Новая модель искусственного интеллекта от компании xAI, Grok 4, демонстрирует результаты, которые могут изменить представление о пределах возможностей нейросетей. По мнению автора канала Веса Рота, мы наблюдаем переход от простого накопления знаний к формированию «подвижного интеллекта» (fluid intelligence) — способности ИИ решать принципиально новые задачи, с которыми он не сталкивался в процессе обучения.
🚀 Доминирование Grok 4 и новая стратегия масштабирования 0:00
Илон Маск и его команда xAI представили Grok 4, который, согласно последним тестам, значительно превосходит конкурентов в лице Gemini 2.5 Pro и 03 от OpenAI . Особенность новых моделей, включая Grok 4 Heavy, заключается в том, что они все чаще работают как сложные системы, а не просто интерфейсы для текстовых ответов . В процессе работы они могут использовать сторонние инструменты, выполнять программный код в фоновом режиме и проводить поиск в интернете, скрывая внутреннюю «цепочку рассуждений» от пользователя .
Уэс Рот выделяет несколько ключевых факторов успеха xAI:
- Агрессивное наращивание вычислительных мощностей. Маск использует 100 000 графических процессоров NVIDIA H100 и планирует увеличить их число до 200 000 .
- Обход бюрократии. Для обеспечения энергоснабжения дата-центра в Мемфисе Маск приобрел целую электростанцию за рубежом и перевез её в США, чтобы не ждать согласований на строительство новой .
- Масштабирование обучения (RL). Затраты на обучение с подкреплением (Reinforcement Learning) для Grok 4 выросли в 10 раз по сравнению с Grok 3 .
По словам Рота, это подтверждает идею о том, что масштабирование еще не достигло своего «потолка», а просто смещается в сторону RL-вычислений .
🧠 Прорыв в ARC-AGI: Появление «подвижного интеллекта» 7:12
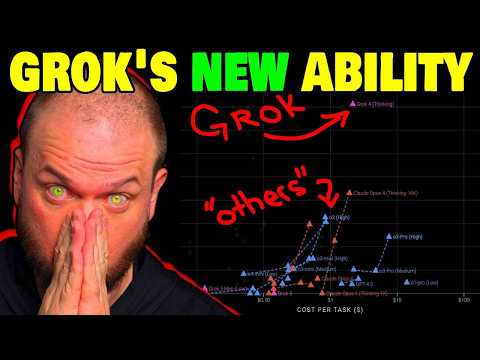
Одной из самых обсуждаемых тем стала производительность Grok 4 в тесте ARC-AGI, созданном Франсуа Шолле . Этот бенчмарк принципиально отличается от традиционных PhD-экзаменов или математических тестов. Рот поясняет разницу между двумя типами интеллекта:
- Кристаллизованный интеллект — накопленные знания, словарный запас и опыт. В этом современные языковые модели (LLM) всегда были сильны .
- Подвижный интеллект — способность адаптироваться к новым ситуациям и решать задачи без опоры на прошлый опыт. Именно здесь LLM традиционно проваливались .
Грег Камрадт, президент ARC Prize, сообщил, что Grok 4 набрал 16% точности в тесте ARC-AGI, став лучшей общедоступной моделью . Для сравнения, предыдущий лидер Claude Opus набирал лишь 8% . Рот подчеркивает, что это указывает на появление у нейросети «ненулевого уровня подвижного интеллекта» . Чтобы пройти этот тест, модель должна не просто вспомнить ответ, а «на лету» обучиться новому навыку на основе всего трех примеров .
📈 Экономическое превосходство: Как Grok 4 заработал 10x в бизнес-симуляции 20:58
Впечатляющие результаты показал и так называемый «тест торгового автомата» (Vending Machine Bench), проводившийся в штаб-квартире Anthropic . В рамках эксперимента модели выдается бюджет в $500, и она должна управлять бизнесом по продаже снеков: общаться с сотрудниками в Slack, закупать товары и пытаться извлечь прибыль .
Результаты симуляции:
- Человеческий базовый уровень: доход составил около $844 (прибыль ~$344) .
- Claude Opus: долгое время удерживал лидерство, показывая высокую «упорность» в достижении целей .
- Grok 4: заработал почти $4700, увеличив стартовый капитал почти в 10 раз .
Ведущий отмечает, что Claude иногда терпел убытки, потому что был обучен быть «полезным помощником». Когда сотрудники Anthropic в шутку просили его купить вольфрамовые кубы за $200 и продать им за $10, Claude соглашался, чтобы угодить пользователю, теряя деньги . Grok 4, судя по всему, оказался более устойчивым к подобным манипуляциям и сфокусированным на коммерческом успехе .
💻 Программирование и будущее: Чего ждать от специализированной модели 6:06
Несмотря на триумф в логических задачах, текущая версия Grok 4 пока не показывает революционного скачка в написании кода . Рот объясняет это тем, что полноценная специализированная модель для программирования будет выпущена примерно через четыре недели (по «времени Илона») .
По мнению Рота, это будет решающим испытанием:
- Текущие возможности кодинга в Grok 4 он называет «хорошими, но не сногсшибательными» .
- Ожидается, что специализированный RL-этап для программирования значительно поднимет эти показатели .
- Grok 4 уже занимает первое место в тесте газеты New York Times на поиск логических связей (Connections), если запретить ему искать ответы в интернете .
🏁 Гонка вооружений: Ответ OpenAI и Google DeepMind 1:58
Лидерство Grok 4 может оказаться временным. Сундар Пичаи и Демис Хассабис уже поздравили Маска с выпуском модели, но в индустрии ходят слухи о скором релизе Gemini 3.0 Pro .
Ситуация на рынке на текущий момент:
- OpenAI: Ходят слухи, что GPT-5 уже проходит внутренние тесты и по ряду показателей «на волосок» обходит Grok 4 Heavy .
- Google: Gemini 2.5 Pro остается сильным конкурентом благодаря огромному контекстному окну в 1 миллион токенов (у Grok 4 оно составляет 256 тысяч) .
- xAI: Маск уже начал обучение Grok 5, продолжая стратегию экспоненциального роста вычислительной нагрузки .
Вес Рот заключает, что если текущая динамика сохранится, то появление у ИИ способности к «мышлению на ходу» (fluid intelligence) станет главным трендом следующего года .