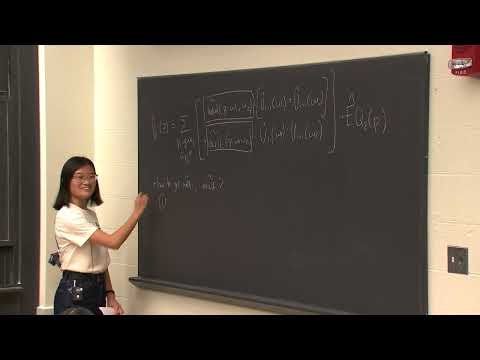
Лекция Рейчел Чанг в рамках курса MIT OpenCourseWare посвящена глубокому теоретическому разбору и развитию интерактивного протокола GKR (Голдвассера-Калаи-Ротблума) для верификации вычислений. В центре внимания находится устранение классических ограничений протокола — в частности, требования оракульного доступа к селекторам гейтов — и доказательство фундаментальной теоремы сложности $IP = PSPACE$ с экспоненциальным ускорением работы доказывающей стороны (прувера). Этот аналитический материал подробно восстанавливает математический аппарат, алгоритмы арифметизации булевых формул и концепцию построения «коротких и широких» схем методом повторного возведения в квадрат.
🔄 Рекапитуляция протокола GKR и уравнение Sum-Check 0:02
Интерактивный протокол GKR предназначен для эффективного делегирования вычислений. Представив вычисление в виде арифметической схемы $C$ глубины $D$ и размера $S$, верификатор может переложить задачу расчета на мощный сторонний сервер (прувер), требуя от него математическое доказательство корректности финального результата.
Основной принцип работы GKR заключается в послойном анализе схемы сверху вниз. Значения всех проводников (wire values) на каждом слое расширяются до полиномов низкой степени (Low-Degree Extension, LDE). Протокол последовательно редуцирует утверждения о значениях выходов на верхнем слое к утверждениям о значениях проводников на слоях, расположенных ниже, используя для этого Sum-Check протокол. Процесс повторяется итеративно до тех пор, пока утверждения не будут сведены к входному слою схемы, который верификатор способен проверить самостоятельно.
При такой конфигурации временные затраты участников распределяются следующим образом:
- Время работы прувера: составляет $\text{poly}(S)$, что делает процедуру полиномиально зависимой от размера исходной схемы.
- Время работы верификатора: оценивается как $D \cdot \text{polylog}(S) + n \cdot \text{polylog}(S)$, где $n$ — размер входных данных.
Для оптимизации протокола применяется важный метод: использование одной и той же случайности (shared randomness) для одновременной проверки нескольких утверждений на одном слое. Это избавляет от необходимости запускать независимые ветки Sum-Check протокола для каждого промежуточного гейта.
Математическая основа проверки гейта $i$-го слоя описывается масштабным полиномиальным уравнением, учитывающим селекторы сложения (add) и умножения (mult):
$$\hat{V}i(z) = \sum{p, \omega_1, \omega_2} \left[ \tilde{add}(z, p, \omega_1, \omega_2)(\hat{V}{i+1}(\omega_1) + \hat{V}{i+1}(\omega_2)) + \tilde{mult}(z, p, \omega_1, \omega_2)(\hat{V}{i+1}(\omega_1) \cdot \hat{V}{i+1}(\omega_2)) \right] Q_2(z, p)$$
В данном уравнении полином $Q_2$ имеет индивидуальную степень $|H|-1$ по каждой переменной и выполняет функцию проверки эквивалентности точек $z$ и $p$ внутри булева гиперкуба. Если точка принадлежит гиперкубу, $Q_2$ принимает значение 1 тогда и только тогда, когда $p = z$.
🛠️ Переход к универсальным схемам: устранение оракульного доступа 6:21
Базовая версия GKR опирается на допущение, что верификатор обладает мгновенным (оракульным) доступом к полиномиальным расширениям гейтов сложения и умножения. Главная цель текущего анализа — избавиться от этого допущения и сделать верификатора полностью автономным.
Существует два принципиальных подхода к решению этой задачи:
- Повторное делегирование (Redelegation): повторный запуск GKR для вычисления самих функций
addиmult, как это было предложено в оригинальной работе авторов протокола. - Арифметическое вычисление: построение альтернативного полинома невысокой степени, который совпадает с каноническим LDE на гиперкубе.
Поскольку исходная схема $C$ может быть слишком сложной для самостоятельного анализа верификатором, Рейчел Чанг предлагает заменить её более простой для описания универсальной схемой $U$ (Universal Circuit), которая сохраняет исходную функциональность.
