Исследователи из Google, Кембриджского университета, DeepMind и Института Алана Тьюринга представили архитектуру Performers, призванную решить главную проблему классических трансформеров — квадратичную сложность механизма внимания. Популярный IT-блогер и исследователь Янник Килчер подробно разобрал их научную работу, объяснив, как новый метод FAVOR+ позволяет обойти вычислительное «бутылочное горлышко» и работать со сверхдлинными последовательностями данных. По мнению автора канала, эта технология может стать очередным мини-прорывом в глубоком обучении, сравнимым с историческим переходом от сигмоид к активации ReLU.
🛑 Квадратичное проклятие трансформеров 0:00
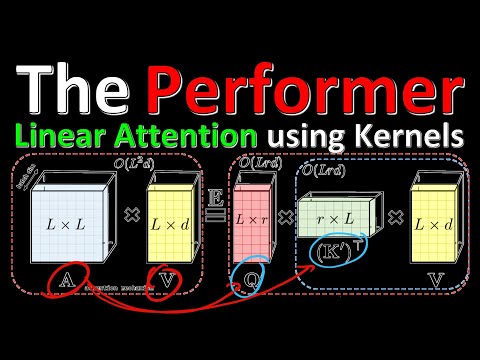
Классический механизм внимания (Attention), лежащий в основе архитектуры трансформеров, обладает фундаментальным ограничением: его требования к вычислительным ресурсам и памяти растут квадратично относительно длины входной последовательности. Если длина текста или размер изображения увеличиваются, стандартная матрица внимания $A$ размером $L \times L$ (где $L$ — длина последовательности) мгновенно перегружает память видеокарты.
Концептуально механизм работает со значениями запросов (Queries), ключей (Keys) и значений (Values). Формула вычисления выглядит следующим образом:
$$Attention(Q, K, V) = Softmax\left(\frac{QK^T}{\sqrt{d}}\right)V$$
Проблема кроется именно в операции Softmax. Из-за экспоненты внутри Softmax невозможно сначала перемножить матрицы ключей и значений, чтобы получить компактную матрицу $d \times d$ (где $d$ — скрытая размерность, которая обычно намного меньше длины текста $L$). Разработчики вынуждены сначала вычислять огромную матрицу $QK^T$ размером $L \times L$, что делает невозможным обработку сверхдлинных контекстов на стандартном оборудовании.
🧠 Ядерный трюк наоборот: суть метода Performers 11:45
Создатели Performers предложили изящное математическое решение этой проблемы, представив матрицу внимания через фреймворк ядерных методов (kernel methods). Элемент матрицы внимания можно рассматривать как функцию ядра от запроса и ключа. Янник Килчер отмечает, что в классическом машинном обучении ядерный трюк используется для неявного перевода данных из низкоразмерного пространства в высокоразмерное, поскольку явное отображение слишком сложно вычислить.
Однако в случае с Performers авторы применили этот подход в обратную сторону:
- Функция Softmax сама по себе является сложным нелинейным «зверем», вычисление которого напрямую не поддается декомпозиции.
- Если найти такое пространство признаков, в котором нелинейная функция Softmax эквивалентна простому линейному скалярному произведению, то задачу можно линеаризовать.
- Вместо вычисления Softmax от произведения исходных матриц, алгоритм явно переводит запросы и ключи в новое вероятностное пространство признаков (получая модифицированные матрицы $Q'$ и $K'$), где их перемножение линейно аппроксимирует искомую операцию.
Благодаря такому разложению становится возможным сначала перемножить трансฟонированную матрицу $K'$ со значениями $V$, получив промежуточную матрицу скромного размера, и лишь затем умножить результат на $Q'$. Вычислительная сложность падает с квадратичной $O(L^2)$ до линейной $O(L)$.
📐 От тригонометрии к экспонентам: борьба с высокой дисперсией 15:34
Для построения аппроксимирующей функции исследователи использовали случайные признаки (Random Features), концептуально близкие к случайным признакам Фурье (Random Fourier Features). Процесс выглядит так: в начале алгоритма из изотропного нормального распределения генерируется набор случайных векторов $\omega$, которые остаются фиксированными. Затем вычисляются скалярные произведения входных векторов с каждым из векторов $\omega$, а результаты пропускаются через детерминированные функции.
В первой конфигурации (обозначенной как тригонометрическая аппроксимация Softmax) авторы использовали функции синуса и косинуса. Математически этот метод давал несмещенную оценку, однако на практике он оказался непригоден для реального обучения нейросетей.
Причина провала тригонометрического подхода кроется в природе Softmax:
- Оригинальный Softmax всегда возвращает строго положительные значения, формируя распределение вероятностей.
- Синусы и косинусы неизбежно генерируют отрицательные значения при линейном скалярном произведении векторов случайных признаков.
- Когда реальные значения матрицы внимания близки к нулю (что происходит постоянно, так как Softmax разреживает матрицу и выделяет только самые важные связи), тригонометрическая аппроксимация начинает выдавать огромную дисперсию ошибок и уходить в отрицательные значения.
По словам Янника Килчера, это приводило к появлению отрицательных значений на диагонали нормализатора, что полностью ломало процесс обучения или приводило к катастрофическому падению точности моделей.
