В современном мире большие языковые модели (LLM) демонстрируют впечатляющие результаты, однако их тексты часто кажутся «пресными» или слишком предсказуемыми. По мнению Янника Кильхера (Yannic Kilcher), проблема кроется не в обучении, а в методах декодирования, которые заставляют ИИ выбирать наиболее вероятные, но скучные слова. В этом материале мы разберем предложенный исследователями метод типичного декодирования (Typical Sampling), который опирается на теорию информации, чтобы сделать речь нейросетей более человечной.
🧠 Проблема «идеальных» моделей: почему ИИ скучен? 0:00
Современные языковые модели обучаются с использованием функции максимизации правдоподобия (maximum likelihood objective). Это означает, что во время тренировки модель учится придавать огромный вес словам, которые наиболее вероятны в данном контексте. Однако при генерации текста это приводит к парадоксу: если модель всегда выбирает самые вероятные токены, результат получается «стерильным» и невыразительным.
Янник Кильхер отмечает, что человеческая речь устроена иначе:
- Мы не говорим только то, что максимально ожидаемо.
- Информативность речи напрямую связана с неожиданностью: чтобы сообщить что-то важное, мы должны время от времени использовать менее вероятные слова.
- Типичное декодирование (Typical Sampling) предлагает математически обоснованный способ сбалансировать «интересность» текста и его правдоподобие.
🛠 Обзор существующих методов декодирования 4:14
Прежде чем переходить к инновациям, автор видео разбирает стандартный инструментарий, используемый в NLP сегодня. Несмотря на низкую перпендикулярность (perplexity) — показатель того, насколько хорошо модель предсказывает текст — на практике результаты часто оказываются либо дегенеративными (повторы), либо слишком банальными.
Основные стратегии, которые подвергаются критике:
- Greedy Decoding (Жадное декодирование): Выбор самого вероятного слова на каждом шаге. Часто ведет к зацикливанию.
- Beam Search (Поиск по лучу): Алгоритм рассматривает несколько возможных путей генерации на несколько шагов вперед, сохраняя «топ» наиболее вероятных цепочек. По мнению Янника, этот метод еще хуже жадного в плане «скучности», так как он целенаправленно ищет максимально вероятные последовательности.
- Top-k Sampling: Модель ограничивает выбор только $k$ самыми вероятными токенами, а затем выбирает из них случайным образом.
- Nucleus Sampling (Top-p): Вместо фиксированного числа слов выбирается динамический набор токенов, суммарная вероятность которых достигает порога $p$ (например, 0.9).
Хотя стохастические методы (Top-k и Nucleus) работают лучше Beam Search, они всё равно фокусируются исключительно на «верхушке» распределения вероятностей.
📊 Теория информации: математика неожиданности 16:44
В основе нового метода лежит концепция из теории информации. Исследователи предполагают, что человек при общении старается передать максимум информации, минимизируя при этом риск того, что его не поймут.
Ключевые понятия:
- Информационное содержание (Information Content): Определяется как отрицательный логарифм вероятности: $I(y) = -\log p(y)$. Чем менее вероятно слово, тем больше информации оно несет.
- Энтропия (Entropy): Ожидаемое информационное содержание следующего слова. Если распределение вероятностей «пиковое» (очевидный выбор), энтропия низка. Если распределение «плоское» (много равновероятных вариантов), энтропия высока.
По словам Янника, если человек говорит только ожидаемые вещи, он почти не передает информации — это похоже на общение со «стереотипно скучным персонажем». Однако избыток неожиданных слов (низкой вероятности) ведет к потере смысла и грамматики.
⚖️ Гипотеза типичности: как говорят люди 25:18
Главная идея статьи Клара Мейстер (Clara Meister) и соавторов заключается в том, что в человеческом тексте информационное содержание каждого слова близко к ожидаемому информационному содержанию (условной энтропии). Это называется типичностью.
Аргументы в пользу гипотезы:
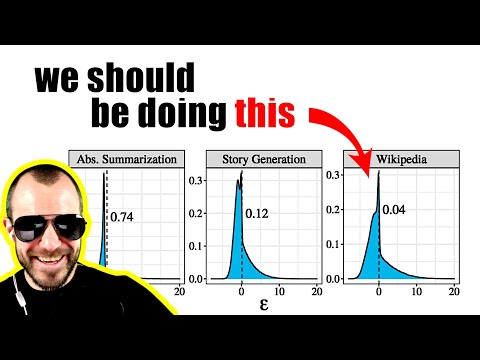
- Эмпирические данные: Анализ человеческих текстов показал, что распределение разницы между реальной информативностью слова и энтропией контекста очень узкое и сосредоточено около нуля.
- Типичные сообщения: В теории информации это сообщения, информативность которых соответствует энтропии источника. Важно, что максимально вероятное сообщение часто не является типичным, так как его информативность слишком низка.
Янник Кильхер подчеркивает, что Typical Sampling отсекает как слишком маловероятные слова (риск непонимания), так и слишком вероятные (риск скуки).
🚀 Как работает Typical Sampling 36:34
Алгоритм типичного декодирования работает следующим образом:
- Рассчитывается условная энтропия распределения вероятностей для следующего слова.
- Вычисляется информационное содержание каждого возможного слова в словаре ($-\log p$).
- Токены сортируются не по их вероятности, а по близости их информационного содержания к значению энтропии.
- Слова выбираются в этот «типичный набор» до тех пор, пока их суммарная вероятность не достигнет заданного порога $\tau$.
Если распределение вероятностей очень острое (есть один явный фаворит), метод автоматически возвращается к выбору наиболее вероятных слов. Но если контекст допускает множество вариантов (например, в сторителлинге), Typical Sampling выбирает более «интересные» продолжения.
🔬 Результаты и критика Янника Кильхера 40:49
Исследователи протестировали метод на задачах генерации историй и суммаризации текстов. Было обнаружено, что пороги $\tau$ для разных задач сильно различаются: для историй оптимальным оказался $\tau = 0.2$, а для суммаризации — $\tau = 0.95$.
Янник высказывает ряд сомнений относительно работы:
- Настройка параметров: Тот факт, что для разных задач нужны кардинально разные гиперпараметры, делает метод менее универсальным по сравнению с Top-k.
- Теоретический парадокс: Если модели обучаются на человеческих текстах (которые уже обладают свойством типичности), почему обычное сэмплирование из модели не воспроизводит это свойство автоматически?.
- Метрика расстояния: Ведущий не уверен, что использование абсолютного расстояния (модуля разницы) между энтропией и информативностью является лучшим решением.
Тем не менее, в качественном анализе Typical Sampling показал себя лучше: при суммаризации он выдавал меньше галлюцинаций, чем Nucleus Sampling, и сохранял больше важных деталей, чем Top-k. По мнению Кильхера, этот метод заслуживает внимания, особенно там, где важна диверсификация ответов.




