В новом видеообзоре популярный IT-блогер Янник Килчер (Yannic Kilcher) подробно разбирает научную статью, посвященную методологии Tree of Thoughts (ToT). Этот инновационный подход к управлению большими языковыми моделями объединяет генеративные способности ИИ с классическими алгоритмами поиска и программирования для решения сложных логических задач. В центре внимания исследователей из Принстонского университета и Google DeepMind находится переход от линейного генеративного мышления к структурированному древовидному поиску с возможностью отката назад.
🧠 Новая парадигма: от линейного текста к древовидному поиску 0:00
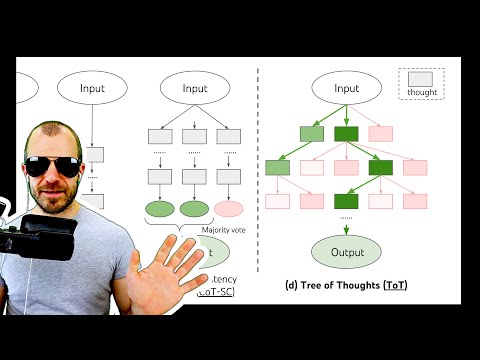
Традиционный подход к взаимодействию с большими языковыми моделями (Large Language Models) строится на линейном получении ответов: пользователь формулирует сложный запрос, а нейросеть пытается выдать готовое решение за один проход. Научная работа, подготовленная совместными усилиями исследователей из Принстонского университета и Google DeepMind, предлагает принципиально иную технику декодирования под названием Tree of Thoughts. Вместо того чтобы полагаться исключительно на точность стартового промпта, этот метод реализует явный поиск по дереву возможных вариантов решений.
Суть концепции Tree of Thoughts заключается в том, что языковая модель генерирует промежуточные шаги («мысли»), а затем сама же оценивает их жизнеспособность. Это позволяет алгоритму ветвиться, выбирать наиболее перспективные направления и, что критически важно, возвращаться назад (осуществлять бэктрекинг), если текущая ветка зашла в тупик. По мнению Янника Килчера, данный подход представляет собой важный шаг в направлении, где языковые модели смешиваются с классическим программированием и алгоритмами. Метод проектировался для специфических задач, где традиционное последовательное рассуждение оказывается неэффективным.
🛠️ Эволюция промптинга: от базовых запросов к «цепочкам мыслей» 1:17
Чтобы оценить значимость Tree of Thoughts, Янник Килчер предлагает рассмотреть эволюцию существующих методов промптинга. Самым простым и распространенным является так называемый метод «Вход-Выход» (Input/Output или I/O prompting). В рамках этой схемы модели передается описание задачи и, опционально, желаемый формат ответа.
В современной практике I/O-промптинг часто применяется для решения следующих стандартных задач:
- Форматирование ответов в структуру JSON для последующей автоматической обработки.
- Ограничение вывода рамками классификации, когда модель просят выбрать строго один вариант из четырех предложенных классов.
- Прямая генерация текстов (например, написание писем руководству) по заданному шаблону с приветствием и подписью.
Для фиксации жестких рамок вывода могут применяться техники ограниченного декодирования (restricted decoding), однако базовый I/O-метод всегда сводится к линейному запросу «вопрос — ответ».
Следующим этапом развития стал метод Chain of Thought (цепочка мыслей). Здесь инженеры заставляют нейросеть эксплицитно прописывать каждый промежуточный шаг рассуждений перед выводом финального ответа. Например, при создании песни модель сначала генерирует пошаговый план, фиксирует отдельные идеи на каждой строке и лишь затем собирает текст воедино. Практика показывает, что этот метод существенно повышает качество решения логических задач.
Янник Килчер отмечает, что в научном сообществе до сих пор нет полного консенсуса относительно причин эффективности Chain of Thought. Однако существуют две ключевые гипотезы:
- Эффект черновика (Scratchpad): модель получает возможность записывать свои промежуточные выводы на текстовый «холст», чтобы последующие токены могли ссылаться на уже сформулированные явные утверждения, а не удерживать всю логику в скрытых весах сети.
- Увеличение объема вычислений (Compute): поскольку генерация длинной цепочки мыслей требует декодирования большего числа токенов, нейросеть фактически тратит больше вычислительных ресурсов на обработку одного сложного запроса.
Дальнейшей модификацией линейных подходов стала концепция самосогласованности (Self-Consistency) в связке с Chain of Thought. Этот метод комбинирует генерацию цепочек рассуждений с процедурой голосования: система параллельно запускает несколько независимых сессий генерации, а затем выбирает наиболее популярный ответ путем мажоритарного голосования. Подобный подход эффективен преимущественно в задачах классификации. Также авторы упоминают метод итеративного улучшения (Iterative Refinement), когда к предыдущему ответу модели добавляется промпт с требованием критически пересмотреть результат и исправить ошибки.
🌲 Как устроен алгоритм Tree of Thoughts 6:14
В отличие от линейных цепочек, Tree of Thoughts развертывает полноценную древовидную структуру, состоящую из узлов и ветвей. Некоторые узлы признаются ошибочными и отсекаются (помечаются красным), тогда как перспективные ветви продолжают развиваться (помечаются зеленым). Процесс генерации дробится: вместо создания всего текста целиком, модель делает запрос к LLM трижды только ради получения самого первого шага рассуждений.