Чтобы исправить этот недостаток, в Performers внедрили алгоритм FAVOR+ (Fast Attention via Positive Orthogonal Random Features). Авторы нашли иное математическое разложение Softmax, использующее экспоненты и гиперболический косинус. Поскольку экспоненциальные функции генерируют исключительно положительные признаки, стабильность вычислений радикально возросла. На графиках ошибки четко видно, что в областях, близких к нулю, погрешность тригонометрического метода устремляется к бесконечности, в то время как ошибка метода FAVOR+ стабильно падает до нуля.
⚔️ Ортогонализация и замена Softmax на ReLU 40:08
Дополнительным улучшением во фреймворке FAVOR+ стало требование к ортогональности случайных векторов. Вместо того чтобы просто независимо сэмплировать векторы $\omega$ из гауссианы, авторы применили к ним процедуру ортогонализации Грама — Шмидта. Теоретически было доказано, что использование строго ортогональных случайных признаков снижает среднеквадратичную ошибку (MSE) аппроксимации по сравнению с независимым сэмплированием. Единственное ограничение метода — количество генерируемых случайных векторов должно быть меньше или равно исходной размерности скрытого пространства.
Янник Килчер проводит историческую параллель с развитием глубокого обучения. На заре нейросетей считалось естественным использовать сигмоиды и гиперболические тангенсы в качестве функций активации, поскольку они гладкие, дифференцируемые и биологически мотивированные. Однако затем появились простые функции ReLU, которые оказались стабильнее и эффективнее.
Аналогичным образом авторы Performers решили пойти дальше аппроксимации Softmax и попробовали полностью заменить его, подставив в формулу обычный ReLU. Полученная модификация Performer-ReLU показала отличные результаты в тестах, доказав, что фреймворк линеаризации внимания универсален.
⏳ Причинное внимание (Causal Attention) и префиксные суммы 50:07
Для авторегрессионных генеративных моделей (таких как семейство GPT) критически важно использовать причинное (causal) внимание, когда текущий токен может «смотреть» только на предшествующие ему токены, но не на будущие. В классическом трансформере это реализуется наложением нижней треугольной маски на матрицу $L \times L$. При линейном разложении Performers, где явная матрица $L \times L$ отсутствует, применить маску напрямую невозможно.
Эту проблему авторы элегантно решили с помощью механизма префиксных сумм (prefix sums). Вместо создания маски алгоритм последовательно накапливает произведения векторов ключей и значений:
- Вычисляется произведение $K'_1 V_1^T$.
- Для следующего шага вычисляется сумма $K'_1 V_1^T + K'_2 V_2^T$.
- Для третьего шага — $K'_1 V_1^T + K'_2 V_2^T + K'_3 V_3^T$, и так далее.
Когда в систему поступает новый запрос $Q'_t$, он просто перемножается с уже накопленной к текущему моменту префиксной суммой. Таким образом, причинность строго соблюдается, а вычисления по-прежнему выполняются за линейное время, что выгодно отличает Performers от более ранних не-до конца эффективных архитектур вроде Linformer.
📊 Эксперименты, код на JAX и практические результаты 43:20
Вся практическая часть исследования была реализована авторами на языке программирования JAX. Янник Килчер с иронией признался, что у него «нет устоявшегося мнения о JAX», добавив, что код в репозитории выглядит довольно «уродливым», но главное — он полностью рабочий.
Анализ логарифмического графика производительности (log-log plot) показал, что время выполнения прямого и обратного прохода в Performers идеально совпадает по наклону с базовой линией тождественной функции (Slope = 1), что подтверждает чистую линейную масштабируемость. В то же время графики стандартных трансформеров имеют наклон, равный двум, уходя резко вверх из-за квадратичной сложности. В ходе экспериментов на одной видеокарте NVIDIA V100 модель Performers смогла обработать контекст безумного объема — до $2^{18}$ (262 144) токенов, прежде чем выдала ошибку нехватки памяти (Out of Memory).
Среди ключевых преимуществ архитектуры выделяются следующие факты:
- Обратная совместимость: можно взять готовые веса (checkpoint) уже обученного стандартного трансформера, перенести их в архитектуру Performer и вернуть исходную точность после очень короткой стадии дообучения (fine-tuning).
- Превосходство над аналогами: Performers обошли по качеству и стабильности другие популярные модели с оптимизированным вниманием, такие как Reformer и Linformer. Линейный Linformer имеет свойство выходить на плато по качеству, в то время как Performers избегают этого за счет периодического обновления (пересэмплирования) случайных векторов $\omega$ между шагами вычислений.
- Новые сферы применения: благодаря способности обрабатывать гигантские последовательности, Performers открывают двери для масштабных исследований в биологии и медицине (например, для детального анализа длинных цепочек белков), а также для работы со сверхбольшими изображениями вроде ImageNet 64x64, которые ранее были слишком «тяжелыми» для классического внимания.
По мнению Янника Килчера, делать однозначный вывод о том, вытеснят ли Performers стандартные трансформеры повсеместно, пока рано, так как результаты одного документа требуют масштабной независимой проверки практикой. Тем не менее теоретическая база модели выглядит исключительно солидно и многообещающе.




