Британская лаборатория DeepMind представила инновационный подход к обучению агентов искусственного интеллекта планированию в условиях неопределенности. В своем новом обзоре популярный IT-блогер Янник Кильхер (Yannic Kilcher) подробно разбирает научную работу «Learning model-based planning from scratch», которая предлагает отказаться от жестко заданных эвристик в пользу полностью обучаемых моделей воображения. Ключевая идея исследования заключается в создании специального «менеджера», способного самостоятельно решать, когда нужно действовать в реальном мире, а когда — прогнозировать последствия в симуляции.
🧠 Что такое планирование на основе модели? 0:00
Традиционные подходы к обучению с подкреплением часто опираются на метод проб и ошибок непосредственно в реальной или виртуальной среде. Однако концепция планирования на основе модели (model-based planning) предлагает альтернативный путь. В этой схеме сама модель среды выступает в роли своеобразного «черного ящика». На вход ей подаются текущее состояние среды $S$ и планируемое действие $A$, а на выходе система выдает прогнозируемое новое состояние $S'$ и потенциальную награду $R$, которую агент может получить. Наличие подобной модели критически важно для эффективного заглядывания вперед.
До публикации этой работы исследователи преимущественно полагались на фиксированные эвристические методы поиска. Янник Кильхер приводит в пример классический алгоритм поиска A* (A-star), использующий предопределенные эвристики (например, расстояние между двумя точками в лабиринте) для обхода препятствий. Другим известным примером является поиск по дереву Монте-Карло (Monte Carlo Tree Search, MCTS), который лег в основу знаменитой системы AlphaGo. Главный недостаток этих технологий заключается в том, что сам процесс планирования в них не является обучаемым. Новая же работа DeepMind предлагает механизм, позволяющий ИИ самостоятельно учиться тому, как именно нужно планировать.
🛠️ Архитектура фреймворка: Роль «Менеджера» 1:47
В основе предложенного DeepMind фреймворка лежит центральный управляющий компонент, называемый «менеджером». Этот модуль выполняет функцию принятия решений высшего уровня и в каждый конкретный момент времени выбирает одну из двух базовых стратегий поведения:
- Действие (Act): Агент берет текущее состояние и всю историю предыдущих событий, выбирает конкретное действие и выполняет его непосредственно в реальном мире. На основе полученного опыта происходит классическое обучение с подкреплением.
- Воображение (Imagine): Вместо совершения реального шага менеджер задействует внутреннюю модель мира — модель воображения. Он симулирует действие, оценивает гипотетические последствия, заносит этот опыт в память и продолжает учиться на своих «фантазиях», не подвергая себя рискам реальной среды.
🗺️ Три стратегии воображения: От жестких правил к полной свободе 3:13
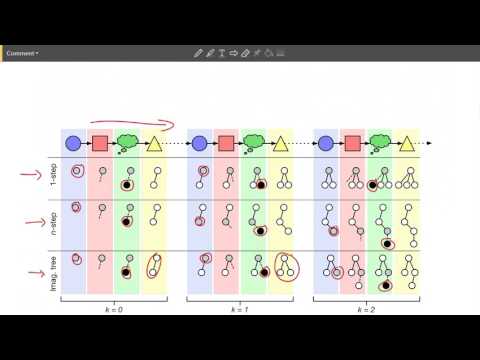
Для реализации симуляции авторы исследования разработали и протестировали три различных метода моделирования внутренних процессов. Они различаются по степени гибкости и глубине прогнозирования временных рядов.
🕒 Одношаговое воображение (One-step imagining)
Эта стратегия подразумевает, что агент всегда берет за основу текущее фактическое состояние мира (условную отправную точку) и делает от нее ровно один мысленный шаг вперед. Если полученный результат менеджеру не понятен или не удовлетворяет его, он снова возвращается к исходной точке и симулирует другое альтернативное действие. Этот цикл повторяется по внутренней шкале времени агента до тех пор, пока он не накопит достаточно уверенности для выполнения реального действия.
🚀 N-шаговое воображение (N-step strategy)
В отличие от предыдущего метода, N-шаговая стратегия не возвращает агента к началу после каждой попытки. Сделав первый мысленный шаг из реального состояния, менеджер выбирает новое, уже воображаемое состояние, и строит следующее предсказание на его основе. Таким образом, вместо веера коротких одношаговых прогнозов алгоритм выстраивает одну длинную цепочку взаимосвязанных событий, уходящую глубоко в будущее. При этом правила выбора базовой точки остаются жестко зафиксированными на программном уровне.
🌳 Дерево воображения (Imagination Tree)
Данный подход является наиболее продвинутым, так как представляет собой полностью обучаемую стратегию. Здесь менеджер получает абсолютную свободу: он может выбрать абсолютно любое ранее симулированное или реальное состояние из структуры данных и продолжить планирование именно от него. В процессе работы формируется разветвленное дерево гипотез. Менеджер анализирует узлы, выбирает наиболее перспективные ветви, углубляет их и, зафиксировав оптимальный маршрут, передает информацию обратно для совершения физического шага в реальности.
🚀 Практические эксперименты и ограничения алгоритма 7:30
Эффективность предложенных подходов проверялась в рамках нескольких экспериментальных сред. Одним из ключевых тестов стала задача управления космическим кораблем (spaceship task). ИИ требовалось маневрировать в пространстве, огибая астероиды, ради получения цифровой награды. На визуализациях траекторий четко видно, как система строит дерево воображаемых шагов. Агент симулирует несколько вариантов движения и, как только один из путей оказывается достаточно близко к целевой точке, прекращает тратить ресурсы на воображение и мгновенно переходит к выполнению действий в реальном мире.
Дополнительные тесты проводились в дискретных лабиринтах со множеством целей. В этих сценариях систему заставили оптимизировать не только внешнюю награду, но и внутренние издержки. Разработчики ввели понятие «бюджета на воображение», за рамки которого агент не должен выходить, чтобы процесс планирования не зацикливался бесконечно.
Тем не менее, Янник Кильхер обращает внимание на важное техническое ограничение эксперимента с лабиринтами. Из-за высокой вычислительной сложности авторы не стали использовать полноценный алгоритм «дерева воображения». Вместо этого они ограничили выбор менеджера дискретным набором вариантов на каждом шаге: совершить реальное действие, применить одношаговое или N-шаговое воображение. По мнению блогера, такое упрощение выглядит вполне обоснованным и разумным, поскольку иначе обучение нейросетевых моделей заняло бы слишком много времени. Практически все элементы системы реализованы на базе стандартных архитектур нейронных сетей.