На конференции MSBuild компания OpenAI продемонстрировала прототип модели машинного обучения на базе архитектуры GPT-2, способной генерировать корректный код на языке Python. Популярный ИИ-исследователь Янник Килчер (Yannic Kilcher) подробно разобрал представленные технологические примеры, проанализировал логику работы нейросети и протестировал доступные коммерческие альтернативы. Автор пришёл к выводу, что индустрия стоит на пороге масштабных изменений в сфере автоматизации разработки.
🤖 Нейросетевой код от OpenAI: демонстрация на MSBuild 0:00
Компания OpenAI провела презентацию модифицированной версии языковой модели GPT-2. Главная особенность этого проекта заключается в том, что нейросеть обучалась не на текстовых массивах естественного языка, а на открытом исходном коде Python, собранном из репозиториев GitHub. Целью эксперимента было создание модели, способной самостоятельно дописывать программный код на основе минимального контекста от пользователя.
В качестве первого примера была показана базовая задача: человек вводит объявление функции def is_palindrome(s): и добавляет строку документации (docstring). Модель успешно генерирует оставшееся тело функции, реализуя стандартную проверку строки на палиндром. Янник Килчер отмечает, что скептики могут назвать этот результат простой интерполяцией уже существующего кода из публичных репозиториев.
Однако OpenAI продемонстрировала способность системы справляться с более сложными и уникальными запросами. Нейросети поставили задачу написать функцию, которая возвращает список индексов для элементов, являющихся палиндромами и имеющих длину не менее семи символов. По словам Янника Килчера, он лично пытался найти готовую аналогичную функцию на GitHub, но её там не существует. Тем не менее, модель успешно справилась с заданием, сгенерировав относительно сложное списковое включение (list comprehension). Система не только внедрила фильтр по длине строки, но и корректно сослалась на ранее созданную функцию is_palindrome.
Разбирая техническую сторону вопроса, Килчер выдвигает гипотезу, что генерация кода в данной модели не происходит исключительно «буква за буквой» или «слово за словом», как в стандартных текстовых ИИ. По его мнению, разработчики, скорее всего, наложили на модель ограничения абстрактных синтаксических деревьев (Abstract Syntax Trees, AST). Это позволяет гарантировать, что на выходе всегда будет получаться синтаксически валидный код Python, хотя распределение переменных и логика остаются целиком на усмотрение нейросети. Ведущий допускает, что показанные примеры могли быть тщательно отобраны (cherry-picked), но даже в таком виде результат выглядит впечатляюще.
🧠 Сложные контексты и логика скидок: симбиоз человека и машины 2:12
Во второй части презентации OpenAI усложнила задачу, предоставив модели контекст из двух классов данных (data classes) — Item (товар) и Order (заказ). Разработчик лишь объявил метод compute_total_order_price внутри класса Order, не добавляя никаких дополнительных описаний. Модель самостоятельно сгенерировала как тело метода, так и подробную строку документации.
Янник Килчер детально анализирует этот шаг и объясняет вероятный алгоритм работы системы:
- Из названия метода модель вывела суть строки документации — «рассчитать общую стоимость заказа».
- Поскольку метод принадлежит классу
Orderи принимает аргументself, нейросеть сопоставила эти данные. - В docstring модель добавила фразу «включая скидку на палиндромы» (including the palindrome discount), что, по мнению блогера, является результатом паттерн-матчинга с другими похожими функциями из обучающей выборки.
Тем не менее, на этом этапе проявилось ограничение ИИ: модель подсчитала общую стоимость товаров в цикле, но применила скидку абсолютно ко всем позициям. Нейросеть не смогла логически догадаться, что «скидка на палиндромы» должна распространяться только на товары, чьи названия являются палиндромами.
Чтобы исправить ошибку, программисты вручную скорректировали строку документации, явно указав: «применить скидку к товарам, чьё имя является палиндромом». После повторного запроса модель выдала безупречный результат: она добавила условие if is_palindrome(...), умножая цену на коэффициент скидки, а в противном случае прибавляя стандартную цену товара. Финальный штрих (формулу 1 - discount) дописал сам человек.
На основе этого примера Янник Килчер формулирует несколько важных выводов о будущем профессии:
- Искусственный интеллект в обозримом будущем не заменит программистов полностью.