Архитектурно система ToT опирается на два ключевых внутренних компонента:
- Генератор мыслей (Thought Generator): отвечает за создание индивидуальных промежуточных шагов на основе контекста задачи и предыдущей истории рассуждений.
- Оценщик состояний (State Evaluator): проводит критический анализ сгенерированных шагов по отношению к исходной задаче.
Янник Килчер подчеркивает фундаментальное свойство систем машинного обучения: модели гораздо лучше справляются с оценкой соответствия двух сущностей друг другу, нежели с генерацией новой сущности с нуля. Оценка требует вывода простого числового балла или текстовой метки, что дает более чистый и надежный сигнал. Оценщик ToT может работать в режиме присвоения баллов (value) или выбора лучшего варианта через голосование (vote).
Если на определенном этапе Оценщик состояний признает все сгенерированные продолжения неудовлетворительными (ни один узел не проходит пороговое значение ценности), алгоритм осуществляет бэктрекинг. Программа возвращается вверх по дереву к предыдущему успешному узлу и начинает развивать альтернативную ветвь. Этот процесс представляет собой классический упорядоченный поиск по дереву (в ширину BFS или в глубину DFS), где приоритет отдается узлам с наивысшей текущей оценкой. Более сложные алгоритмы, такие как поиск по дереву Монте-Карло (MCTS), авторы статьи сознательно оставили для будущих исследований.
🧮 Эксперименты и практические задачи: игра в 24 и кроссворды 16:16
Для подтверждения эффективности Tree of Thoughts исследователи протестировали метод на трех сложных типах задач:
- Игра в 24 (Game of 24): математическая головоломка, где из четырех заданных чисел необходимо составить выражение, дающее в результате 24. В ToT модель промптят на генерацию промежуточных арифметических шагов, парсят вывод и оценивают вероятность успеха (хорошо, плохо, невозможно) с использованием few-shot примеров.
- Креативное письмо (Creative Writing): задача на написание связного текста. Здесь ToT показывает более высокие результаты как по метрикам автоматической оценки GPT-4, так и по отзывам людей, хотя обычные промпты с итеративным улучшением (Refine) приближаются к ToT по качеству.
- Мини-кроссворды (Mini Crosswords): заполнение буквенной сетки размером 5x5 на основе текстовых подсказок. Эта задача идеально подходит для демонстрации преимуществ бэктрекинга, поскольку неверно подобранное слово на пересечении быстро ломает всю структуру и требует отмены предыдущих шагов.
При тестировании на mini-crosswords базовый метод Chain of Thought выдавал промежуточные слова последовательно, пытаясь прийти к финальной сетке за один проход. Архитектура ToT на базе алгоритма поиска в глубину (DFS) действовала иначе: она двигалась по наиболее многообещающим подсказкам, жестко фиксируя буквы. Чтобы сделать поиск вычислительно подъемным, алгоритм ограничивали максимум 10 промежуточными шагами, переводя текущие заполненные буквы в строгие правила фильтрации для оставшихся слов. Для генерации кандидатов на каждый шаг делалось 5 запросов к модели.
⚖️ Критика автора и будущее «алгоритмического промптинга» 22:13
Несмотря на впечатляющие результаты Tree of Thoughts в тестах, Янник Килчер высказывает серьезную скептическую критику в адрес методологии экспериментов. Он отмечает, что авторы статьи фактически заложили готовый алгоритм решения кроссвордов внутрь внешней программной обвязки. Перевод промежуточных состояний в буквенные ограничения, фильтрация вариантов и управление структурой дерева выполняются жестким кодом, а не самой нейросетью.
По оценке Килчера, в данной конфигурации большая языковая модель была низведена до роли простого генератора случайных слов, заменяющего традиционный словарный поиск. Авторы защищают свой подход, указывая, что их глобальная цель — создание универсального инструмента решения задач (General Problem Solver), который исследует пространство мыслей с помощью эвристик. Однако Килчер считает, что до реализации честного универсального ИИ-решателя еще далеко.
По мнению ведущего, для того чтобы заявить о создании подлинного General Problem Solver, будущие исследования должны кардинально изменить подход:
- Необходимо полностью отказаться от написания кастомных, специфичных для каждой задачи промптов и парсеров.
- Управление деревом, эвристиками и анализом ошибок должно регулироваться единым мета-промптом верхнего уровня.
- Модель должна самостоятельно задавать себе вопросы формата: «Если бы я оценивал эту мысль, какие критерии я бы применил?».
Анализ абляционных исследований (ablation studies) в статье наглядно демонстрирует важность ключевых элементов ToT для итоговой эффективности. Базовые методы промптинга (I/O и CoT) практически не способны полностью решить кроссвордную игру целиком. Использование Tree of Thoughts радикально повышает шансы на успех. Примечательно, что если искусственно исключить из алгоритма ToT возможность прунинга (отсечения ветвей) или бэктрекинга (возврата назад), метрики успешности отдельных букв падают незначительно, но количество полностью решенных игр сокращается драматически. Это доказывает, что именно механизмы планирования определяют способность системы доводить сложные комплексные задачи до конца.
В долгосрочной перспективе Янник Килчер видит колоссальный потенциал не в попытках создать автономный ИИ-разум, а в интеграции языковых моделей в классические среды разработки. По его прогнозу, будущее за гибридными системами, где программист пишет стандартный детерминированный код, но делегирует узкие, слабоструктурированные задачи вызовам функций на базе LLм в рамках жестких алгоритмов поиска.