Универсальная схема $U$ принимает на вход два компонента: компактное описание целевой схемы $C$ и её фактические входные данные $x$. На выходе $U$ симулирует работу $C(x)$. Описание схемы $C$ представляет собой функцию, которая для каждой локации гейта указывает его тип. Подобное описание в сыром виде имеет гигантский размер порядка $2^S$ (или $S^3$, учитывая три индекса для связей гейтов).
Внутри универсальной схемы вычисление значения на $i$-м слое декомпозируется в двоичное дерево сумм. Для каждого гейта строится небольшая подсхема, которая анализирует предыдущий слой и применяет операцию на основе инструкций из описания схемы $C$. Глубина такого бинарного дерева составляет всего $\log S$.
Следовательно, общие параметры универсальной схемы $U$ принимают вид:
- Глубина схемы $U$: произведение глубины исходной схемы на логарифм её размера: $D \cdot \log S$.
- Размер схемы $U$: $\text{poly}(S)$, поскольку каждый гейт исходной схемы замещается блоком полиномиального размера.
Главное преимущество $U$ заключается в том, что её собственные гейты сложения и умножения теперь описываются крайне просто: существуют низкоглубинные булевы формулы $\phi_{add}$ и $\phi_{mult}$ размера $\text{polylog}(S)$, которые способны однозначно определять топологию универсальной схемы. Верификатор способен вычислить их самостоятельно, тратя на это полилогарифмическое время вместо обработки сложной структуры исходного графа.
⚠️ Проблемы универсального подхода и лог-пространственная униформность 24:10
Несмотря на элегантность концепции универсальной схемы, при её прямой реализации возникают две критические проблемы:
- Проблема избыточного входа: Входные данные для $U$ включают в себя полное описание схемы $C$, размер которого пропорционален $S$. В финальной стадии GKR верификатор обязан самостоятельно вычислить low-degree extension (LDE) от всего входного слоя. Если вход имеет размер $\text{poly}(S)$, верификатор теряет свою эффективность, тратя на верификацию столько же времени, сколько потребовалось бы на обычное вычисление.
- Проблема полиномиального расширения формул: Наличие булевых формул для гейтов позволяет знать их значения на гиперкубе, но не дает прямого аналитического выражения для их расширений (LDE) над большим полем.
Для решения проблемы гигантского входа вводится требование лог-пространственной униформности схемы $C$ (logspace uniformity). Это означает, что схема $C$ обладает высокоструктурированной топологией и может быть сгенерирована компактной машиной Тьюринга $M$, работающей с ограничением по памяти $\log S$ за время $S$. Машина Тьюринга по запросу способна выдать описание любого требуемого гейта схемы $C$.
Вместо того чтобы подавать описание $C$ на вход, верификатор «разворачивает» саму машину Тьюринга $M$ в эквивалентную арифметическую схему $C'$. Эта схема принимает на вход лишь ультракомпактное описание (сид) схемы размером $\log S$ и исходный вектор $x$.
Благодаря детерминированной структуре $M$, её аппаратное развертывание позволяет уложить схему $C'$ в глубину $\log S$ и размер $S$. В итоге совокупная схема $C'$ сохраняет полиномиальный размер $\text{poly}(S)$ и полилогарифмическую глубину $\text{polylog}(S)$. Размер входа для верификатора сокращается до $\log S + n$, возвращая ему сублинейную эффективность вычислений.
🧮 Арифметизация булевых формул и «достаточно низкая» степень 37:32
Вторая технологическая сложность — вычисление low-degree extensions для предикатов гейтов. У верификатора есть лишь компактные булевы формулы $\phi_{add}$ и $\phi_{mult}$ размера $\text{polylog}(S)$, оперирующие битами.
Для их трансформации применяется процедура арифметизации (arithmetization):
- Элементы большого множества $H$, кодирующие локации гейтов, преобразуются в битовые строки с помощью интерполяционных полиномов степени $|H|-1$.
- Логические вентили булевой формулы послойно заменяются полиномами над полем:
- Вентиль AND(a, b) преобразуется в алгебраическое произведение: $a \cdot b$.
- Вентиль OR(a, b) заменяется полиномом: $a + b - a \cdot b$.
В результате сквозной замены логических операций на арифметические формируется расширение, получившее на лекции шутливое название LEID (Low Enough Degree Extension) — «расширение достаточно низкой степени». Оно не является строго каноническим LDE минимальной степени, но его алгебраические свойства полностью удовлетворяют требованиям Sum-Check протокола.
Финальная степень полученного полинома определяется как произведение количества входных гейтов на степень конвертирующего полинома:
$$\text{Degree} = \log S' \cdot |H|$$
Поскольку между битовыми представлениями и координатами в большом поле существует строгая биекция, наложение или коллизии данных полностью исключены. Верификатор может уверенно использовать полученный полином LEID в уравнениях интерактивного доказательства.
