Разработчики искусственного интеллекта давно научились обучать агентов побеждать в играх с фиксированным набором действий, таких как Atari или шахматы. Однако текстовые квесты, где мир описывается естественным языком, а варианты ходов практически бесконечны, до сих пор представляют огромную сложность для ИИ. Известный исследователь искусственного интеллекта Янник Килчер (Yannic Kilcher) разобрал научную работу Леонарда Адольфса (Leonard Adolphs) и Томаса Хофманна (Thomas Hofmann), представивших LeDeepChef — инновационного агента глубокого обучения с подкреплением, способного адаптироваться к целым семействам текстовых игр и успешно готовить виртуальные блюда по незнакомым рецептам.
🎮 Особенности текстовых квестов и кулинарный хаос 0:42
Текстовые игры значительно отличаются от классических сред для обучения с подкреплением вроде Pong или Starcraft. В рассматриваемом авторами семействе игр главная цель агента — приготовить блюдо по рецепту, разыскав книгу, собрав ингредиенты и обработав их должным образом. Проблема заключается в том, что входные данные поступают в виде неструктурированного, художественного и порой избыточного текста.
Игра может описывать окружение очень витиевато, используя синонимы. Вместо сухого списка предметов агент видит фразы в духе «вы поворачиваетесь и замечаете стол» или «перед вами закрытая духовка».
При этом критически важно распознавать не просто наличие объекта, но и его текущее состояние. Если в комнате лежит «нарезанный и обжаренный острый красный перец», модель должна чётко зафиксировать маркеры «нарезанный» (sliced) и «обжаренный» (fried), поскольку рецепты требуют строго определённой кондиции продуктов.
Ещё одно ключевое отличие от традиционных игр — колоссальное пространство возможных действий. В играх Atari у агента есть фиксированный набор из нескольких кнопок, тогда как в текстовом квесте команды нужно вводить вручную строками текста. Даже при ограничении словаря комбинаторная сложность возможных фраз огромна, ведь модель не знает заранее, какие именно ингредиенты ей встретятся.
Дополнительные трудности, по словам Янника Килчера, создают следующие игровые механики:
- Ограниченный инвентарь: агент не может носить с собой все предметы сразу, ему приходится выбрасывать ненужные вещи, чтобы освободить место.
- Навигация между комнатами: игра начинается в случайном помещении, двери между ними могут быть закрыты, и их необходимо предварительно открывать.
- Инструментальные зависимости: невозможно нарезать перец, если в комнате или инвентаре нет ножа, и нельзя пожарить лук без плиты или сковороды. Если нужного инструмента нет, агенту приходится переносить ингредиенты в другие локации.
Наконец, главная сложность заключается в необходимости генерализации. Тестовый набор данных содержит ингредиенты и рецепты, которые агент вообще не видел во время обучения. Именно поэтому речь идет о «семействе» игр — условия меняются от эпизода к эпизоду.
🧠 Архитектура LeDeepChef: от текста к вектору состояния 7:32
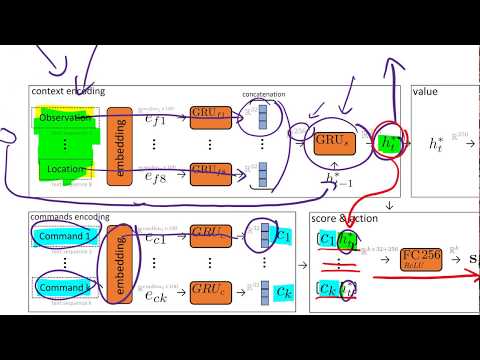
На самом верхнем уровне архитектуры LeDeepChef находится агент глубокого обучения с подкреплением (DRL), управляемый нейросетевой стратегией (policy). Поскольку перебрать все возможные текстовые команды физически невозможно, одной из главных заслуг авторов работы Янник Килчер считает алгоритм сужения пространства действий до $K$ разумных вариантов. Стратегия выбирает лучшее действие именно из этого ограниченного списка.
Каждая из доступных $K$ команд кодируется с помощью рекуррентных нейросетей GRU (Gated Recurrent Unit) в 32-мерный вектор. Затем эти векторы объединяются с комплексным 256-мерным вектором текущего состояния игры и передаются в полносвязную нейросеть, которая распределяет вероятности выбора действий.
Сам вектор состояния формируется на основе объединения текстовой информации. Текущее наблюдение (observation) разбивается на восемь независимых текстовых потоков:
- Непосредственное текстовое описание от игрового движка (например, «Вы на кухне, пахнет специями...»).
- Список недостающих предметов для рецепта.
- Список лишних предметов, находящихся в инвентаре.
- Результат выполнения последней команды осмотра комнаты (look).
- История предыдущих команд агента для предотвращения зацикливания.
- Прогноз необходимых инструментов для выполнения текущих задач.
- Список уже обнаруженных и посещённых локаций.
- Название текущей комнаты.
Каждая из этих восьми текстовых строк пропускается через собственную рекуррентную сеть, выдающую 32-мерный вектор, после чего они конкатенируются в единый 256-мерный эмбеддинг. По мнению Килчера, при правильном обучении этот вектор вмещает абсолютно всю релевантную для агента информацию о мире.