- Технология будет развиваться в сторону симбиоза человека и машины, автоматизируя рутинные действия и предлагая варианты решений.
- Современное программирование содержит много избыточности: часто разработчики называют функцию говорящим именем, а затем дублируют его суть в строке документации из-за требований кодстайла. По мнению Килчера, если название функции очевидно, docstring не нужен, однако именно эта избыточность помогает ИИ-модели лучше понимать контекст и преобразовывать описания в готовую реализацию.
В завершение демонстрации модель успешно справилась с генерацией кода для печати чека, корректно применив форматирование строк Python. Килчер подчеркивает, что язык документации у программистов специфичен — они фактически описывают реализацию словами, что существенно сокращает дистанцию между естественным языком и исполняемым кодом.
🛠️ Альтернативы на рынке: практический тест Tabnine и Kite 5:54
Несмотря на то, что проект OpenAI на момент записи видео не был доступен широкой публике в виде масштабного продукта, Янник Килчер напоминает, что на рынке уже существуют коммерческие инструменты автодополнения кода на базе машинного обучения. Среди них автор выделяет два основных решения:
- Kite — специализированный ИИ-помощник для разработчиков.
- Tabnine — плагин, который Килчер использует в своей повседневной работе.
Ведущий с сожалением отмечает, что оба этих продукта имеют закрытый исходный код, что накладывает определённые ограничения на их аудит сообществом. В основе работы данных систем также лежат языковые модели типа GPT, обученные на больших массивах исходного кода. Они способны угадывать намерения программиста, подставляя локальные переменные в контекст выполнения. Килчер упоминает существующие в сети автогенерируемые обзоры-сравнения Kite и Tabnine, призывая скептически относиться к их текстовым версиям и доверять реальным видеотестам.
💻 Живой тест автодополнения: от структуры данных до циклов 7:01
Чтобы продемонстрировать возможности Tabnine, Янник Килчер открывает проект, в котором он ранее в прямом эфире писал классификатор тональности текста с использованием библиотек Hugging Face. В ходе интерактивного тестирования плагина автор проверяет, как система справляется с генерацией различных математических и логических конструкций.
Сначала Килчер пытается рассчитать функцию потерь:
- При попытке ввести «square loss» (квадратичная ошибка) Tabnine предлагает оценочную функцию потерь.
- Несмотря на отсутствие некоторых переменных в текущей области видимости, плагин предлагает варианты автодополнения для
train_lossиvalidation_loss.
Для чистоты эксперимента ведущий создаёт абсолютно новый пустой файл. При импорте модуля os и вводе конструкции if __name__ == система мгновенно дописывает стандартное условие __main__ и предлагает создать функцию main(), предугадывая типичные паттерны написания скриптов на Python.
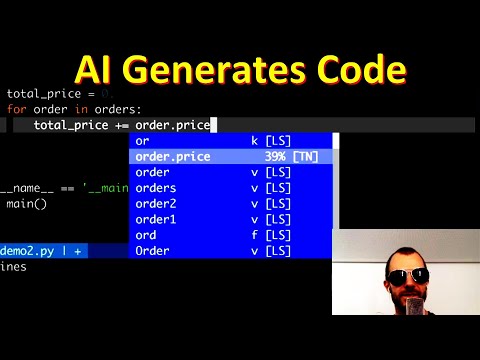
Далее Килчер воспроизводит пример OpenAI с классами данных, создавая структуру Order с полями price: float и name: str. При создании экземпляра объекта order1 и начале ввода команды print Tabnine сразу предлагает напечатать свойство order1.price. Когда в коде появляется массив orders, состоящий из двух заказов, и инициализируется переменная total_price = 0, плагин демонстрирует высокую точность предсказаний. Стоит автору написать ключевое слово for, как Tabnine автоматически дописывает всю конструкцию цикла: for order in orders:. На следующей строке ИИ безошибочно генерирует операцию инкремента: total_price += order.price. При выводе результата переменная total_price также предлагается автоматически.
В финале видео Янник Килчер выражает крайнюю заинтересованность тем, насколько далеко разработчики смогут продвинуть технологии генерации кода. По его мнению, сфера контекстного инжиниринга в программировании находится в самом начале своего пути, и в ближайшие годы нас ожидает появление значительно более мощных инструментов.




