При проектировании свёрточных нейросетей разработчики регулярно сталкиваются с необходимостью выбора оптимального размера фильтра для извлечения признаков. Известный исследователь в области искусственного интеллекта и основатель платформы DeepLearning.AI Эндрю Нг подробно разбирает концепцию архитектуры Inception, которая предлагает радикальное решение — отказаться от мук выбора в пользу одновременного использования всех возможных конфигураций слоёв. В материале детально рассматривается не только базовая структура этого модуля, но и изящный математический трюк, позволяющий снизить его огромную вычислительную сложность в десять раз без потери эффективности.
🧩 Дилемма проектирования: Зачем делать выбор, если можно взять всё? 0:00
При создании классических свёрточных нейросетей (CNN) инженерам приходится принимать множество волевых решений на каждом слое. Одно из самых сложных — выбор правильного размера фильтра. Что сработает лучше для конкретной задачи: фильтр $1 \times 1$, $3 \times 3$ или, может быть, $5 \times 5$? Или вместо свёртки на данном этапе эффективнее применить слой пулинга (pooling layer)?
Архитектурный подход под названием Inception полностью меняет эту парадигму. Вместо того чтобы выбирать какой-то один тип слоя и фиксировать его, модуль Inception предлагает параллельно запустить все возможные варианты. Несмотря на то, что это существенно усложняет общую архитектуру сети, на практике подобный метод демонстрирует выдающиеся результаты.
Для демонстрации принципа работы Эндрю Нг предлагает рассмотреть конкретный пример. Предположим, что на вход в слой нейросети поступает тензор (активационный объем) с размерностью $28 \times 28 \times 192$. Вместо выбора одного типа операции сеть Inception применяет к этому объёму сразу четыре параллельных пути обработки.
🏗️ Анатомия базового модуля Inception 0:39
Внутри одного слоя Inception входные данные параллельно распределяются по четырём независимым каналам обработки:
- Канал свёртки $1 \times 1$: преобразует исходный объём и на выходе выдаёт тензор размером, например, $28 \times 28 \times 64$.
- Канал свёртки $3 \times 3$: чтобы сохранить пространственные размеры (высоту и ширину) неизменными и равными $28 \times 28$, здесь применяется так называемая «одинаковая» свёртка (same convolution). На выходе формируется объём $28 \times 28 \times 128$.
- Канал свёртки $5 \times 5$: работает по тому же принципу сохранения пространственного разрешения («same padding») и выдаёт результат с размерностью $28 \times 28 \times 32$.
- Канал пулинга (Pooling): выполняет операцию максимального или среднего объединения. Для того чтобы его выход совпал по размерности с остальными каналами, применяется нестандартный подход — пулинг с одинаковым паддингом (same padding) и шагом (stride), равным 1. На выходе получается объём $28 \times 28 \times 32$.
После того как все четыре операции завершены, нейросеть просто склеивает (конкатенирует) полученные результаты вдоль третьей оси — оси каналов. Сложив глубину всех выходов ($64 + 128 + 32 + 32$), мы получаем итоговый объём с размерностью $28 \times 28 \times 256$.
Таким образом, модуль принимает тензор с 192 каналами, а возвращает единый блок на 256 каналов. Как подчёркивает Эндрю Нг, суть идеи заключается в том, что инженеру больше не нужно угадывать идеальные параметры — сеть сама в процессе обучения определит, какие комбинации весов и фильтров ей использовать.
Авторами этой концепции является интернациональная команда исследователей, в которую вошли Кристиан Сегеди, Вэй Лю, Янчин Цзя, Пьер Сермане, Скотт Рид, Драгомир Ангелов, Думитру Эрхан, Винсент Ванхук и Андрей Рабинович.
📉 Проблема вычислительной сложности: Цена «всеядного» подхода 3:37
При всей своей привлекательности базовый модуль Inception сталкивается с серьёзным препятствием — колоссальной вычислительной стоимостью. Чтобы наглядно продемонстрировать проблему, Эндрю Нг предлагает рассчитать количество операций умножения, необходимых для работы всего одного лишь сегмента — свёртки $5 \times 5$ из предыдущего примера.
Напомним исходные данные для этого вычисления:
- Входной блок данных: $28 \times 28 \times 192$.
- Параметры слоя: 32 фильтра размером $5 \times 5$ с сохранением размерности (same convolution).
- Выходной блок данных: $28 \times 28 \times 32$.