Для учёта временного контекста полученный вектор передаётся в ещё одну рекуррентную сеть, сохраняющую историю состояний. Это позволяет агенту понимать контекст («я только что вошёл в эту комнату и ещё не успел забрать отсюда вещи»), основываясь не только на сиюминутном кадре, но и на цепочке прошлых событий.
Полученное скрытое состояние используется как для принятия решений в сети стратегии, так и в сети ценности (value network). Сеть ценности решает классическую для RL задачу — предсказывает суммарную будущую награду из текущего положения. Килчер сравнивает это с оценкой позиции на шахматной доске: если вы сильно впереди по материалу, ценность состояния высока.
📋 Рецептурный менеджер и сила контролируемого обучения 20:05
Ключевым внутренним компонентом системы является подмодель «рецептурного менеджера» (recipe manager). Она принимает на вход текст кулинарной книги и содержимое инвентаря агента. На выходе модель генерирует чёткую структурированную таблицу, где для каждого ингредиента указано, отсутствует ли он в инвентаре, и какие кулинарные шаги (например, нарезка или обжарка) с ним ещё необходимо выполнить.
В качестве примера Янник Килчер приводит ситуацию, когда в рецепте значатся морковь, острый перец и белый лук, а в инвентаре у агента уже лежат готовый жареный лук и сырая морковь. Рецептурный менеджер сформирует таблицу, где будет отмечено, что перец отсутствует, лук полностью готов (шаги не требуются), а морковь на месте, но её всё ещё нужно нарезать и запечь.
Янник Килчер подчёркивает принципиальное архитектурное отличие LeDeepChef от традиционных подходов в обучении с подкреплением: данное табличное представление формируется явно. В большинстве стандартных RL-систем исследователи пытаются обучать единую нейросеть сквозным образом (end-to-end), заставляя модель выводить некий скрытый латентный вектор, содержащий в себе информацию о рецепте.
Однако на практике это работает гораздо хуже. По словам ведущего, сигнал награды в играх слишком редкий и зашумлённый, чтобы сеть сама выделила такие сложные абстракции в процессе случайного поиска.
Авторы LeDeepChef пошли по более эффективному пути:
- Они создали изолированную подмодель для обработки рецептов.
- Обогатили обучающую выборку кулинарными данными из внешней базы знаний Freebase.
- Обучили рецептурный менеджер классическим методом контролируемого обучения (supervised learning) выдавать точные таблицы.
По мнению Килчера, это отличный урок для всех ИИ-инженеров: критически важную информацию, если есть техническая возможность, всегда стоит выносить в отдельные предобработанные модули с контролируемым обучением, а не полагаться исключительно на алгоритмы RL.
🛠️ Генерация допустимых команд и сужение пространства действий 25:17
Имея на руках структурированную таблицу от рецептурного менеджера, данные инвентаря и описание комнаты из команды look, система способна эффективно отсекать абсурдные действия и генерировать набор из $K$ адекватных команд. Например, если в комнате лежит нож, а агенту нужно нарезать овощ, модель автоматически сформирует команду take knife. Точно так же, зная нехватку или избыток предметов, алгоритм предлагает взять лук или выбросить бутылку с водой.
Для оптимизации процесса авторы сгруппировали элементарные действия в высокоуровневые макрокоманды. Например, вместо последовательного подбора каждого предмета агент может применить команду «взять все необходимые вещи из комнаты» (take all required items). Подобное объединение действий значительно упрощает жизнь агенту и, судя по результатам тестов, приносит ощутимый прирост эффективности.
Если же рецептурный менеджер рапортует, что все ингредиенты собраны и подготовлены, а агент находится на кухне, в список автоматически добавляются финальные команды вроде prepare meal или eat meal.
Дополнительно разработчикам пришлось решить проблему перемещения. Для этого была обучена отдельная навигационная подмодель. Она анализирует текст, определяет доступные направления движения и выявляет закрытые двери, генерируя команды для их открытия. Все эти навигационные варианты также примешиваются к общему списку $K$ допустимых действий, существенно снижая нагрузку на финальную нейросеть стратегии.
🥇 Обучение агента и результаты на соревнованиях 29:32
Собранная воедино архитектура обучается классическим методом Actor-Critic (актор-критик) с использованием преимуществ (advantage learning). Сеть стратегии настраивается на основе величины преимущества выбранного действия, сеть ценности подтягивается ближе к реальной полученной награде, а для поддержания исследовательской активности агента применяется штраф за недостаточную энтропию (entropy penalty).
Такой подход позволяет успешно обучать нейросетевого агента в условиях полного отсутствия размеченных эталонных действий от человека. Модель опирается исключительно на редкие очки вознаграждения от игрового движка.
Экспериментальные результаты LeDeepChef, как отмечает Килчер, выглядят крайне убедительно. Авторы провели тесты, сравнили систему с классическими базовыми моделями и выполнили абляционные исследования, поочередно отключая отдельные модули для проверки их значимости. В итоге разработанный агент сумел занять престижное второе место в официальном соревновании по прохождению текстовых игр, доказав высокую эффективность гибридного подхода.




