В области машинного обучения долгое время доминировала парадигма «одна модель для всех задач» или дообучение (fine-tuning) гигантских весов под узкие нужды. В новом видео Янник Килчер обсуждает с Андреем Шмогеновым, исследователем из Google, архитектуру HyperTransformer, которая предлагает радикально иной путь: использование одной мощной нейросети для мгновенной генерации весов другой, более компактной и специализированной модели.
🧠 Что такое HyperTransformer: Концепция и цели 2:14
Разработка HyperTransformer (авторы: Андрей Шмогенов, Марк Сэндлер, Марк Владимиров) направлена на решение задач Few-Shot Learning (обучение на малом количестве примеров) . В отличие от классических подходов, где модель дообучается градиентным спуском, HyperTransformer за один проход (forward pass) генерирует веса для сверточной нейросети (CNN), которая сразу готова к работе .
Ключевые преимущества подхода, по мнению Андрея Шмогенова:
- Разделение сложности: Большая модель-метаучитель обладает огромными знаниями о мире, но на выходе выдает «худую» (lean) модель, которую легко развернуть на мобильном устройстве .
- Персонализация: Возможность мгновенно создать классификатор для конкретного пользователя (например, для распознавания лиц в личной фотогалерее), не требуя мощных вычислений на стороне клиента .
- Приватность: Использование в федеративном обучении, где веса могут генерироваться локально .
Янник Килчер отмечает, что архитектура удачно разрешает дилемму: модель для мета-обучения должна быть огромной, чтобы впитывать информацию о множестве задач, а модель для работы на устройстве — максимально легкой .
🛠️ Архитектура: Как генерируются веса 10:11
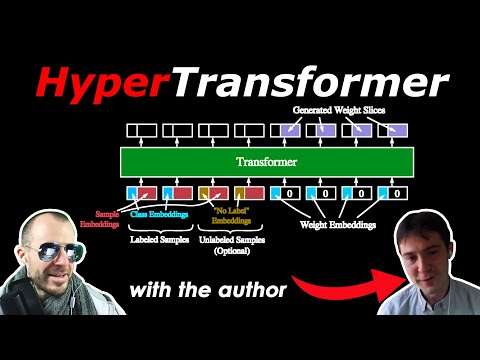
Процесс генерации весов в HyperTransformer устроен гораздо сложнее, чем простая регрессия чисел. Основная проблема нейросетей — они плохо «угадывают» точные значения весов, и ошибки быстро накапливаются . Чтобы обойти это, авторы применили стратегию послойной генерации .
Алгоритм работы HyperTransformer:
- Извлечение признаков: Исходные изображения (Support Set) пропускаются через Feature Extractor (обычно сверточную сеть), чтобы получить векторные представления .
- Генерация первого слоя: Transformer принимает эмбеддинги изображений и меток классов, выдавая веса первого слоя целевой модели .
- Обратная связь (Forward Prop): Данные прогоняются через только что созданный первый слой. Полученные активации снова подаются в HyperTransformer .
- Итерация: На основе новых активаций и исходных данных генерируется второй слой, и так до конца архитектуры .
Андрей Шмогенов подчеркивает, что такая авторегрессионная природа модели («что сгенерировали, то и используем для генерации следующего шага») критически важна для стабильности . Без учета активаций предыдущих слоев модель просто не справляется с точностью весов .
🧪 Почему именно Transformer? 22:29
Выбор архитектуры трансформера не случаен. Шмогенов выделяет два ключевых свойства:
- Инвариантность к перестановкам: Модели неважно, в каком порядке подаются примеры (котята и щенки) в обучающую выборку, результат будет идентичным .
- Механизм внимания: Авторы теоретически обосновали, что self-attention способен реализовать алгоритм классификации «внутри» своего прямого прохода .
Янник подробно разбирает концепцию: один слой внимания может работать как классификатор на основе усредненных эмбеддингов (centroid classifier) . Если запросы (queries) весов соответствуют ключам (keys) нужных классов, трансформер эффективно суммирует признаки объектов одного класса, формируя идеальную строку весов для финального слоя выходной модели .
📊 Полусенсорное обучение и результаты 30:24
HyperTransformer демонстрирует впечатляющие способности в Semi-Supervised Learning — когда у нас есть пара размеченных фото и много неразмеченных .
Как утверждает Андрей Шмогенов, двухслойный трансформер концептуально может реализовать алгоритм «ближайшего соседа» (Nearest Neighbor):
- Первый слой переносит метки с размеченных данных на близкие к ним неразмеченные эмбеддинги .
- Второй слой собирает информацию со всех (теперь уже условно «размеченных») данных и строит более точный классификатор .
Анализ карт внимания (attention maps) в приложении к статье подтвердил эту теорию: на первом слое веса смотрят только на размеченные примеры, а на втором — начинают учитывать неразмеченные, которые получили информацию на предыдущем этапе .
📈 Сравнение с iMAML и другими методами 5:06
Традиционные методы мета-обучения, такие как MAML или iMAML, ищут «удачную инициализацию» весов, которую потом нужно доучивать градиентным спуском . HyperTransformer же выдает готовые веса мгновенно.
В ходе экспериментов выяснилось:
- Для маленьких моделей генерация всех слоев дает значительный прирост точности по сравнению с мета-обучением классическими методами .
- Для крупных моделей наиболее эффективной оказалась гибридная стратегия: HyperTransformer генерирует только последний логит-слой, а нижние слои обучаются традиционно .
- Модель показала высокую стабильность при обучении через обычный SGD, несмотря на огромный вычислительный граф .
🚀 Будущее: От весов к стратегиям 1:16:15
Андрей Шмогенов видит потенциал технологии далеко за пределами классификации изображений. По его мнению, в будущем HyperTransformer сможет генерировать политики (policies) для роботов . Например, вы загружаете несколько фото нового робота и ландшафта, а модель мгновенно создает контроллер для ходьбы именно этого устройства в этих условиях .
Янник Килчер резюмирует, что хотя HyperTransformer пока не бьет рекорды ImageNet, он открывает путь к «динамическим моделям», которые создаются под задачу за миллисекунды .