Чтобы получить итоговый тензор, нам нужно рассчитать ровно $28 \times 28 \times 32 = 25\,088$ отдельных чисел. Каждое из этих чисел формируется в результате применения одного фильтра размерностью $5 \times 5 \times 192$ (так как глубина фильтра обязана совпадать с количеством каналов входного слоя).
Следовательно, для вычисления одного значения требуется выполнить $5 \times 5 \times 192 = 4\,800$ умножений. Чтобы узнать совокупную вычислительную нагрузку, перемножим эти величины:
$$25\,088 \times 4\,800 = 120\,422\,400$$
Таким образом, для работы одной только ветки с фильтром $5 \times 5$ компьютер должен выполнить более 120 миллионов операций умножения. Современная техника способна справиться с таким объёмом вычислений, однако в масштабах глубоких многослойных сетей этот подход оказывается слишком «прожорливым» и неэффективным.
🍾 Горлышко бутылки: Оптимизация с помощью свёрток 1x1 5:47
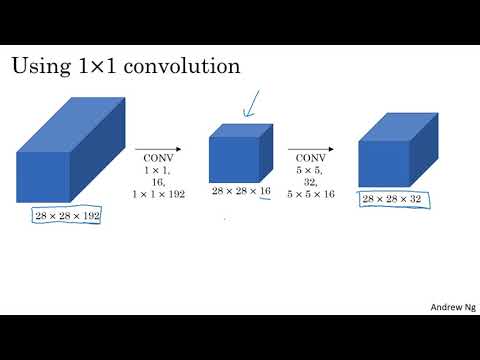
Для решения проблемы перегрузки авторы архитектуры применили оригинальный метод оптимизации: внедрение промежуточных свёрток $1 \times 1$, которые также называют слоями «узкого горлышка» (bottleneck layers). Название вдохновлено формой обычной стеклянной бутылки, у которой горлышко является самой узкой частью. В контексте нейросетей такой слой временно сжимает представление данных, уменьшая количество каналов, перед тем как снова его увеличить.
Давайте посмотрим, как изменится схема вычислений, если между входными данными и целевым фильтром $5 \times 5$ установить «узкое горлышко»:
- Этап сжатия (свёртка $1 \times 1$): Входной объём $28 \times 28 \times 192$ сначала пропускается через 16 фильтров размером $1 \times 1$. Размерность промежуточного тензора падает до $28 \times 28 \times 16$.
- Этап основной свёртки ($5 \times 5$): Теперь тяжеловесный фильтр $5 \times 5$ (в количестве 32 штук) применяется не к огромному исходному массиву со 192 каналами, а к этому усечённому промежуточному блоку с 16 каналами. На выходе мы получаем всё тот же целевой объём — $28 \times 28 \times 32$.
Проведём пошаговый аудит новой стоимости вычислений. Сначала посчитаем затраты на первый этап (свёртка $1 \times 1$): нам нужно заполнить матрицу $28 \times 28 \times 16$, где для каждого элемента требуется $1 \times 1 \times 192$ умножения.
$$28 \times 28 \times 16 \times 192 \approx 2,4\text{ млн операций}$$
Теперь рассчитаем стоимость второго этапа (свёртка $5 \times 5$ поверх сжатых данных): нам нужно получить итоговые $28 \times 28 \times 32$ чисел, но глубина каждого фильтра теперь составляет всего 16 (вместо 192).
$$28 \times 28 \times 32 \times 5 \times 5 \times 16 \approx 10,0\text{ млн операций}$$
Суммируя затраты на оба шага ($2,4\text{ млн} + 10,0\text{ млн}$), мы получаем итоговую цифру — 12,4 миллиона операций умножения. Число необходимых операций сложения при этом сокращается пропорционально и примерно соответствует количеству умножений.
Сравнивая этот результат с первоначальной архитектурой, мы видим колоссальную разницу: вычислительные затраты упали со 120 миллионов до 12,4 миллионов — то есть практически ровно в 10 раз.
По словам Эндрю Нг, у многих разработчиков возникает резонное опасение: не вредит ли столь радикальное искусственное уменьшение объёма признаков (со 192 до 16 каналов) общей точности и предсказательной способности модели? Однако создатели алгоритма экспериментально доказали, что при правильном проектировании слоя «узкого горлышка» это промежуточное сжатие не оказывает негативного влияния на финальное качество работы нейросети, но при этом колоссально экономит машинное время и ресурсы.




