Современные нейросети обучаются на огромных массивах данных, зачастую собранных из открытых источников без явного согласия авторов. Популярный ИИ-блогер и исследователь Янник Килхер (Yannic Kilcher) разбирает инновационную работу «Radioactive data: tracing through training», авторы которой предлагают метод «радиоактивной маркировки» данных, позволяющий с высокой точностью определить, использовался ли конкретный набор изображений для обучения той или иной модели.
☢️ Что такое «радиоактивные данные»? 0:01
Проблема несанкционированного использования данных для обучения ИИ становится всё более острой. Янник Килхер иронизирует, что было бы здорово, если бы компьютер злоумышленника «взрывался» при попытке использовать чужие данные, но пока наука предлагает более изящное решение . Группа исследователей (Александр Саблайроль, Маттис Дуз, Корделия Шмидт и Эрве Жигу) разработала метод, который они называют «радиоактивной маркировкой» (radioactive marking) .
Суть метода заключается в следующем:
- В исходный датасет вносятся минимальные, незаметные глазу искажения.
- Эти искажения действуют как «радиоактивный маркер», который переносится в веса нейросети в процессе обучения.
- Позже, имея доступ к обученной модели (или даже только к её ответам), можно провести статистический тест и подтвердить факт использования маркированных данных .
По словам Янника Килхера, методу достаточно, чтобы было помечено всего 1–2% данных из обучающей выборки, чтобы детектировать «заражение» модели .
🧠 Механика процесса: как обмануть классификатор 2:54
Чтобы понять, как работает маркировка, нужно взглянуть на архитектуру современных сверточных нейросетей (CNN). Обычно сеть состоит из двух частей:
- Экстрактор признаков (Feature Extractor): превращает картинку в набор абстрактных характеристик (латентное пространство) .
- Линейный классификатор: последний слой, который сопоставляет эти признаки с конкретными классами (например, «кошка» или «собака») .
Если классификатор работает хорошо, он находит в многомерном пространстве гиперплоскости, разделяющие признаки разных классов .
Янник Килхер объясняет это на примере: если мы классифицируем животных, признаками могут быть наличие усов, меха или количество ног . Метод «радиоактивных данных» добавляет к каждому классу новый, искусственный признак — случайный вектор $u$ в пространстве высокой размерности .
Алгоритм создания маркировки:
- Для каждого класса (например, «кошка») выбирается уникальное случайное направление $u$ в пространстве признаков .
- Данные этого класса в обучающей выборке немного смещаются вдоль этого вектора .
- В процессе обучения нейросеть «замечает», что этот искусственный признак является отличным предиктором класса, и её веса начинают подстраиваться под это направление .
🛠️ Технология нанесения меток: шаг за шагом 18:04
Маркировка происходит не на уровне пикселей «в лоб», а через воздействие на латентные признаки. Поскольку нам нужно изменить изображение так, чтобы оно вызвало определенный отклик в глубине сети, используется механизм, похожий на создание состязательных примеров (adversarial examples) .
Инструкция по маркировке данных (согласно обзору Янника Килхера):
- Выбор модели-учителя: Обучите классификатор на обычных (немаркированных) данных, чтобы получить работающий экстрактор признаков .
- Генерация векторов: Создайте набор случайных векторов $u$ (по одному на каждый класс) в пространстве признаков последнего слоя .
- Оптимизация изображений: Для каждого изображения из датасета запустите процесс обратного распространения ошибки (backpropagation). Цель — минимизировать функцию потерь, которая заставляет признаки изображения двигаться в сторону вектора $u$ .
- Регуляризация: Используйте специальные ограничения, чтобы изменения в пикселях оставались незаметными для человеческого глаза и чтобы модель не теряла в точности классификации .
- Аугментация: Авторы статьи также рекомендуют прогонять изменения через дифференцируемые процедуры аугментации данных, чтобы метка была устойчива к поворотам или обрезке фото .
📊 Детекция: как найти «радиацию» в весах 12:40
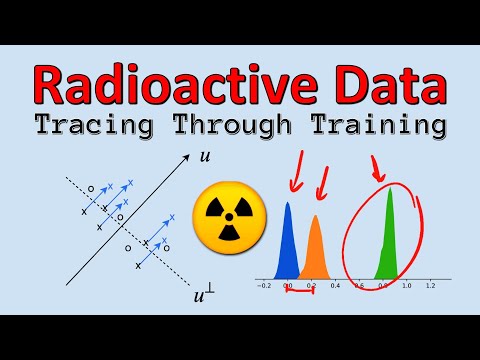
Когда подозрительная модель уже обучена, нам нужно проверить, «знает» она про наши векторы $u$ или нет. В геометрии высоких размерностей случайные векторы почти всегда ортогональны (угол между ними близок к 90 градусам) .
- Если модель не обучалась на ваших данных, косинусная близость между весами её последнего слоя и вашим случайным вектором $u$ будет близка к нулю .
- Если модель обучалась на маркированных данных, веса её классификатора будут заметно смещены в сторону вектора $u$, что даст статистически значимое отклонение от нуля .
Для подтверждения используется статистический тест на основе неполной бета-распределения (incomplete beta distribution) . Янник Килхер отмечает, что даже при маркировке всего 2% данных разница в распределении косинусных близостей становится очевидной .
⚖️ Проблемы точности и скрытности 21:07
Одним из главных вызовов является «выравнивание подпространств» (subspace alignment). Разные нейросети, обученные на одних и тех же данных, могут иметь разные внутренние представления признаков из-за симметрии весов .
Янник Килхер поясняет:
- Хотя разные архитектуры могут извлекать одни и те же семантические признаки (усы, уши), их математическое выражение в матрицах может быть повернуто или смещено .
- Для решения этой проблемы авторы применяют линейную трансформацию (вращение пространства), чтобы сопоставить пространство признаков проверяемой модели со своим эталоном .
По мнению Янника Килхера, метод хорош тем, что он почти не снижает точность (accuracy) итоговой модели . Разница в качестве работы сети на «чистых» и «радиоактивных» данных минимальна, что делает маркировку практически незаметной для того, кто обучает модель .
🤨 Критика и будущие улучшения 29:05
Янник Килхер выражает скепсис по поводу возможности детекции в режиме «черного ящика» (когда нет доступа к весам модели, а только к её ответам) . Авторы статьи предлагают анализировать значения функции потерь на маркированных данных, но Янник считает это сомнительным, так как доступ к значениям loss обычно закрыт для внешних пользователей .
Вместо этого Янник Килхер предлагает альтернативный метод детекции для «черного ящика»:
- Создать изображение, состоящее из чистого «шума», который содержит в себе только один искусственный признак $u$ .
- Подать его на вход модели.
- Если модель с высокой вероятностью выдаст класс, привязанный к этому вектору, это будет почти стопроцентным доказательством кражи данных .
В качестве вектора развития технологии ведущий предлагает делать метки более «скрытными» . Вместо модификации последнего слоя можно заставлять сеть коррелировать два независимых скрытых признака внутри нейросети . Такая «тайная связь» будет видна только при подаче специфического входного сигнала и её будет гораздо сложнее обнаружить или удалить с помощью защитных механизмов вроде размытия .




