2:34:04
Бытовой здравый смысл и чтение документов: VQA, DocVQA и «Поваренная книга» Cauldron 2:34:04
Переходя от архитектурных споров о раннем и позднем слиянии модальностей, Вилл Хардман (Will Hardman) предлагает сфокусироваться на практической стороне — данных и бенчмарках, которые сегодня формируют ландшафт тонкой настройки (fine-tuning) мультимодальных моделей. Первым важнейшим столпом здесь выступает классический бенчмарк VQA (Visual Question Answering).
Этот набор данных устроен следующим образом:
-
Включает около 50 тысяч изображений, в основном заимствованных из датасета COCO (Common Objects in Context).
-
Для каждой картинки краудсорсеры из Amazon Mechanical Turk сформулировали открытые вопросы.
-
Задания требуют одновременного понимания визуального ряда, языка и базового здравого смысла.
-
Всего датасет содержит около миллиона пар вопросов и ответов.
Хардман приводит яркий пример задания: фотография женщины, у которой к верхней губе прикреплены бананы в виде усов. Модели задают каверзный вопрос: «Какого цвета её глаза?». Невнимательная VLM может зацепиться за яркое желтое пятно по центру экрана и выдать ошибочный ответ «желтый», хотя правильный ответ требует четкой локализации объектов. Другой вопрос — «Из чего сделаны усы?» — заставляет модель сопоставлять пространственное положение элементов на лице и распознавать конкретный объект. В отличие от академического бенчмарка MMMU, оценивающего сложное междисциплинарное мышление (о котором шла речь в главе 3), VQA проверяет именно бытовую логику и простые взаимосвязи объектов.
Прямым коммерчески ориентированным развитием этой идеи стал бенчмарк DocVQA. Он содержит порядка 50 тысяч вопросов, составленных к 12 тысячам изображений реальных индустриальных документов: PDF-сканов, графиков, инвойсов, таблиц и рукописных заметок. Задача модели — изолировать и извлечь точный фрагмент текста, отвечающий на вопрос (например, найти конкретную сумму или номер счета). По словам Хардмана, если ваша цель — автоматизация документооборота, то результаты модели на DocVQA — это главный ориентир при выборе технологического стека.
Для разработчиков, желающих обучить модель подобным трюкам, команда Hugging Face (создатели серии моделей IDEFICS) подготовила отличный инструмент — датасет The Cauldron («Котёл»). Авторы объединили 50 лучших наборов данных для инструктивного и тонкого обучения в единый удобный репозиторий. Вилл Хардман называет его главным «чит-кодом» для инженеров: если модель не справляется с вашей специфической задачей, найдите в The Cauldron аналогичный кейс, изучите его структуру промптов и методы аугментации изображений, чтобы перенести этот опыт на собственный SFT-процесс.
Тест Blink: почему ИИ слеп к тому, что человек видит за мгновение 2:40:13
Если бенчмарки вроде VQA кажутся современным моделям относительно доступными, то тест Blink, выпущенный совместной академической командой и институтом Allen AI, вскрывает фундаментальные перцептивные слабости современных VLM. Бенчмарк состоит из почти 4000 вопросов с множественным выбором, распределенных по 14 категориям базовых перцептивных задач. Ирония заключается в том, что человек решает эти задачи буквально за мгновение (показатель точности людей — в районе 95%), тогда как для ИИ они становятся непреодолимым барьером.
Критика авторов Blink в адрес популярного мультимодального теста MMMU заключается в том, что последний тестирует скорее текстовое мышление, часто сводясь к задаче плотного описания (dense captioning). Если заменить картинку детальным текстовым описанием, обычная языковая модель легко ответит на вопросы MMMU, что подтвердили ранние тесты с использованием LLaVA. Blink же проверяет «чистое» визуальное восприятие.
Вилл Хардман подробно разбирает результаты тестирования моделей в различных категориях Blink:
-
Художественный стиль (Art Style): С этой задачей ИИ справляется лучше всего. Модели GPT-4o удается набрать 83% (при 95% у людей и 50% при случайном угадывании из двух вариантов). Модель успешно понимает, какая из картин выполнена в стиле скетча или ренессанса.
-
Визуальное сходство (Visual Similarity): Здесь моделям нужно сопоставить ракурсы сложных объектов (например, водопадов). GPT-4 Turbo достигает 80% точности, в то время как люди набирают 97%.
-
Геометрические IQ-тесты: Самая провальная категория. В задачах на завершение последовательности фигур люди стабильно набирают около 80%, а лучший результат GPT-4 Turbo составил всего 32,67% при четырех вариантах ответа, что едва превышает порог случайного угадывания в 25%.
