Компания Meta совершила крупный прорыв в индустрии искусственного интеллекта, выпустив первые открытые модели линейки Llama 3. Автор YouTube-канала Уэс Рот анализирует это событие, сопоставляя новые модели с флагманами от OpenAI, Google и Anthropic. В центре внимания оказываются не только технические бенчмарки, но и глубокая философия открытого исходного кода, которой придерживается глава Meta Марк Цукерберг.
🚀 Сенсационный релиз Llama 3 и амбиции Meta 0:00
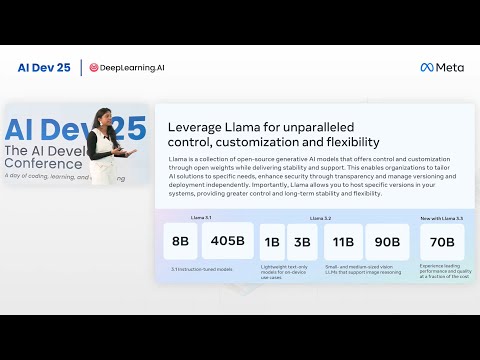
Компания Meta официально представила первые модели своего нового семейства — Llama 3 с объёмом 8 миллиардов и 70 миллиардов параметров. Разработчики заявляют, что эти нейросети демонстрируют лучшие в своём классе результаты для ИИ аналогичного масштаба. Однако главным сюрпризом для индустрии стало известие о том, что прямо сейчас Meta продолжает обучение гигантской плотной (dense) модели, содержащей более 400 миллиардов параметров (Марк Цукерберг ориентируется на точную цифру в 405 миллиардов).
В Meta подчёркивают, что нынешний релиз — лишь начало. В официальной дорожной карте компании запланирован скорый выпуск обновлений, которые принесут моделям мультимодальность, поддержку множества языков и значительно увеличенные окна контекста.
Марк Цукерберг открыто делится своим энтузиазмом относительно промежуточных результатов тестирования. По его словам, строящаяся 405-миллиардная модель уже на текущем этапе обучения демонстрирует около 85 баллов по тесту MMLU. Выпущенная же версия на 70 миллиардов параметров набирает около 82 баллов и показывает лидирующие результаты в тестах на знание математики и логическое рассуждение. Глава Meta уверен, что передача таких инструментов в руки мирового ИИ-сообщества вызовет колоссальный резонанс.
⚖️ Открытый код против закрытых гигантов 2:10
Уэс Рот сопоставляет новые параметры Llama 3 с возможностями признанных лидеров рынка коммерческого ИИ. До сих пор лучшими закрытыми проприетарными системами считались GPT-4 от OpenAI, Claude 3 от Anthropic, а также линейки Gemini Pro 1.5 и Gemini Ultra от Google. Все эти продукты принадлежат крупным корпорациям, имеющим собственную культуру, философию и жёсткие внутренние ограничения. Если руководство такой компании посчитает, что пользователь применяет ИИ не по назначению, доступ к системе будет мгновенно заблокирован.
По мнению известного ИИ-исследователя доктора Джима Фана, появление открытой модели Llama 3 класса 400B+ станет переломным «водораздельным» моментом для всей индустрии. Прорыв заключается в том, что глобальное сообщество исследователей и независимых стартапов впервые получит свободный доступ к весам модели уровня GPT-4. Это кардинально изменит экономические и исследовательские расчёты для сотен ИИ-проектов.
Графики бенчмарков наглядно показывают, что невыпущенная флагманская модель Meta идёт вплотную с GPT-4 Turbo и Claude 3 Opus, а по тестам HumanEval и математическим задачам даже превосходит Gemini Pro 1.5. Джим Фан прогнозирует лавинообразный всплеск энергии разработчиков, поскольку мощную базовую модель теперь можно будет запускать локально и кастомизировать под автономных ИИ-агентов или симуляторы робототехники. Уэс Рот добавляет, что хотя запуск 405-миллиардной модели потребует промышленных мощностей, младшая версия на 70 миллиардов параметров не сильно отстаёт от неё по качеству и куда доступнее.
🛡️ Философия безопасности Марка Цукерберга 5:22
Марк Цукерберг подробно объясняет, почему он занял столь бескомпромиссную позицию в пользу open-source. По его мнению, концентрация сверхопасных ИИ-технологий в руках одной закрытой структуры несёт в себе гораздо больше экзистенциальных рисков для человечества, чем их повсеместное и открытое распространение.
