В начале 2021 года компания OpenAI представила революционную нейросеть CLIP, способную связывать текст и изображения без предварительного обучения на конкретных задачах. Популярный ИТ-исследователь Янник Килчер (Yannic Kilcher) подробно разобрал научную статью разработчиков, объяснив принципы работы этой zero-shot модели. Его обзор раскрывает, как сопоставление картинок с описаниями из интернета позволяет обходить ограничения классических архитектур и достигать поразительной устойчивости к визуальным искажениям.
🚀 Удивительные возможности zero-shot классификации 0:00
Янник Килчер демонстрирует примеры работы классификатора, который без какого-либо предварительного дообучения (zero-shot) успешно распознает объекты на самых разных наборах данных. Модель со сверхвысокой точностью определяет гуакамоле, телевизионную студию, самолеты, автомобили конкретных марок и даже спутниковые снимки.
Примечательно, что вместо привычных коротких меток вроде «собака» или «машина», нейросеть оперирует развернутыми текстовыми описаниями, такими как «фотография гуакамоле, разновидности еды» или «центрированное спутниковое фото постоянных сельскохозяйственных угодий». По мнению Килчера, это указывает на принципиально новый и крайне перспективный подход к обучению компьютерного зрения со стороны OpenAI.
🧠 Суть технологии CLIP: отказ от жестких меток 2:54
Официальное название исследуемой публикации OpenAI — «Learning Transferable Visual Models from Natural Language Supervision», а саму модель авторы сокращенно называют CLIP. Она была выпущена одновременно со знаменитой генеративной системой DALL-E, однако если DALL-E создает изображения по текстовому описанию, то CLIP связывает их между собой негенеративным способом. Янник Килчер восторженно отзывается о качестве проработки обзора литературы в этой статье, отмечая, что авторы честно распределили заслуги между всеми предшественниками.
Главная мотивация создания CLIP — уход от тирании жестко размеченных датасетов. Традиционные подходы требуют колоссальных усилий по аннотированию картинок строго определенными классами. Исследователи традиционно используют фиксированные базы данных:
- ImageNet — содержит 1000 или 22 000 предопределенных категорий объектов.
- MNIST — классический набор из 10 цифр для распознавания рукописного ввода.
Создатели CLIP пошли иным путем: они собрали колоссальный массив пар картинок и текстов прямо из открытого интернета — соцсетей, платформ Pinterest, Flickr и других ресурсов, где пользователи сами пишут описания к своим публикациям. Это избавляет от необходимости вручную размечать каждый объект.
⚔️ Контрастивное обучение против предсказания текста 5:47
Первоначальная идея ИИ-сообщества заключалась в том, чтобы заставить нейросеть предсказывать точный текст подписи по имеющейся картинке. Теоретически, в промежуточных слоях такой сети должно было сформироваться глубокое понимание абстрактных концептов (например, «кошки»), иначе модель просто не смогла бы угадать нужное слово на выходе. На практике предсказание точного текстового описания оказалось слишком вычислительно тяжелым и неэффективным.
Несколько лучше показал себя метод «мешка слов» (bag of words), когда модель пыталась угадать лишь наличие ключевых слов в подписи без учета их строгого порядка. Однако настоящий прорыв, как наглядно демонстрирует Янник Килчер по графикам из статьи, произошел благодаря внедрению контрастивного метода обучения (contrastive method). Именно этот шаг позволил кардинально повысить эффективность и скорость обучения модели.
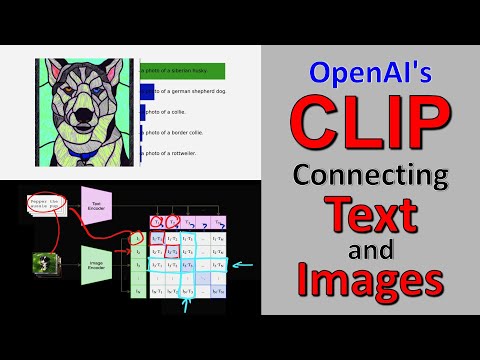
📊 Архитектура и математика матрицы сходства 13:34
Архитектура CLIP элегантна и строится вокруг одновременной обработки двух потоков информации. Модель включает в себя два независимых энкодера: один для изображений, другой для текста.
Процесс обучения в рамках одного мини-батча (пакета данных) строится следующим образом:
- Изображения из мини-батча пропускаются через энкодер картинок для получения латентных векторов.
- Тексты подписей параллельно кодируются текстовым трансформером в векторы той же размерности.
- Модель вычисляет скалярное произведение (inner product) для всех возможных пар в батче, формируя квадратную матрицу сходства.
- Алгоритм оптимизации максимизирует значения на главной диагонали (где картинка соответствует своей родной подписи) и минимизирует все остальные элементы матрицы.
