Как алгоритмы машинного обучения понимают, что они нашли оптимальное решение задачи? В третьем уроке первого курса специализации Machine Learning Specialization от DeepLearning.AI подробно разбирается интуитивная суть функции потерь (cost function). На примере простой линейной регрессии спикер наглядно демонстрирует, как математические вычисления превращаются в инструмент поиска идеальных параметров модели.
📊 Базовая концепция линейной регрессии и функции потерь 0:01
В начале занятия подчеркивается, что для понимания работы алгоритмов важно развить интуицию относительно функции потерь. В контексте линейной регрессии главной задачей является построение прямой линии, которая максимально точно описывает обучающие данные. Математически эта модель выражается формулой $f_{w,b}(x) = w x + b$, где переменные $w$ и $b$ выступают в роли параметров модели.
В зависимости от выбранных значений этих параметров, прямая линия на графике меняет свой наклон и положение. Чтобы измерить, насколько удачно конкретная пара значений $w$ и $b$ описывает данные, применяется специальная функция потерь $J$. Она вычисляет разницу между прогнозами, которые делает модель, и реальными истинными значениями целевой переменной $y$. В конечном итоге линейная регрессия стремится найти такие параметры, при которых значение функции потерь $J(w,b)$ будет минимально возможным.
🛠️ Упрощение модели для визуализации 1:35
Для того чтобы наглядно визуализировать этот процесс, лектор предлагает использовать упрощенную версию модели линейной регрессии. В этой версии параметр $b$ приравнивается к нулю, что исключает его из уравнения. Таким образом, формула модели принимает вид $f_w(x) = w x$.
При таком условии у функции потерь $J$ остается всего один регулируемый параметр — $w$, а сама задача сводится к поиску единственного значения, минимизирующего $J(w)$. С геометрической точки зрения обнуление параметра $b$ означает, что любая линия модели обязательно проходит через начало координат — точку $(0,0)$, поскольку при $x = 0$ значение $f(x)$ также всегда будет равным нулю.
Спикер предлагает сопоставить два графика, чтобы проследить взаимосвязь между изменением параметра и поведением функции потерь:
- График модели $f_w(x)$ — здесь при фиксированном значении $w$ функция зависит только от входного признака $x$, определяя предсказанное значение $y$.
- График функции потерь $J(w)$ — в данном случае аргументом выступает сам параметр $w$, который управляет углом наклона линии модели, а значение функции отражает величину ошибки.
📐 Пошаговый расчет функции потерь на конкретном примере 4:03
Для демонстрации расчетов берется простейший тренировочный набор, состоящий из трех точек с координатами $(1,1)$, $(2,2)$ и $(3,3)$. В качестве базовой метрики используется функция среднеквадратичной ошибки. Лектор последовательно разбирает несколько сценариев выбора параметра $w$, чтобы показать, как меняется итоговая ошибка.
Идеальный сценарий при $w = 1$
Если установить параметр $w = 1$, то линия модели $f_w(x) = 1 \cdot x$ в точности совпадет с обучающими данными, имея наклон под углом 45 градусов. При расчете функции потерь для каждой из трех точек разница между предсказанием модели и реальным значением оказывается равной нулю:
- Для первой точки: при $x = 1$ истинное $y = 1$ и предсказание $f(1) = 1$, разность равна 0.
- Для второй точки: при $x = 2$ истинное $y = 2$ и предсказание $f(2) = 2$, разность равна 0.
- Для третьей точки: при $x = 3$ истинное $y = 3$ и предсказание $f(3) = 3$, разность равна 0.
Поскольку для всех примеров разница $f(x_i) - y_i = 0$, итоговое значение функции потерь $J(1)$ также становится равным нулю. На правом графике, где по горизонтальной оси откладывается параметр $w$, а по вертикальной — значение $J$, фиксируется точка с координатами $(1, 0)$.