Хардман проводит параллель с известным бенчмарком ARC Франсуа Шолле (François Chollet). Человек щелкает такие визуальные задачи мгновенно благодаря врожденным перцептивным шаблонам (perceptual priors), которые сразу сужают пространство поиска. У нейросетей же нет этого эволюционного визуального «каркаса», из-за чего им приходится прибегать к неэффективному полному перебору вариантов (program search). И хотя новейшие рассуждающие модели (вроде текстовой OpenAI o3) демонстрируют колоссальные успехи в ARC, оперируя чистыми массивами цифр в виде текстовых токенов, в тесте Blink модели вынуждены напрямую обрабатывать «сырое» изображение, где этот текстовый трюк не проходит.
В завершение дискуссии Хардман делится практическим наблюдением из опыта работы Veratai, касающимся оценки эстетики изображений. Из-за жестких фильтров безопасности (RLHF) современные коммерческие модели отчаянно избегают критики пользователя — они не хотят говорить человеку, что его фотография неудачная, выдавая размытые формулировки в духе «красота в глазах смотрящего». Чтобы обойти эту вежливость, инженеры используют промпт-инжиниринг. Вместо прямого вопроса «Хорошее ли это фото?» они спрашивают: «Гордился бы малый бизнес, если бы разместил это изображение в своей маркетинговой кампании?». Другой рабочий метод — попарное сравнение (pairwise), например: «Какое из этих двух селфи мне лучше отправить жене?». В таких сценариях модель сбрасывает маску политкорректности и дает четкий, честный и практический ответ.
🍎 Новые горизонты: генеративное предобучение визуальных кодировщиков 3:04:50
В индустрии Vision Language Models (VLM) долгое время доминировал подход контрастивного обучения (ранее в разговоре обсуждались принципы работы модели CLIP и методы контрастивного сопоставления модальностей). Однако эксперты всё чаще задаются вопросом: не является ли контрастивный объектив «бутылочным горлышком», ограничивающим мощь визуальных кодировщиков? Исследовательская команда Apple в работе над проектом AIMv2 предложила радикально иной путь, продемонстрировав значительное преимущество генеративного предобучения.
Рецепт генеративного обучения: от маскирования к восстановлению 3:05:42
В отличие от классического подхода, где модель учится сопоставлять пары «изображение-текст», Apple применила метод, заимствованный из мира больших языковых моделей (LLM). В основе архитектуры AIMv2 лежит «ванильный» Vision Transformer (ViT), который обучается совместно с декодером на огромном массиве данных.
Процесс обучения строится следующим образом:
- Подготовка данных: Изображение разбивается на патчи, которые преобразуются в «мягкие» (не квантованные) визуальные токены.
- Префиксное внимание: Визуальные и текстовые токены подаются в модель последовательно. Часть визуальных токенов принудительно маскируется.
- Двойная функция потерь: Поскольку текстовые токены дискретны, для них используется стандартная кросс-энтропия. Для визуальных же токенов, которые являются непрерывными, применяется функция потерь среднеквадратичной ошибки (MSE).
Таким образом, модель вынуждена предсказывать пропущенные фрагменты изображения, опираясь на контекст — как визуальный, так и текстовый. В конечном итоге, после завершения предобучения, «тяжелый» декодер можно отбросить, оставив мощный и эффективный визуальный энкодер для дальнейшей интеграции в мультимодальные системы.
Преимущества нового подхода 3:09:05
Эксперименты показали, что при подключении энкодера, обученного методом генерации, к модели уровня Llama 3, итоговая VLM демонстрирует прирост производительности на всех ключевых бенчмарках. Наиболее существенные улучшения были зафиксированы в задачах визуального описания (captioning) и визуального вопросно-ответного анализа (VQA).
Этот успех подтверждает гипотезу о том, что отказ от жестких индуктивных смещений (которые были характерны для классических сверточных сетей) и переход к генеративным рецептам обучения позволяют моделям выстраивать более богатые и глубокие представления изображений. Хотя пока остается открытым вопрос, как именно такой метод повлияет на специфические перцептивные задачи, например, на результаты теста Blink, этот переход знаменует важный этап в развитии архитектур зрения. Вероятно, в ближайшие годы мы увидим переосмысление роли Vision Transformer и попытки гармонично сочетать современные подходы с полезными индуктивными приоритетами прошлого.
🎨 Нативная генерация и бенчмарки: триумф Transfusion и битва мини-моделей 3:21:19
Модель Transfusion: революция в генерации и локальном редактировании изображений 3:21:19
В рамках технического разбора современных мультимодальных архитектур Вилл Хардман (Will Hardman) детально описывает устройство инновационной модели Transfusion от Meta. Этот подход предлагает принципиально новый рецепт: вместо привычного квантования графических данных в дискретные токены, разработчики объединили в рамках одного Трансформера предсказание следующего текстового токена и диффузионный лосс для нативной генерации непрерывных изображений. Визуально архитектура Transfusion напоминает классическую латентную диффузионную модель (LDM), которую буквально «разрезали пополам», поместив в самый центр стандартный Трансформер для одновременной обработки разнородных модальностей.