Глава Meta проводит прямую аналогию с классической компьютерной безопасностью. Он предлагает представить гипотетический сценарий путешествия во времени: если бы злоумышленник переместился на два года назад, обладая точными знаниями обо всех уязвимостях операционных систем будущего, он смог бы без труда взломать абсолютно любой компьютер в мире. Именно так и будет действовать продвинутый ИИ, способный мгновенно находить системные бреши.
Защитой общества от ИИ-хакинга Цукерберг видит повсеместное внедрение открытого программного обеспечения. Главные аргументы Цукерберга в пользу этой позиции:
- Коллективная закалка: когда исходный код открыт, тысячи независимых специалистов тестируют его, выявляя и оперативно устраняя слабые места.
- Глобальный апгрейд: исправления безопасности не застревают внутри одной коммерческой корпорации, а мгновенно разворачиваются на серверах больниц, правительств и коммерческих компаний по всему миру.
- Баланс сил: открытые стандарты позволяют всей ИИ-индустрии развиваться синхронно, не допуская критического технологического отрыва одного игрока.
Цукерберг признаётся, что бессонными ночами его пугает вовсе не абстрактный бунт роботов, а вполне конкретный сценарий, при котором мощнейшим суперинтеллектом единолично завладеет субъект, не заслуживающий доверия, — например, враждебное государство-соперник или недобросовестная корпорация. По мнению Уэса Рота, в худшем случае монопольный контроль над самосовершенствующимся сильным ИИ (AGI) позволит такому игроку свергнуть любое правительство и буквально поработить человечество навсегда, заблокировав остальному миру возможность догнать лидера.
🕹️ Танк против двух миллионов римлян: метафора монополии на ИИ 8:50
Для наглядной демонстрации угрозы, которую несёт монополия на сверхинтеллект, Уэс Рот обращается к компьютерному симулятору Ultimate Epic Battle Simulator 2. Он описывает виртуальный эксперимент: один современный боевой танк «Шерман» выставляется против огромной армии из двух миллионов римских легионеров.
По мнению ведущего, этот единственный танк олицетворяет собой сильный искусственный интеллект (AGI) или искусственный сверхинтеллект (ASI), контролируемый одной закрытой группой или государством в условиях, когда у остального мира нет доступа к аналогичным технологиям. Двухмиллионная армия римлян — это всё остальное человечество. Насколько бы храбрыми, сильными и правыми ни были эти солдаты, у них нет ни единого шанса выжить против одной технологически совершенной машины. Накапливающийся экспоненциальный рост возможностей закрытого ИИ неизбежно приведёт к хаосу и тотальному доминированию монополиста.
Марк Цукерберг считает, что предотвратить этот сценарий можно только созданием качественного открытого ИИ, который станет индустриальным стандартом и выровняет правила игры. Он признаёт, что это классическая гонка вооружений. Цукерберг разделяет деструктивный контент в сетях на два типа:
- Неагрессивный (например, язык вражды): здесь ИИ развивается намного быстрее расистов или провокаторов, постепенно обучаясь снайперски точно отсекать нарушения, минимизируя ложные срабатывания, которые раздражают обычных пользователей.
- Высокотехнологичный (например, вмешательство спецслужб в выборы): враждебные государства используют передовые технологии и совершенствуют свои методы каждый год. Как только системы безопасности блокируют одну технику, враг придумывает новую.
По словам главы Meta, компания пока побеждает в этой гонке вооружений. Решение об открытии исходного кода будущих систем — Llama 4, Llama 5 или Llama 6 — будет приниматься на основе тщательного анализа поведения моделей и совместных исследований вопросов безопасности с мировым научным сообществом.
📊 Масштабирование данных и секрет обучения на коде 13:13
В официальном анонсе Meta раскрываются впечатляющие масштабы обучения Llama 3. Модели были натренированы на колоссальном массиве данных, превышающем 15 триллионов токенов. Для этого инженеры задействовали два недавно запущенных кастомных вычислительных кластера, каждый из которых содержит по 24 000 графических процессоров (GPU). Итоговый датасет оказался в 7 раз больше того, что использовался для создания Llama 2.
