Развитие технологий искусственного интеллекта за последнее десятилетие коренным образом изменило процессы принятия решений во многих сферах, от медицины до уголовного правосудия. В рамках научного семинара Стэнфордского университета (Stanford Online) был представлен доклад, посвященный исследованию того, как именно люди взаимодействуют с рекомендациями алгоритмов и почему ожидаемый синергетический эффект от сотрудничества человека и машины редко достигается на практике. Автор исследования предлагает инновационные подходы к проектированию адаптивных интерфейсов и переобучению моделей ИИ, способных учитывать поведенческие особенности и когнитивные искажения пользователей.
🧠 Проблема совместной работы человека и искусственного интеллекта 0:09
За последнее десятилетие технологии искусственного интеллекта совершили заметный прогресс и нашли широкое применение в таких критически важных областях, как финансы, здравоохранение и судопроизводство. В прошлом решение комплексных задач полностью ложилось на плечи человека, который самостоятельно анализировал альтернативы и делал финальный выбор. Сегодня же обученные на больших массивах данных алгоритмы способны выявлять скрытые закономерности и предлагать готовые рекомендации, которые затем передаются специалистам для поддержки их решений.
Такая трансформация превратила принятие решений из сугубо человеческой задачи в совместный процесс, где человек и ИИ работают как одна команда. По мнению докладчика, ключевая идея такого сотрудничества заключается в том, что люди и алгоритмы обладают взаимодополняющими сильными и слабыми сторонами. Предполагалось, что, компенсируя недостатки друг друга, этот тандем сможет достичь результатов, превосходящих эффективность как отдельного человека, так и изолированной ИИ-системы. Однако на практике реальный синергетический эффект наблюдается крайне редко.
Для преодоления этой проблемы исследовательская группа выделила два необходимых шага:
- Получить глубокое эмпирическое понимание того, как именно люди взаимодействуют с ИИ-помощниками, насколько они им доверяют и как интегрируют их подсказки в финальные решения.
- Использовать эти данные для изменения дизайна интеллектуальных систем поддержки принятия решений, чтобы они учитывали особенности вовлечения человека.
В рамках доклада представлены результаты нескольких исследовательских проектов, выполненных в этих двух направлениях.
🔍 Иллюзия согласия: эффект предвзятости подтверждения 3:06
На основе серии эмпирических экспериментов исследователи выявили несколько ключевых закономерностей человеческого поведения при работе с ИИ. Во-первых, уровень доверия человека к алгоритму во многом определяется показателями эффективности ИИ, которые пользователь наблюдает лично на практике. Во-вторых, уверенность человека в собственном независимом суждении напрямую влияет на его готовность прислушиваться к советам машины: при прочих равных условиях люди более склонны принимать рекомендации ИИ, когда их собственная уверенность в решении относительно мала.
Наибольший интерес для ученых представили ситуации, когда у пользователей изначально отсутствует объективная информация об эффективности работы используемого алгоритма. Эксперименты показали, что в таких условиях люди используют уровень согласия между рекомендациями ИИ и собственным мнением по тем вопросам, в которых они максимально уверены, как эвристический критерий для оценки надежности всей системы.
Для проверки этой гипотезы был проведен масштабный эксперимент, в котором участникам предлагалось решить задачу прогнозирования исходов быстрых свиданий (speed dating). На основе демографических профилей, личных ценностей и первых впечатлений участников реальных мероприятий испытуемые должны были сделать независимый прогноз: захотят ли партнеры встретиться снова. Затем им демонстрировалась подсказка от ИИ, после чего они принимали окончательное решение.
В ходе предварительного исследования все задачи были разделены на четыре категории в зависимости от точности и уверенности ответов людей:
- Задачи, в которых абсолютное большинство (более 80%) участников дают правильный ответ с высокой степенью уверенности.
- Задачи, где люди совершают ошибку, но делают это с очень высокой уверенностью в своей правоте.
- Задачи, завершающиеся правильным решением, но вызывающие у испытуемых сомнения.
- Задачи, где принимается неверное решение при низкой уверенности в результате.