Текстовая часть последовательности обрабатывается привычным линейным слоем с кросс-энтропийным лоссом. Когда же система определяет, что наступает очередь вывода графических токенов, данные направляются через соответствующий up-путь UNet и декодер вариационного автокодировщика (VAE) для непосредственного воссоздания картинки под управлением диффузионного целевого лосса. Критически важным элементом системы является механизм маскирования внимания при обучении: для текста применяется строго каузальное (причинно-следственное) маскирование, тогда как внутри патчей одного изображения активируется двунаправленное (bidirectional) внимание. Это позволяет каждому графическому патчу эффективно взаимодействовать со всеми остальными частями того же изображения.
Результаты экспериментов Meta оказались ошеломляющими. В сравнении с дискретной токенизацией, применявшейся в предыдущей серии моделей Chameleon, архитектура Transfusion позволяет получать изображения аналогичного высокого качества, затрачивая всего треть вычислительных ресурсов (FLOPs) на этапе предобучения. Более того, на чисто текстовых задачах новая архитектура демонстрирует показатели потерь, идентичные Chameleon, но всего при половине затраченных FLOPs. Модель Transfusion с 7 миллиардами параметров в тестах генерации превосходит специализированные системы DALL-E 2 и Stable Diffusion XL, одновременно сохраняя текстовую производительность на уровне базовой Llama 1.
Особую ценность данный подход представляет для локального редактирования графики по текстовым инструкциям (instruct-style editing). Старые инструменты вроде InstructPix2Pix часто страдали от непредсказуемых искажений, тогда как Transfusion способна вносить ювелирные точечные изменения, не нарушая общую композицию кадра. Эксперты приводят в пример замену обычного уличного граффити на борту грузовика на сложнейшую каллиграфию, которая идеально вписывается в текстуру и освещение сцены. Для коммерческих сервисов автоматизации контента, таких как Waymark, это открывает долгожданное решение проблем с контролем генерации, удержанием идентичности персонажей и консистентностью сцен. Примечательно, что среди авторов этого прорывного исследования фигурирует Лили Ю (Lily Yu), ранее получившая известность благодаря архитектуре Megabyte.
Дуэль титанов: китайские открытые модели против закрытых американских систем 3:37:00
Анализируя актуальное состояние индустрии, эксперты представляют детальный срез глобальных лидербордов VLM, агрегированный на основе последних открытых тестов. Стоит отметить, что ранее в разговоре собеседники подробно разбирали специфику мультимодальных бенчмарков MMMU, DocVQA и Blink, однако свежие метрики заставляют взглянуть на баланс сил совершенно иначе. Главный вывод этого сопоставления — практически полное исчезновение технологического разрыва между закрытыми американскими флагманами и открытыми китайскими разработками.
В области сложного мультимодального мышнения на бенчмарке MMMU лидирующую позицию занимает модель GPT-4o1 (в версии preview) с результатом 78%. Однако на следующей строчке с минимальным отставанием расположились Claude 3.5 Sonnet (new) и открытая модель InternVL 2.5 от Shanghai AI Lab (OpenGVLab) — обе системы показывают результат в районе 70%. Поразительно, что отставание китайской открытой модели от флагмана Anthropic составляет всего 0.3%, при том что InternVL 2.5 вышла на пять месяцев раньше. На этом фоне американская модель Grok 2 Beta выглядит догоняющей со своими 66%.
В задачах анализа документов и извлечения текстовой информации из изображений (DocVQA) все ключевые игроки преодолели порог в 90%. Тем не менее, абсолютным лидером здесь выступает китайская open-source модель Qwen2-VL от Alibaba, набравшая рекордные 96.5% и обошедшая как Gemini 1.5 Pro, так и базовую GPT-4o. На визуальном бенчмарке Blink, оценивающем базовое восприятие геометрии и пространства, InternVL 2.5 снова удерживает лидерство с результатом 63.8%, опережая GPT-4o (63.2%), Gemini (61%) и новую Claude 3.5 Sonnet (56.5%). Эксперты подчеркивают, что китайские лаборатории оперируют моделями в весовой категории 70–80 миллиардов параметров, планомерно улучшая обучающие рецепты.
