Обучение агентов в сложных средах часто сталкивается с проблемой «проклятия размерности»: если путь к цели требует тысяч мелких шагов, обычное обучение с подкреплением (RL) заходит в тупик. Янник Кильчер (Yannic Kilcher) разбирает новую работу исследователей из Salesforce Research, которые предложили использовать «мировые графы» (World Graphs) для иерархического обучения. Эта технология позволяет ИИ разбивать сложную задачу на цепочку ключевых контрольных точек, превращая хаотичные блуждания в целенаправленное планирование.
🧱 Иерархическое обучение: Менеджер и Рабочий 0:15
В традиционном обучении с подкреплением агент совершает атомарные действия (например, шаг влево или вправо). В сложных лабиринтах, где нужно сначала найти ключ, затем открыть дверь и только потом достичь цели, последовательность таких шагов становится слишком длинной для эффективного обучения .
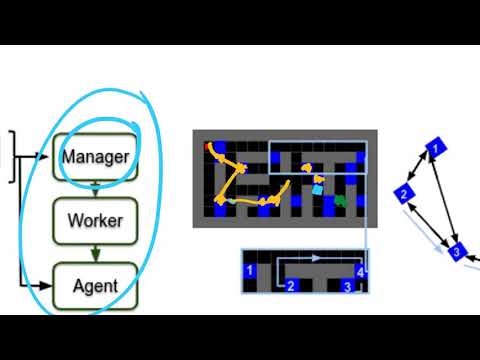
Янник Кильчер (Yannic Kilcher) объясняет концепцию Hierarchical Reinforcement Learning (HRL) через метафору разделения ролей:
- Менеджер (Manager): Обладает глобальным видением мира. Он не заботится о каждом шаге, а оперирует крупными блоками пространства или состояниями. Его задача — составить высокоуровневый план действий: «Сначала идем в сектор с ключом, затем к двери, потом к финишу» .
- Рабочий (Worker): Получает от менеджера конкретную подцель (например, переместиться в соседний сектор) и выполняет её, совершая те самые мелкие шаги .
Такой подход дает два преимущества: менеджер планирует на большие дистанции в упрощенном пространстве, а рабочий фокусируется на коротких, легко реализуемых маршрутах .
🗺️ Что такое World Graphs и как они работают 4:34
Основная инновация обсуждаемой статьи — это создание World Graphs (Мировых графов). По словам Янника Кильчера (Yannic Kilcher), такой граф состоит из двух ключевых компонентов:
- Узловые состояния (Pivot States): Это наиболее важные точки в пространстве. Часто они располагаются в узких проходах или «бутылочных горлышках» лабиринта . Достижение такой точки открывает агенту доступ ко многим другим частям мира.
- Граф соседства: Связи между узловыми состояниями, которые показывают, насколько легко добраться из одной точки в другую .
Когда у агента есть такой граф, менеджер может использовать его для поиска кратчайшего пути на уровне абстракций. Если цель находится за дверью, менеджер видит по графу, что путь пролегает через узел «Ключ» и узел «Дверь» . Рабочему остается лишь реализовать переходы между этими узлами «в один прыжок» .
🧠 Механизм обучения: Архитектура с двумя LSTM 10:14
Ключевой вопрос исследования: как ИИ понимает, какие состояния являются «важными» (pivots)? Для этого авторы используют сложную систему кодирования траекторий .
Процесс обучения выглядит следующим образом:
- Сбор данных: Агент совершает случайные блуждания или использует «любопытство» для исследования лабиринта .
- Кодировщик (Encoder): Первая нейросеть (LSTM) анализирует полученную траекторию и для каждого шага вычисляет вероятность того, является ли это состояние узловым. Янник Кильчер (Yannic Kilcher) отмечает, что начальная и конечная точки пути всегда считаются важными .
- Декодировщик (Decoder/Generator): Вторая сеть LSTM пытается восстановить (реконструировать) всю последовательность действий агента, имея на входе только те состояния, которые были помечены как важные .
Логика здесь проста: если, зная только точки A, B и C, нейросеть может точно восстановить все промежуточные шаги между ними, значит, эти точки являются информативными опорами маршрута . Если же по выбранным точкам нельзя восстановить путь (существует слишком много вариантов движения), значит, выбор «важных» состояний был неудачным .
🔗 Соединение узлов и результаты 16:40
После того как нейросеть научилась определять важные точки (pivots), их нужно связать в единый граф. Янник Кильчер (Yannic Kilcher) описывает этот процесс как серию случайных блужданий от одного узла к другому. Если агент, выйдя из синей точки (узла), быстро натыкается на другую синюю точку, между ними в графе рисуется ребро .
По мнению ведущего, результаты экспериментов подтверждают эффективность метода:
- Предварительное обучение на мировых графах позволяет агенту значительно быстрее осваивать новые, более сложные задачи в той же среде .
- Мировые графы обеспечивают лучшую переносимость знаний (transfer learning), так как структура мира остается неизменной даже при смене конечной цели задания.
Янник Кильчер (Yannic Kilcher) заключает, что использование подобных «карт важности» делает обучение с подкреплением гораздо более масштабируемым для реальных задач .