Килчер поясняет, что это симметричная функция потерь (loss function), использующая кросс-энтропию и софтмакс (softmax) как в направлении картинок, так и в направлении текстов. Эффективность системы напрямую масштабируется от размера мини-батча: чем он больше, тем более детальные и точные представления формирует нейросеть.
🛠️ Промпт-инжиниринг и классификация «на лету» 19:07
На этапе инференса (применения) обученная CLIP легко превращается в классификатор без какого-либо дообучения весов. Человек-оператор формулирует текстовые подсказки (промпты) для целевых классов. Эксперименты показали, что вместо одиночного слова вроде «собака» гораздо эффективнее использовать фразы вида «фотография собаки», поскольку модель изначально обучалась на естественных текстах из интернета.
По мнению Янника Килчера, стандартные supervised-классификаторы склонны безвозвратно стирать уникальные черты объектов внутри одного класса, поскольку их единственная цель — выдать общую метку. CLIP же, ведомая богатым языковым контекстом, способна улавливать тончайшие нюансы — породу, возраст животного («щенок»), контекст кадра или даже конкретное имя, если оно закрепилось в данных. Это делает её незаменимым инструментом для управления другими нейросетями, например, для генерации изображений через StyleGAN.
В качестве текстового энкодера авторы использовали стандартный трансформер, забирая вектор токена конца предложения (end of sentence token). Для кодирования изображений OpenAI протестировали как различные вариации классического ResNet, так и передовой Vision Transformer (ViT).
📈 Результаты тестов и превосходство над ResNet-50 25:00
Разработчики провели масштабное сравнение zero-shot CLIP с классической моделью ResNet-50, обученной на ImageNet с помощью линейного зондирования (linear probing). Метод линейного зондирования предполагает, что веса основной сети «замораживаются», а обучается лишь финальный линейный слой под конкретную задачу. К удивлению ИИ-сообщества, во многих тестах на 16 различных датасетах CLIP без единого шага настройки превзошел полноценно обученную ResNet-50.
Особенно ярким триумфом стал датасет STL-10, где традиционно мало размеченных образцов на класс. Там zero-shot CLIP с ходу установил новый мировой рекорд точности (state-of-the-art). Тем не менее, Килчер призывает не идеализировать систему и указывает на её объективные слабые места. На узкоспециализированных задачах, таких как классификация опухолей на медицинских снимках или анализ сложных аэрофотоснимков, CLIP без дообучения справляется плохо. Даже простейший и банальный для глубокого обучения датасет MNIST вызвал у модели необъяснимые трудности.
🚗 Юмор разработчиков и феноменальная устойчивость 29:51
В ходе адаптации модели к существующим бенчмаркам авторы столкнулись с забавной технической проблемой: большинство старых датасетов содержали лишь цифровые ID классов (например, «тип 1», «тип 2») без понятных текстовых названий. Одному из ведущих авторов статьи, Алеку Рэдфорду, пришлось вручную прописывать текстовые соответствия. В официальной сноске исследователи с юмором отметили, что за время проекта Алек узнал о видах цветов и специфике немецких дорожных знаков гораздо больше, чем изначально планировал. Сам Янник Килчер даже создал по этому поводу мем с абсурдно детальным описанием знака запрета движения грузовиков.
Главным же практическим преимуществом CLIP Килчер считает её невероятную устойчивость к искажениям (robustness). Обычные модели, натренированные на ImageNet, драматически теряют в качестве, если им показать карандашный набросок (sketch) объекта, кадр в необычном ракурсе или зашумленный снимок. CLIP же сохраняет стабильность. Причина в том, что интернет-данные научили её абстрактным концептам: она понимает, что банан остается бананом как на глянцевом фото в журнале, так и в виде размытого кадра с камеры GoPro.
⚖️ Этические риски и скрытая сила формулировок 44:14
В финальной части статьи инженеры OpenAI уделили целых 3–4 страницы анализу этического влияния и безопасности модели (Broader Impact). При тестировании на специализированном датасете лиц FairFace модель без должного контроля со стороны человека демонстрировала пугающие расовые и социальные предвзятости. В ряде тестов CLIP некорректно сопоставляла фотографии людей определенных этнических групп с оскорбительными негуманными категориями (например, «шимпанзе», «горилла») или с криминальными терминами («вор», «преступник»).
Янник Килчер обращает внимание на критически важный вывод исследователей: этот всплеск ошибок происходил преимущественно на фотографиях молодых людей и детей. Как только авторы догадались просто добавить в список возможных текстовых меток категорию «ребенок» (child), уровень оскорбительных ложных срабатываний моментально сошел на нет. Этот пример наглядно доказывает, что грамотный промпт-инжиниринг в мультимодальных системах является не просто развлечением, а важнейшим элементом безопасности и предсказуемости искусственного интеллекта.