Мал, да удал: прорыв Gemini 2.0 Flash и секреты Phi 3.5 3:43:04
Отдельного внимания заслуживает сегмент компактных мини-моделей, где разворачивается не менее драматичное соперничество за оптимальное соотношение скорости, стоимости и качества. На бенчмарке MMMU безоговорочно доминирует новая Gemini 2.0 Flash, которая с результатом 70.7% буквально разгромила всех конкурентов в своем классе, включая GPT-4o mini и Grok 2 mini, набравшую лишь 63.2%. В то же время, уменьшенная 8-миллиардная версия InternVL 2.5 демонстрирует феноменальные результаты на DocVQA: она набирает 95.1%, что в точности совпадает с показателем её полноразмерной 78-миллиардной версии.
Главным сюрпризом на визуальном бенчмарке Blink стало выступление модели Phi 3.5 Vision от Microsoft. Имея конфигурацию всего в 4 миллиарда параметров, эта компактная модель набрала 58.3%, уверенно обогнав InternVL 2.5 8B (54.8%) и GPT-4o mini (51.9%). Тщательный анализ technical report Phi 3.5 позволяет выделить три ключевых фактора, обусловивших эту аномальную эффективность для сверхмалой архитектуры:
-
Огромный массив предварительного обучения, составивший полтриллиона (500 миллиардов) токенов из смешанного мультимодального датасета.
-
Беспрецедентно масштабный датасет для инструктивного файнтюнинга (SFT) объемом 33 миллиарда токенов, значительная часть которого была синтезирована инхаус самой Microsoft.
-
Интеграция этапа прямой оптимизации предпочтений (DPO), что является крайней редкостью для моделей такого скромного размера и ранее открыто декларировалось разве что в Llama 3V.
Разработчики продолжают доказывать, что правильный подбор данных и агрессивное обучение малых моделей способны творить чудеса, стирая границы между классами систем.
🚀 Практическое применение и будущее VLM: Взгляд из консалтинга 3:48:23
В завершение глубокого погружения в технологии визуального понимания, Вилл Хардман (Will Hardman) переносит фокус с теоретических исследований на реальную бизнес-практику. Его компания, Veratai, специализируется на внедрении искусственного интеллекта, где глубокая техническая экспертиза становится фундаментом для стратегических решений и быстрой проверки гипотез.
Стратегический консалтинг в эпоху ИИ 3:48:23
Основная ниша Veratai — помощь среднему бизнесу (SME) в формировании ИИ-стратегий. Хотя методы компании эффективно работают и в крупных корпорациях на уровне департаментов, именно средний бизнес наиболее остро нуждается в структурированном подходе к хаосу современных инструментов.
Работа с ИИ сегодня характеризуется высокой неопределенностью: концепция «ваши результаты могут варьироваться» (mileage may vary) здесь актуальна как никогда. Поэтому ключевым компонентом деятельности Veratai является методология быстрой разработки прототипов (PoC — proof of concepts). В условиях ограниченности данных или вычислительных мощностей у клиента, крайне важно заранее определить, какие идеи будут легко реализуемы, а какие потребуют чрезмерных ресурсов.
Специализированные домены: Медицина и OSINT 3:49:28
Вилл Хардман отмечает, что мультимодальные модели находят применение в критически важных областях, требующих специфических навыков:
- Медицина: Эксперты Veratai анализируют, как современные языковые модели могут корректно интерпретировать сложную медицинскую терминологию и взаимодействовать с ней.
- OSINT (разведка на основе открытых данных): Это направление активно использует возможности VLM для интерпретации мультимодальных данных. Специалисты решают задачи сопоставления изображений с текстовыми утверждениями, пытаясь подтвердить или опровергнуть факты, а также выявить контекстуальные связи, скрытые в визуальном ряде.
Подготовленный разум и искусство «паттерн-матчинга» 3:51:27
Успех в консалтинге, по мнению Хардмана, невозможен без тотального погружения в индустрию. Скорость, с которой эксперт может предложить решение для конкретной бизнес-ситуации, прямо пропорциональна объему «обсессивных» исследований, проведенных ранее.
Вилл сравнивает этот процесс с работой с личной базой знаний (RAG-индекс), где хранятся тысячи статей, рассылок и научных работ. Когда клиент описывает свою проблему, задача эксперта — выполнить «паттерн-матчинг»: сопоставить запрос с накопленным опытом и предложить варианты решения A или B. Только будучи «пропитанным» технологией и актуальным состоянием рынка, можно точно заметить момент, когда применение конкретной модели даст реальное преимущество на практике.
Ранее в разговоре они касались перспектив развития архитектур моделей, обучения с подкреплением на основе отзывов людей (DPO) и дальнейшего масштабирования предобученных моделей.
Ресурсы и поиск экспертов
Для тех, кто заинтересован в сотрудничестве или хочет следить за публикациями Вилла Хардмана, доступны следующие площадки:
- Официальный сайт Veratai: veratai.co.uk
- LinkedIn: Will Hardman
Вилл активно пишет об ИИ-стратегиях и планирует в будущем освещать вопросы, связанные с развитием моделей визуального понимания.