Уэс Рот обращает внимание на важнейшее признание Марка Цукерберга: изначально команда Meta вообще не планировала обучать Llama 3 написанию программного кода. Нейросеть создавалась под бытовые текстовые нужды — для интеграции умных чат-ботов в мессенджер WhatsApp, соцсеть Facebook и другие внутренние продукты корпорации.
Однако в процессе работы разработчики столкнулись с удивительным феноменом. Как только в обучающую выборку добавили массивный блок программного кода (его доля выросла в 4 раза по сравнению с предыдущим поколением ИИ), модель резко поумнела во всех остальных, абсолютно не связанных с программированием сферах. Обучение коду кардинально улучшило навыки общего логического мышления нейросети, её способность выстраивать цепочки рассуждений и успешно обобщать информацию.
🔄 Синтетические данные и «грязный секрет» индустрии 17:09
Обсуждая проблему нехватки качественной информации для обучения ИИ, Уэс Рот затрагивает тему синтетических данных — текстов и изображений, сгенерированных компьютерами. Ведущий иронично называет это «грязным секретом ИИ-индустрии», о котором топ-менеджеры предпочитают помалкивать.
Впервые данная концепция была детально описана в исследовательских работах Microsoft: чтобы натренировать качественную небольшую модель, можно взять массив ответов другой, гораздо более мощной ИИ-системы. Сегодня эта практика зашла невероятно далеко:
- Графика: графический генератор Adobe Firefly, позиционируемый как этичный продукт, тайно обучался на картинках, созданных нейросетью Midjourney.
- Текст: в сеть просочилась информация о том, что корпорация Google использовала ответы GPT-4 от OpenAI для тренировки собственных языковых моделей.
Марк Цукерберг соглашается, что в будущем грань между обучением и использованием ИИ размоется. Процесс тренировки супермоделей трансформируется в инференс — непрерывную генерацию умных синтетических данных базовой моделью, которые тут же скармливаются новому поколению систем.
Тем не менее, глава Meta скептически относится к идее бесконечного циклического самосовершенствования ИИ, способного привести к мгновенному взрыву интеллекта. По мнению Цукерберга, существуют жёсткие ограничения, накладываемые самой архитектурой сетей. Так, модель на 70 миллиардов параметров можно долго дообучать высокоценными токенами, и она станет немного лучше, но она никогда не догонит старшие модели на сотни миллиардов параметров. Истинный скачок происходит только в моменты фундаментальной смены поколений самой архитектуры ИИ (step function), которую невозможно симулировать простым прогоном синтетических данных по кругу.
В качестве подтверждения этого скепсиса Уэс Рот приводит свежий аналитический отчёт Стэнфордского университета о состоянии индустрии ИИ. Учёные выяснили, что многократное обучение нейросетей на синтетических данных прошлых поколений приводит к эффекту «накапливающегося искажения» и коллапсу модели. Эксперименты с генераторами картинок показали, что уже к 6-му и 7-му поколениям лица людей на изображениях начинают дико искажаться, покрываться неестественными цветными полосами и техническими артефактами, теряя всякое сходство с реальностью.
🔌 Физические ограничения и миф о 7 триллионах долларов 23:34
Марк Цукерберг убеждён, что опасения по поводу внезапного превращения ИИ в неуправляемое сверхразумное существо за одну ночь беспочвенны из-за суровых физических ограничений материального мира.
Первый непреодолимый барьер — это дефицит специализированного оборудования. Главным бутылочным горлышком индустрии остаются графические процессоры Nvidia, из-за бешеного спроса на которые рыночная стоимость чипмейкера взлетела до небес. Сейчас другие IT-гиганты лихорадочно пытаются проектировать собственные микросхемы, но на развёртывание производств уходят годы.
Вторым критическим фактором выступает энергетика. Цукерберг приводит конкретные цифры: средний крупный дата-центр сегодня потребляет порядка 50, 100 или 150 МВт электроэнергии. Однако для полноценного обучения ИИ следующих поколений потребуются ИИ-кластеры мощностью около 1 ГВт — а это сопоставимо с выработкой крупной атомной электростанции, работающей исключительно на нужды одной нейросети. И хотя распределённое обучение на нескольких удалённых площадках теоретически возможно, стабильность работы такой сети остаётся огромным открытым вопросом.