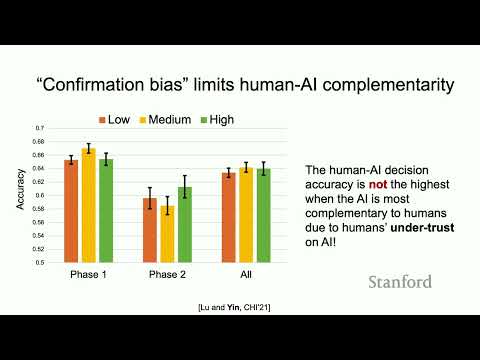
В основном эксперименте участники выполняли последовательность из 40 заданий, разделенных на два равных этапа по 20 задач в каждом, причем информация о реальной точности ИИ им не раскрывалась. На первом этапе исследователи искусственно сформировали три группы условий, варьируя частоту согласия ИИ с мнением большинства участников — от 40% до 100%. При этом реальная точность алгоритма во всех трех группах была абсолютно идентичной.
Докладчик подчеркивает важный парадокс: модель ИИ с низким уровнем согласия (40%) объективно являлась наиболее полезной и комплементарной для человека, так как она чаще всего оказывалась правой именно в тех случаях, когда люди ошибались. Однако результаты показали обратное: чем чаще ИИ соглашался с человеком на первом этапе, тем выше оценивали его надежность, понятность и точность. На втором этапе, где все участники получали одинаковые рекомендации по сложным задачам (с низкой уверенностью людей), те, кто ранее сталкивался с «соглашающимся» ИИ, следовали его советам значительно чаще.
По мнению исследователей, такое поведение наглядно демонстрирует проявление когнитивного искажения — предвзятости подтверждения (confirmation bias) по отношению к алгоритмам. Люди склонны доверять тому ИИ, который подтверждает их собственное мнение, и игнорировать тот, который с ними расходится. Это приводит к опасным последствиям: пользователи начинают избыточно доверять ошибочным рекомендациям ИИ только потому, что он часто соглашался с ними ранее, и отвергать правильные подсказки комплементарного ИИ из-за его частых прежних возражений. В итоге итоговая точность совместной работы человека и машины во всех трех экспериментальных группах практически не отличалась, а потенциал взаимодополняемости остался нераскрытым.
🛡️ Уязвимость перед кибератаками 16:32
Обнаруженная предвзятость подтверждения, как утверждает докладчик, представляет собой серьезную уязвимость в системах человеко-машинного взаимодействия, которой могут воспользоваться злоумышленники. Понимая эту психологическую особенность, атакующая сторона может целенаправленно и скрытно манипулировать ИИ-моделью именно в тех ситуациях, где человек чувствует себя уверенно. Такой подход позволяет максимально быстро разрушить доверие пользователя к ИИ.
По словам автора, злоумышленники могут применять сложные математические инструменты, например скрытые марковские модели (Hidden Markov Models), для прогнозирования того, как их точечные атаки повлияют на уровень доверия человека. На основе этих данных они способны разработать оптимальную стратегию развертывания кибератак, которая позволит максимизировать ущерб для совместной эффективности команды «человек-ИИ» при минимальных затратах со стороны хакеров. Докладчик подчеркивает, что разработка методов защиты от подобных стратегических манипуляций является сегодня крайне актуальной задачей.
🛠️ Три метода адаптивного интерфейса 18:10
Чтобы помочь человеку эффективно комбинировать собственные знания с подсказками ИИ, исследователи предложили оригинальное решение в рамках научной публикации на конференции CHI. Основная идея заключается в том, что для минимизации ошибок пользователю необходимо четко понимать границы своих и машинных компетенций. Для этого система должна в реальном времени оценивать вероятность правильности ответа как со стороны человека, так и со стороны алгоритма на каждом конкретном шаге.
Если оценка уверенности ИИ может базироваться на его калиброванных внутренних метриках, то оценка вероятности ошибки человека в реальном времени представляет собой сложную задачу, поскольку истинный правильный ответ изначально неизвестен. Ученые выдвинули предположение: если человек принимает верные решения на задачах, похожих на текущую, то и в данном случае его ответ с большой вероятностью будет правильным.
Для реализации этой концепции был разработан специальный четырехэтапный рабочий процесс:
- Пользователь выполняет небольшой тестовый набор заданий самостоятельно.
- На основе этих данных строится дерево решений (Decision Tree), моделирующее логику конкретного человека.
