В видеоролике популярного ИТ-исследователя Янника Кильхера (Yannic Kilcher) подробно разбирается научная статья разработчиков из Facebook Research, представивших модель RoBERTa. Автор анализирует, как за счет точечной настройки процесса предварительного обучения классической архитектуры BERT можно добиться результатов, превосходящих более поздние и сложные нейросети. Главный вывод работы заключается в том, что потенциал базовых моделей не был исчерпан до конца, а правильный выбор гиперпараметров и объемов данных позволяет классическому подходу удерживать лидерство.
🧠 Архитектура BERT и новая философия оптимизации 0:00
Янник Кильхер начинает обзор с краткого напоминания о том, что представляет собой модель BERT. Это популярная нейросетевая языковая архитектура на базе трансформеров, которая принимает на вход текст, кодирует его и способна выполнять самые разные прикладные задачи: от классификации до извлечения ответов на вопросы. Модель обучается без разметки с помощью так называемой задачи маскированного языкового моделирования (Masked Language Model, MLM). В процессе обучения часть слов скрывается (маскируется), и нейросеть должна восстановить их, используя окружающий текстовый контекст.
По словам ведущего, после выхода оригинальной статьи про BERT появилось множество альтернативных подходов (например, XLNet), авторы которых утверждали, что изменили архитектуру или цели обучения для достижения лучших результатов. Однако создатели RoBERTa выдвинули гипотезу: если правильно подобрать дизайн-решения и гиперпараметры pre-training фазы, классический BERT способен работать на одном уровне или даже превосходить все новые методы. Для проверки этой идеи исследователи использовали стандартную архитектуру BERT в конфигурациях BERT-Base (12 слоев) и BERT-Large (24 слоя).
📊 Сбор данных и оценка на прикладных задачах 4:05
Сравнение языковых моделей часто осложняется тем, что они обучаются на совершенно разных по объему и структуре наборах данных. Чтобы сделать эксперимент максимально чистым, авторы RoBERTa тщательно исследовали влияние как масштаба данных, так и продолжительности обучения. Оригинальный BERT тренировался на относительно скромном корпусе:
- BookCorpus и английский сегмент Wikipedia общей сложностью 16 гигабайт.
Для обучения RoBERTa команда собрала значительно более массивный стек данных, включающий новый датасет CC-News. Этот датасет представляет собой англоязычную часть новостного среза Common Crawl объемом 76 гигабайт, что, по оценке Янника Кильхера, сопоставимо с объемами данных для обучения GPT-2. Дополнительно использовались корпуса Open WebText и Stories.
Для оценки эффективности предварительного обучения исследователи задействовали стандартные бенчмарки для прикладных задач (downstream tasks). Как подчеркивает Янник Кильхер, специфика самих этих тестов не так важна, поскольку они служат лишь линейкой для измерения качества базовой языковой модели после этапа тонкой настройки (fine-tuning).
🎭 Статическое против динамического маскирования 7:09
Одним из ключевых технических изменений в RoBERTa стал отказ от статического маскирования в пользу динамического. В оригинальном методе BERT маска накладывалась на текст один раз на этапе подготовки данных. Чтобы обучать модель несколько эпох, данные приходилось дублировать, но маски на этих дублях оставались фиксированными. Из-за этого при длительном обучении модель неизбежно видела абсолютно одинаковые замаскированные позиции.
Динамическое маскирование подразумевает генерацию маски «на лету» непосредственно в процессе подачи данных в модель. По мнению Янника Кильхера, такой подход гораздо полезнее с практической точки зрения. Эксперименты авторов показали незначительное улучшение результатов на двух тестовых задачах и минимальное снижение показателей лишь на одном из тестов. В итоге исследователи приняли решение использовать именно динамическое маскирование как более эффективную и гибкую стратегию.
❌ Отказ от предсказания следующего предложения (NSP) 9:07
Классический BERT обучался на двух задачах одновременно: MLM и Next Sentence Prediction (NSP). В задаче NSP нейросети давались два сегмента текста, и она должна была угадать, идет ли второй сегмент сразу за первым в исходном документе, или же он случайно взят из другого места (вероятность этого составляла 50%). Создатели BERT утверждали, что это необходимо для фиксации долгосрочных связей между предложениями.
