В новом видео Янник Килчер (Yannic Kilcher) анализирует научную работу «Gradients are Not All You Need», которая бросает вызов современному тренду на дифференцируемость всего и вся. Автор подробно объясняет, почему в сложных динамических системах классическое обратное распространение ошибки может быть неэффективным и в каких случаях методы «черного ящика» показывают лучшие результаты.
🧠 Суть проблемы: когда градиенты ведут в тупик 1:18
Основной тезис статьи, представленной Янником Килчером, заключается в том, что возможность вычислить градиент не всегда означает целесообразность этого действия. Исследователи (Люк Метц и др.) утверждают, что при работе с итерируемыми динамическими системами, склонными к хаотичному поведению, градиенты становятся крайне нестабильными.
По словам Килчера, сегодня наблюдается бум дифференцируемых систем: от физических симуляторов до обучаемых оптимизаторов. Однако в этих случаях градиенты часто обладают огромной дисперсией (variance) и ведут себя непредсказуемо. Вместо того чтобы слепо полагаться на обратное распространение через внутреннюю динамику системы, авторы предлагают использовать оценку градиента методом «черного ящика».
В качестве примера рассматривается линейная итерируемая система, где состояние $s_{k+1}$ получается путем применения матрицы $A$ к предыдущему состоянию $s_k$. Если повторять этот процесс многократно, мы получаем рекуррентную систему, аналогичную нейронным сетям (RNN) или задачам обучения с подкреплением (RL).
📉 Математика хаоса: якобианы и спектральный анализ 12:04
Ключ к пониманию проблемы лежит в спектре якобианов — матриц частных производных, описывающих переход системы из одного состояния в другое. Янник Килчер подчеркивает, что поведение градиента напрямую зависит от собственного числа (eigenvalue) этого якобиана:
- Взрыв градиентов: если наибольшее собственное число больше 1, норма вектора при многократном умножении растет экспоненциально.
- Затухание градиентов: если число меньше 1, вектор стремится к нулю, что делает обучение невозможным.
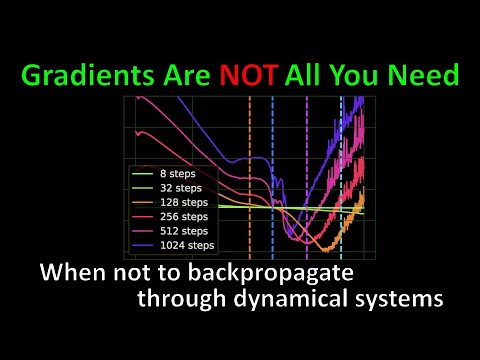
В хаотических системах даже малейшее изменение начальных условий приводит к колоссальным расхождениям в конечном результате. Янник объясняет, что при обратном распространении ошибки через такие системы (BPTT — Backpropagation Through Time) мы сталкиваемся с «телескопическими произведениями» матриц, которые усиливают любую нестабильность.
🧪 Трюк репараметризации и его скрытые угрозы 15:38
Янник Килчер подробно разбирает «трюк репараметризации» (reparameterization trick), широко используемый в вариационных автокодировщиках (VAE). Чтобы сделать процесс семплирования из распределения дифференцируемым, случайность выносится за пределы графа вычислений: например, значение берется из нормального распределения и масштабируется параметрами $\mu$ и $\sigma$.
Однако здесь кроется ловушка. По мнению авторов статьи, хотя этот трюк позволяет обучать модели, он может давать ложное ощущение стабильности. В ситуациях, когда целевая функция сильно осциллирует («шумная» или «зубчатая»), градиент, полученный через репараметризацию, будет иметь экстремально высокую дисперсию. В таких случаях обычный метод «черного ящика» (оценка наклона по двум точкам) работает стабильнее, так как он фактически учитывает сглаженную версию ландшафта потерь.
🛠️ Практическое руководство: инструменты и эксперименты 26:42
В видео выделены три конкретных примера, где дифференцирование «в лоб» проигрывает альтернативным методам.
1. Физика твердых тел в Brax
Для тестов использовался пакет Brax — библиотека для сверхбыстрых дифференцируемых физических симуляций на JAX.
- Задача: Оптимизация стохастической политики управления роботом-муравьем (Ant).
- Наблюдение: При малом количестве шагов (unroll length) градиент гладкий. Но чем дольше симуляция, тем более хаотичным становится ландшафт функции потерь.
- Результат: Попытки использовать чистые градиенты приводят к взрыву дисперсии. Популярные алгоритмы RL, такие как PPO, справляются с этой задачей значительно лучше.
2. Мета-обучение оптимизаторов
Схема «оптимизатор оптимизирует оптимизатор» также страдает от хаоса.
- Проблема: Внутренний оптимизатор работает на мини-батчах, что вносит случайность. При длительном развертывании (unrolling) система становится сверхчувствительной к параметрам.
- Решение: Усреднение по множеству семплов помогает сгладить ландшафт, но не избавляет от фундаментальной нестабильности при больших горизонтах планирования.
3. Упаковка дисков (Disk Packing)
Геометрическая задача размещения частиц разного диаметра в ограниченном объеме.
- При уменьшении диаметра мелких частиц система переходит в нестабильный режим. Незначительный сдвиг одного диска вызывает цепную реакцию столкновений, что делает градиент бесполезным для обучения.
💡 Рекомендации: что делать, если градиенты не работают 40:01
Янник Килчер формулирует несколько стратегий, предложенных в статье для борьбы с патологическими градиентами:
- Выбор стабильных систем: использовать архитектуры, спроектированные для борьбы с нестабильностью, такие как LSTM или GRU, которые за счет механизмов гейтинга более устойчивы к взрыву градиентов.
- Инициализация: в RNN помогает инициализация весов, близкая к единичной матрице (identity), что удерживает собственные числа якобиана в районе единицы на ранних этапах обучения.
- Дробление симуляции: в физике можно разделять процесс на части (свободное движение и момент столкновения) и дифференцировать их по отдельности.
- Методы «черного ящика»: если система хаотична, Килчер рекомендует использовать Evolutionary Strategies (ES) или алгоритмы вроде REINFORCE и PPO. Они дают несмещенную оценку градиента с гораздо меньшей дисперсией в сложных условиях.
«Тот факт, что вы можете вычислить градиент, не означает, что вы всегда должны это делать», — резюмирует Янник, призывая исследователей не бояться возвращаться к методам черного ящика там, где дифференцируемое программирование заходит в тупик.