🏛️ Равенство IP = PSPACE и наследие Шамира 52:26
Рассмотренный математический аппарат позволяет по-новому взглянуть на классические теоремы теории сложности вычислений, в частности, на соотношение классов $IP$ (интерактивные протоколы с полиномиальным верификатором и всемогущим прувером) и $SPACE$ (языки, распознаваемые в полиномиальном пространстве).
В 1992 году Ади Шамир доказал их фундаментальное равенство ($IP = PSPACE$), продемонстрировав, что любое вычисление из класса $PSPACE$ снабжено интерактивным доказательством. Однако классический протокол Шамира содержал серьезный изъян, препятствующий его практическому внедрению в концепцию облачного делегирования: время работы доказывающей стороны (prover runtime) возрастало экспоненциально и составляло $2^{S^2}$. Последующие оптимизации снизили этот барьер до $2^{S \log S}$, однако этот показатель все еще значительно превышал чистое время, необходимое для прямого вычисления задачи ($2^S$).
Интеграция протокола GKR в качестве базового компонента позволяет заявить безусловную теорему:
Теорема: Используя архитектуру GKR, можно гарантировать равенство $IP = PSPACE$, при котором накладные расходы прувера составят всего $\text{poly}(2^S)$.
Для предельно сложных задач из класса $PSPACE$, чье прямое вычисление требует порядка $2^S$ шагов, это означает достижение информационной и теоретической безопасности без создания колоссальных вычислительных перегрузок на стороне доказывающего сервера. Вопрос построения аналогично эффективных систем для вычислений общего вида в рамках произвольных пространственно-временных ограничений ($TSPACE$) по сей день остается открытым в академической среде.
🔲 Построение PSPACE-схем через повторное возведение в квадрат 58:51
Для финального доказательства теоремы необходимо упаковать произвольное $PSPACE$-вычисление, выполняемое машиной Тьюринга $M$ в пространстве $S$ за время $T = 2^S$, в арифметическую схему малой глубины. Прямая последовательная симуляция привела бы к созданию схемы глубины $2^S$, что неприемлемо для эффективной верификации. Цель алгоритма — упаковать процесс в глубину $\text{poly}(S)$.
Для реализации этой задачи строится конфигурационная матрица переходов $A$ (transition matrix) размером $2^S \times 2^S$. Каждая строка и столбец матрицы соответствуют полному моментальному снимку памяти машины Тьюринга, включая положение её считывающей головки и внутреннее состояние автомата.
Значения ячеек матрицы определяются следующим образом:
$$A_{ij} = \begin{cases} 1, & \text{если состояние } i \text{ переходит в состояние } j \text{ за 1 такт} \ 0, & \text{в противном случае} \end{cases}$$
В силу строгой детерминированности машины Тьюринга каждая строка матрицы содержит ровно одну единицу. Описание этой матрицы максимально униформно и легко рассчитывается локальной формулой малой глубины.
Чтобы узнать, перейдет ли стартовая конфигурация в принимающую (accepting) за $T$ шагов, необходимо вычислить матрицу $A^T$. Если перемножить две матрицы $A \cdot A$, то полученная матрица $A^2$ будет содержать единицы в ячейках $A^2_{ij}$ только тогда, когда переход из $i$ в $j$ возможен ровно за два шага вычислений. Алгебраически это выражается через сумму попарных произведений промежуточных состояний $k$:
$$A^2_{ij} = \sum_{k} A_{ik} \cdot A_{kj}$$
Вместо линейного наращивания шагов применяется метод повторного возведения в квадрат (repeated squaring). Схема последовательно генерирует слои матриц:
$$A \rightarrow A^2 \rightarrow A^4 \rightarrow A^8 \rightarrow \dots \rightarrow A^T$$
Такой подход кардинально меняет геометрию вычисления. Схема превращается из «длинной и узкой» в «короткую и широкую». Архитектурные параметры полученной схемы:
- Глубина схемы: сокращается до величины $\log T \cdot \text{poly}(S) = \text{poly}(S)$, что обеспечивает логарифмическую зависимость от общего времени работы машины.
- Размер схемы: составляет $\text{poly}(2^S)$.
При развертывании протокола GKR поверх данной схемы, прувер тратит время $\text{poly}(2^S)$, а верификатор функционирует в рамках полиномиального времени от размера памяти: $\text{poly}(S)$. Фактическое считывание конкретных стартовых данных и проверка финального бита согласия происходят лишь на самом верхнем слое схемы в момент завершения интерактивного раунда. Это избавляет верификатора от необходимости удерживать в памяти или обрабатывать промежуточные конфигурации матриц огромного размера.