- Сгенерированные правила демонстрируются пользователю, который может скорректировать их в соответствии со своим реальным ходом мыслей.
- В процессе работы система сопоставляет текущую задачу с похожими примерами из обучающей выборки ИИ и рассчитывает ожидаемую точность человека на основе его персонального дерева решений.
На базе полученных оценок были созданы и протестированы три типа интерфейсных интервенций:
- Прямое отображение (Direct Display): интерфейс в явном виде показывает пользователю проценты вероятности правильного ответа для него и для ИИ, позволяя человеку самому решать, чью сторону занять.
- Адаптивный рабочий процесс (Adaptive Workflow): если ИИ с большей вероятностью прав, его рекомендация выводится на экран сразу. Если же выше вероятность правоты человека, система сначала просит пользователя зафиксировать собственное мнение и лишь затем показывает подсказку алгоритма. Предыдущие исследования доказывают, что после фиксации своего мнения люди реже бездумно переключаются на ответ машины.
- Адаптивные рекомендации (Adaptive Recommendation): когда вероятность правильности ИИ выше, пользователю демонстрируется и финальный совет, и его объяснение. В противном случае система скрывает конкретную рекомендацию ИИ, показывая только логическое объяснение алгоритма, что снижает вероятность слепого согласия.
Экспериментальная проверка показала, что внедрение этих трех типов интервенций привело к значимому росту итоговой точности совместных решений по сравнению с базовым сценарием, когда подсказка и уверенность ИИ отображаются всегда. Этот прирост был достигнут главным образом за счет снижения избыточного доверия человека к ИИ в тех случаях, когда алгоритм ошибался. При этом в ситуациях, когда ИИ давал верные советы, уровень доверия пользователей остался стабильно высоким.
🤖 ИИ, подстраивающийся под поведение человека 30:33
Альтернативный путь улучшения результатов заключается не в изменении интерфейса, а в переобучении самого алгоритма. Вместо традиционных ИИ-моделей, изолированно оптимизирующих исключительно собственные метрики точности (behavior-oblivious AI), докладчик предлагает создавать ИИ, учитывающий поведение человека (behavior-aware AI). Такие модели изначально закладывают будущую реакцию пользователя в свою целевую функцию обучения для максимизации эффективности всей команды.
В качестве математической основы исследователи использовали модель поведения, согласно которой человек полагается на свое мнение, если его уверенность превышает определенный порог, и доверяет ИИ в противном случае. В рамках такой парадигмы задача оптимизации совместной работы сводится к задаче взвешенной потери (weighted loss optimization). При этом вес каждого обучающего примера обратно пропорционален функции распределения уверенности человека на данном типе задач. Простыми словами, те задачи, в которых человек хорошо ориентируется и уверен в себе, получают меньший вес при обучении алгоритма.
Как показали результаты компьютерного моделирования и экспериментов с участием людей, сотрудничество с таким поведенически-ориентированным ИИ позволяет достичь существенно более высокой точности финальных решений, нежели использование стандартных фиксированных моделей.
👥 Специфика групповых решений и феномен «разрешения споров» 33:03
В реальной практике решения критической важности часто принимаются не отдельными сотрудниками, а группами людей. Чтобы изучить эту специфику, авторы провели сравнительное исследование на материале задач по прогнозированию рецидивизма среди правонарушителей. Испытуемые анализировали реальные исторические профили подсудимых и определяли, совершит ли человек новое преступление в течение последующих двух лет. В рамках эксперимента сравнивалось поведение одиночек и групп из трех человек, искавших консенсус в ходе совместного обсуждения.
Анализ результатов выявил неожиданный и поразительный факт: группы демонстрируют еще более высокий уровень зависимости от ИИ, чем отдельные пользователи. Это проявляется как в ситуациях, когда алгоритм прав, так и тогда, когда он совершает ошибки. Соответственно, у групп снижается уровень недостаточного доверия, но резко возрастает риск избыточного доверия к неверным подсказкам машины.
Изучение логов текстовых чатов помогло исследователям выявить две основные причины этого феномена:
- Инструмент убеждения: в процессе дискуссии один из участников часто использует согласие ИИ со своим личным мнением в качестве сильного аргумента, заявляя остальным, что поддержка алгоритма доказывает превосходство его позиции, и тем самым склоняет группу на свою сторону.