На фоне инфраструктурных споров Уэс Рот комментирует скандальное заявление главы OpenAI Сэма Альтмана о необходимости привлечения 7 триллионов долларов для перестройки мировой полупроводниковой индустрии. Ведущий поясняет, что слова Альтмана в СМИ были истолкованы неверно, будто он требует этот астрономический чек лично себе. Позже в подкасте Лекса Фридмана Альтман уточнил: речь шла о суммарных глобальных капитальных затратах (CapEx) всей мировой экономики — строительстве заводов, прокладке энергосетей и установке серверов, которые человечеству предстоит инвестировать коллективно на протяжении нескольких десятилетий.
📑 Подводные камни лицензии и архитектурные нюансы 25:40
Несмотря на общее восхищение релизом, Уэс Рот указывает на единственный, по его мнению, откровенно слабый показатель Llama 3 — размер контекстного окна, составляющий всего 8 000 токенов. На фоне современных коммерческих стандартов в 128 000 токенов у GPT-4 или фантастического окна в 1 миллион токенов у Gemini 1.5 Pro (способного находить «иголку в стоге сена» внутри гигантских массивов текста без потери точности), базовая цифра Meta выглядит блекло.
Также ведущий детально разбирает юридическое пользовательское соглашение Meta (Terms of Use). В лицензию внедрён жёсткий пункт:
Если какая-либо сторонняя организация использует исходные материалы Llama 3 для создания, обучения, тонкой настройки (fine-tune) или любого иного улучшения собственной ИИ-модели, предназначенной для дистрибуции, она в обязательном порядке должна включить бренд «Llama 3» в самое начало коммерческого названия своего продукта.
Это означает, что любая производная модель будет рекламировать Meta. Известный IT-предприниматель Эмад Мостак уже поиронизировал над этим правилом в соцсетях, в шутку заявив, что создаёт аниме-модель под названием «Llama 3 Waifu Husbando Woo Edition» и ищет ранних тестеров.
Из публикаций исследователя Астона Занга из команды Meta Generative AI становится известно, что удержание высокого показателя эффективного времени обучения ИИ-кластера из 16 000 GPU потребовало принципиально новых инженерных стратегий. В индустрии циркулируют слухи, что инженеры Microsoft сталкивались со схожими проблемами: при слишком близком физическом размещении тысяч плат ИИ пиковое энергопотребление оборудования угрожало стабильности локальных гражданских энергосетей.
Наконец, Астон Занг подтвердил важный технический факт: при проектировании Llama 3 компания Meta полностью отказалась от популярной ныне архитектуры Mixture of Experts (MoE — «смесь экспертов»), которая используется в GPT-4, Gemini 1.5 Pro и Mixtral. Meta сознательно сделала ставку на классическую плотную (dense) архитектуру, предпочитая добиваться эффективности за счёт беспрецедентного качества фильтрации обучающих данных, а не дробления модели на отдельные сегменты.
🏁 Заключение: реальные угрозы вместо терминаторов 28:40
Уэс Рот признаётся, что если бы ещё пару лет назад у экспертов спросили, какая именно корпорация станет главным и самым яростным защитником открытого ИИ на планете, никто бы не назвал Facebook и Марка Цукерберга. Тем не менее, сегодня именно Meta задаёт тренд на демократизацию технологий, пока конкуренты баррикадируются за закрытыми платными API.
Ведущий выражает полную солидарность с позицией Цукерберга касаемо безопасности. Общественные дискуссии об экзистенциальной угрозе ИИ, навеянные голливудскими фильмами о Терминаторе, уводят внимание людей от гораздо более осязаемых и пугающих опасностей.
Наибольший страх вызывает перспектива монопольного владения закрытым сверхразумом политической силой или авторитарным режимом. Обладая уникальным цифровым сверхоружием, они смогут намертво вшить в ИИ собственную идеологическую доктрину, сделав её доминирующей на планете. В такой конфигурации любое инакомыслие окажется технически невозможным, ведь у гражданского общества просто не будет альтернативного независимого ИИ-инструмента, чтобы сопротивляться цифровому диктату. Именно поэтому баланс между закрытыми исследованиями безопасности и развитием мощных open-source альтернатив критически важен — человечеству нельзя допустить появления «зомбированного монопольного сверхинтеллекта».