В этом выпуске Янник Кильхер (Yannic Kilcher) анализирует исследовательскую работу, представляющую инновационный оператор для компьютерного зрения под названием Involution (инволюция). Исследователи из Гонконгского университета науки и технологий, ByteDance AI Lab и Пекинского университета предлагают переосмыслить фундаментальные принципы работы сверточных нейронных сетей (CNN).
🧠 Что такое инволюция? 0:29
По мнению авторов работы, современные нейросети для зрения по-прежнему сильно зависят от классических сверток, несмотря на растущую популярность трансформеров. Идея инволюции заключается в «инверсии» классических принципов построения сверточных слоев.
Сравнение принципов работы
Классическая свертка обладает двумя ключевыми свойствами:
- Пространственная агностичность (spatial agnostic): одно и то же ядро свертки «скользит» по всему изображению, выполняя идентичные вычисления независимо от позиции. Это обеспечивает трансляционную инвариантность.
- Канальная специфичность (channel specific): для каждого выходного канала создается отдельный набор весов, так как разные каналы отвечают за разные признаки (например, грани, углы или наличие конкретных объектов).
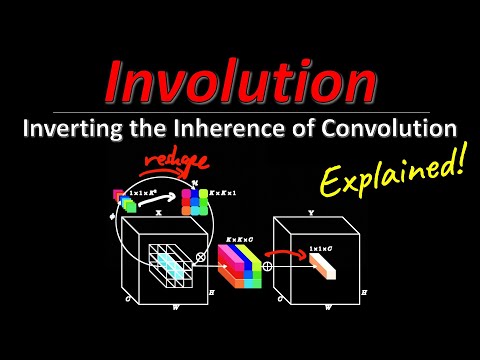
Инволюция предлагает обратный подход: пространственную специфичность и канальную агностичность.
Как устроена инволюция
Вместо статичного набора весов инволюция генерирует ядро «на лету» для каждого конкретного пикселя.
- Динамическая генерация: Для каждого пикселя используется небольшая двухслойная нейросеть («узкое горлышко»), которая на основе значений самого пикселя вычисляет веса ядра.
- Вещание (broadcasting): Вместо создания разных ядер для каждого канала, используется одно ядро, которое транслируется (broadcast) по всем каналам.
- Отсутствие свертки (aggregation): Это позволяет избежать лишних операций редукции, существенно сокращая количество параметров.
По словам Янника Кильхера, такой подход делает инволюцию «золотой серединой» между классической сверткой и механизмом self-attention.
⚖️ Связь с механизмом внимания (Attention) 19:57
Авторы утверждают, что инволюция концептуально близка к механизмам внимания, так как веса вычисляются динамически на основе входных данных. Однако Кильхер отмечает важные различия:
- Отсутствие квадратичной сложности: В отличие от self-attention, где вычисляются матрицы запросов (queries) и ключей (keys), инволюция сразу интерпретирует вычисленные веса как способ агрегации данных.
- Позиционная информация: Инволюции не требуют явной подачи позиционных эмбеддингов, так как сама природа их работы уже привязана к конкретной позиции в пространстве.
Кильхер замечает, что утверждение авторов о том, что self-attention является лишь «усложненной версией инволюции», может быть некоторым преувеличением, однако сама идея вычисления весов на лету представляется ему весьма перспективной.
📊 Результаты и эффективность 25:24
В экспериментах, проведенных на наборе данных ImageNet, сети на основе инволюции показали впечатляющие результаты в сравнении с ResNet:
- Модели достигают точности на уровне ResNet-101, сокращая при этом затраты на хранение и вычисления на 65%.
- Инволюция демонстрирует лучшие показатели в задачах сегментации изображений.
Янник Кильхер полагает, что успех инволюции обусловлен эффективным механизмом совместного использования весов (weight sharing). При этом он выражает осторожный оптимизм: хотя архитектура отлично работает на стандартных задачах, еще предстоит выяснить, как она поведет себя при масштабировании на сверхбольшие объемы данных, где трансформеры могут оказаться эффективнее.