Авторы RoBERTa решили проверить необходимость этой вспомогательной лосс-функции и протестировали четыре формата входных данных:
- Segment-pair + NSP — классический вариант BERT, где на вход подается пара сегментов, каждый из которых может содержать несколько естественных предложений, суммарной длиной до 512 токенов.
- Sentence-pair + NSP — пара из одиночных естественных предложений, что делает входной контекст значительно короче 512 токенов.
- Full-sentences — модель полностью заполняется непрерывным текстом объемом до 512 токенов, переходя границы документов при необходимости.
- Doc-sentences — аналогично предыдущему, но текст берется строго из одного документа, а остаток заполняется паддингом.
Результаты тестирования удивили ИТ-сообщество. Лучшие результаты показал формат Doc-sentences, за которым с минимальным отрывом следовал формат Full-sentences. Исследователи пришли к выводу, что удаление задачи NSP не ухудшает, а в некоторых случаях даже слегка улучшает результаты на прикладных задачах. Это прямо противоречит исходным выводам создателей BERT. В финальной версии RoBERTa разработчики остановились на формате Full-sentences, поскольку он проще в реализации и позволяет эффективнее утилизировать вычислительные мощности.
⚡ Увеличение размера пакетов и кодирование текста 14:24
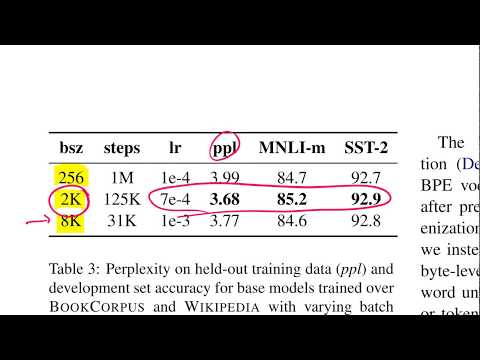
Исследование показало, что современные крупные языковые модели демонстрируют отличные результаты при значительном увеличении размера батча (batch size). Авторы протестировали диапазон размеров пакетов от скромных 512 до гигантских 8000 образцов. Такой масштаб был достигнут с помощью параллельных вычислений на множестве машин с большим количеством графических процессоров (GPUs), где градиенты аккумулировались перед обновлением весов.
Эксперименты подтвердили, что увеличение размера батча до 2000 ощутимо улучшает перплексию модели и итоговые метрики при сохранении общего объема просмотренных данных. Янник Кильхер отмечает, что это дает заметный, пусть и маргинальный, прирост эффективности оптимизации.
Также изменения коснулись токенизации текста. Вместо алгоритма WordPiece, применявшегося в BERT, разработчики RoBERTa перешли на кодирование пар байтов (Byte-Pair Encoding, BPE) на уровне байтов с увеличенным словарем. Хотя радикальной разницы в качестве между методами замечено не было, авторы выбрали BPE из-за его универсальности и удобства.
🏆 Как RoBERTa превзошла конкурентов и вышла в SOTA 16:28
Объединив все успешные находки, исследователи представили итоговую модель RoBERTa (Robustly Optimized BERT Approach). Она включает в себя динамическое маскирование, формат Full-sentences без лосса NSP, крупные мини-батчи, байтовый BPE-токенизатор и расширенный набор тренировочных данных.
В финальной части статьи авторы исследовали фактор времени обучения. Динамика результатов выглядит следующим образом:
- При обучении только на оригинальных данных BERT новая модель RoBERTa уверенно обходит классический BERT, но пока уступает XLNet.
- При добавлении собранных 76 ГБ данных RoBERTa выходит на один уровень с XLNet.
- При увеличении количества шагов pre-training (продолжительном обучении) RoBERTa начинает превосходить XLNet на большинстве бенчмарков, устанавливая новые рекорды (State-of-the-Art).
По мнению Янника Кильхера, этот результат заставляет задуматься о реальной ценности многих новых архитектур. Ведущий предполагает, что успехи альтернативных моделей часто обусловлены не какими-то революционными изменениями в коде, а банально более качественной настройкой процесса обучения. В завершение обзора Янник Кильхер призывает зрителей изучить открытый репозиторий проекта, так как авторы полностью опубликовали исходный код и данные для воспроизведения экспериментов.