- Разрешение тупиковых споров (Tiebreaker): когда мнения членов группы разделяются и они не могут прийти к единому консенсусу, кто-то предлагает использовать рекомендацию ИИ как решающий голос для выхода из тупика, что автоматически превращает подсказку машины в финальное групповое решение.
Для исправления этой ситуации возникла необходимость стимулировать группы к более критическому анализу и глубокой верификации советов алгоритма.
💬 ИИ в роли «адвоката дьявола» и неожиданное поведение модели 37:33
Классическим методом стимулирования критического мышления в менеджменте является назначение «адвоката дьявола», чья роль заключается в поиске контраргументов. Однако в человеческих командах этот подход имеет ограничения: назначенный человек может сам не верить в выдвигаемые им возражения (из-за чего аргументы звучат неубедительно) и часто сталкивается с проблемой психологического дискомфорта, чувствуя себя изолированным от коллектива.
Для решения этих проблем авторы предложили использовать большую языковую модель (LLM) в качестве виртуального «адвоката дьявола». Нейросеть способна генерировать максимально сильные и глубокие контраргументы без риска пострадать от психологического давления. В эксперименте тестировались четыре конфигурации ИИ-оппонента по двум осям:
- Объект критики: оппонирование мнению большинства группы против оппонирования исключительно рекомендациям базовой ИИ-модели.
- Интерактивность: статический вариант (выдача списка критических вопросов в начале беседы) против динамического (активное участие ИИ в чате и гибкие ответы на реплики людей).
Наилучшие результаты показал динамический виртуальный оппонент, который целенаправленно критиковал подсказки базового ИИ. Такое решение позволило значимо повысить точность групповых решений и существенно снизить уровень слепого избыточного доверия к алгоритму.
Более того, исследователи зафиксировали у LLM-оппонента несколько интересных эмерджентных (самозародившихся) поведенческих паттернов, которые не закладывались в промпты напрямую:
- Вовлечение участников: модель самостоятельно подталкивала пассивных членов группы к высказыванию своего мнения, стремясь к тому, чтобы был услышан голос каждого.
- Указание на фактические ошибки: когда люди строили свои доводы на неверно прочитанных данных из профиля подсудимого, ИИ оперативно вмешивался и просил обратить внимание на реальные факты.
- Стимулирование целостной оценки: если группа концентрировалась лишь на одном признаке (например, отсутствии судимостей в прошлом), алгоритм переключал внимание на другие характеристики, указывающие на противоположный исход.
- Проверка скрытых допущений: ИИ выявлял необоснованные догадки и предположения людей, не подтвержденные документами, и предлагал оценить их валидность.
❓ Дискуссия и перспективы будущих исследований 44:22
В ходе сессии вопросов и ответов участники семинара подняли важную проблему применимости данного метода в условиях, когда базовая модель ИИ обладает сверхвысокой точностью, значительно превосходящей человеческую. Докладчик согласился с тем, что если ИИ практически всегда прав, то активный «адвокат дьявола», разубеждающий людей следовать его советам, может непреднамеренно снизить точность командной работы. По мнению автора, в будущем виртуального оппонента необходимо проектировать так, чтобы он включался в дискуссию избирательно — только тогда, когда у него есть высокая уверенность в ошибочности рекомендации базового ИИ.
Также докладчик пояснил природу поведения LLM в качестве фасилитатора дискуссии. Изначально в системном промпте модели предписывалось использовать метод Сократа для генерации наводящих вопросов и стимулирования глубокого анализа. Это привело к тому, что ИИ естественным образом перенял функции координатора беседы. Перспективным направлением будущих исследований автор назвал четкое разделение ролей: проведение экспериментов, где одни агенты будут выступать исключительно жесткими оппонентами, а другие — нейтральными фасилитаторами и координаторами, для оценки вклада каждой роли в итоговый результат команды.
В заключение автор подчеркнул, что детальное понимание психологии взаимодействия человека с технологиями искусственного интеллекта открывает огромные возможности как для создания умных адаптивных интерфейсов, так и для разработки принципиально новых методов обучения самих нейросетевых моделей.