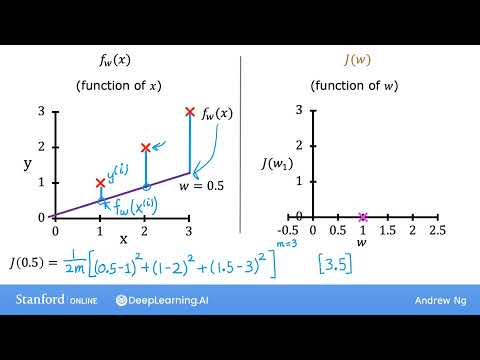
Сценарий с отклонением при $w = 0.5$
Что произойдет, если изменить параметр? Лектор рассматривает случай, когда $w = 0.5$. В этом случае линия модели имеет более пологий наклон. Визуально ошибка модели для каждой точки представляет собой длину вертикального отрезка между реальной координатой $y$ и линией графика $f(x)$.
Расчет квадратов ошибок для каждого из трех примеров выглядит следующим образом:
- Для первой точки ($x=1$): модель предсказывает $0.5$ при реальном значении $1$. Квадрат ошибки равен $(0.5 - 1)^2 = 0.25$.
- Для второй точки ($x=2$): модель предсказывает $1$ при реальном значении $2$. Квадрат ошибки равен $(1 - 2)^2 = 1.0$.
- Для третьей точки ($x=3$): модель предсказывает $1.5$ при реальном значении $3$. Квадрат ошибки равен $(1.5 - 3)^2 = 2.25$.
Сумма этих трех слагаемых составляет $3.5$. Согласно математической формуле, эту сумму необходимо умножить на коэффициент $\frac{1}{2m}$, где $m$ — количество обучающих примеров. Так как в рассматриваемом наборе три точки ($m = 3$), коэффициент равен $\frac{1}{2 \times 3} = \frac{1}{6}$. Итоговый расчет функции потерь дает результат:
$$J(0.5) = \frac{3.5}{6} \approx 0.58$$
Полученное значение наносится на правый график как точка с координатами $(0.5, 0.58)$.
Анализ крайних и отрицательных значений параметра
Далее спикер разбирает случай, когда параметр $w = 0$. При таком значении функция $f(x)$ превращается в горизонтальную линию, лежащую прямо на оси абсцисс. Ошибки для точек в этом случае равны их собственным координатам по оси $y$ (то есть 1, 2 и 3), а сумма их квадратов составляет $1^2 + 2^2 + 3^2 = 14$. Разделив эту сумму на 6, получаем значение функции потерь:
$$J(0) = \frac{14}{6} \approx 2.33$$
Параметр $w$ может принимать абсолютно любые значения, включая отрицательные. Если установить $w = -0.5$, линия модели будет направлена вниз. Расчеты показывают, что в этом случае суммарная ошибка возрастает еще сильнее, и значение функции потерь достигает величины около $5.25$.
📈 Формирование графика и поиск минимума 12:14
Последовательно вычисляя значения для множества различных $w$, можно постепенно прорисовать непрерывную линию функции потерь $J(w)$, которая приобретает форму чаши или параболы. Каждая точка на этом U-образном графике справа строго соответствует определенному наклону прямой линии на графике слева.
- Значение $w = 1$ соответствует идеальному прохождению линии через данные слева и минимальной точке параболы со значением $0$ справа.
- Значение $w = 0.5$ дает менее крутую линию слева и точку на склоне параболы со значением $0.58$ справа.
Таким образом, логика выбора наилучшего параметра становится очевидной: необходимо найти такое значение $w$, при котором функция потерь $J(w)$ будет минимальной. Минимизация среднеквадратичной ошибки автоматически гарантирует, что построенная линия будет максимально близка к точкам обучающей выборки. В данном примере оптимальным выбором является $w = 1$.
В завершение урока отмечается, что аналогичный принцип применим и к полноценной модели линейной регрессии, где одновременно подбираются оба параметра — $w$ и $b$. Изменение обоих параметров приводит к тому, что функция потерь становится трехмерной, напоминающей объемную чашу. Визуализация таких 3D-графиков будет представлена в следующем видеоматериале курса.




