В новом видео Янник Килчер, популярный исследователь и популяризатор машинного обучения, разбирает работу исследователей из Facebook AI (ныне Meta AI), INRIA и Университета Сорбонны под названием XCiT: Cross-Covariance Image Transformers. Основная идея статьи заключается в радикальном пересмотре механизма внимания (attention), который позволил избавить трансформеры от их главного недостатка — квадратичной сложности вычислений. Килчер анализирует, действительно ли перед нами новая веха в архитектуре трансформеров или же это хитро замаскированная эволюция свёрточных нейросетей (ConvNets).
🧩 Проблема квадратичной сложности и «транспонированное» внимание 2:01
Традиционные трансформеры, завоевавшие успех в обработке естественного языка (NLP) и компьютерном зрении (Vision Transformers, ViT), полагаются на механизм селф-аттеншена. Как отмечает автор видео, этот механизм обеспечивает глобальное взаимодействие между всеми токенами — словами или патчами изображения . Однако за гибкость приходится платить: вычислительная сложность и потребление памяти растут квадратично относительно длины последовательности (количества токенов).
Это делает невозможным обработку длинных текстов или изображений высокого разрешения без разбиения их на крупные патчи. Для решения этой проблемы авторы XCiT предложили «транспонированную» версию внимания:
- Классический подход: Токены взаимодействуют с токенами (Token-to-Token attention).
- Подход XCiT: Каналы функций взаимодействуют с другими каналами (Channel-to-Channel attention) .
В этом случае взаимодействия строятся на основе матрицы кросс-ковариации между ключами (keys) и запросами (queries). Янник Килчер подчеркивает, что такая замена меняет правила игры: теперь сложность становится линейной относительно количества токенов .
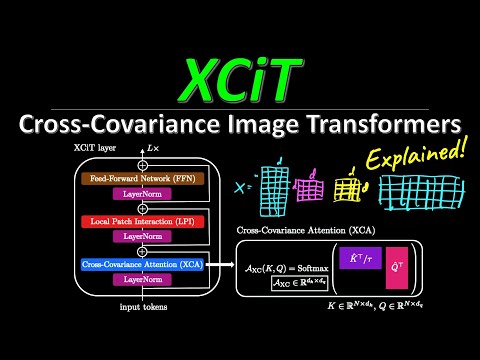
⚙️ Как работает Cross-Covariance Attention (XCA) 4:42
Разбирая математическую суть, Килчер сравнивает XCA с привычным механизмом внимания. В обычном трансформере каждый патч изображения (токен) генерирует вектор-запрос (query) и вектор-ключ (key). Система сравнивает каждый запрос с каждым ключом, создавая огромную таблицу маршрутизации информации размером $N \times N$ (где $N$ — число токенов) .
В XCiT ситуация иная:
- Смена ракурса: Мы смотрим на данные не как на последовательность токенов, а как на последовательность признаков (каналов) .
- Матрица ковариации: Вместо вычисления скалярных произведений между токенами, алгоритм вычисляет взаимодействия между каналами по всей последовательности. Результатом становится матрица размером $d \times d$ (где $d$ — количество каналов), которая обычно значительно меньше, чем число токенов в высоком разрешении .
- Глобальный контекст: Например, один канал может отвечать за поиск «структур, похожих на глаза» по всему изображению, а другой — за «структуры рта» . Их взаимодействие в матрице кросс-ковариации позволяет модели понять, что на картинке есть лицо, вне зависимости от того, в каких именно патчах находятся эти части .
🤨 Трансформер или «динамическая свёртка»? 18:22
Янник Килчер высказывает критическое мнение относительно классификации XCiT. По его словам, после прочтения статьи возникает вопрос: «Можно ли это вообще называть трансформером?» .
Килчер аргументирует это тем, что архитектура XCiT больше напоминает современную свёрточную сеть (ConvNet) с динамическими компонентами:
- Динамическая 1x1 свёртка: В XCA каждый токен обрабатывается индивидуально через матрицу, которая была создана на основе всей последовательности. По сути, это свёртка 1x1, где ядро (kernel) вычисляется динамически для каждого изображения .
- Отсутствие прямого смешивания токенов: В отличие от классического аттеншена, здесь информация между патчами не перемешивается напрямую. Смешивание происходит лишь косвенно, через веса динамического ядра .
- Local Patch Interaction (LPI): Чтобы добавить взаимодействие между соседними токенами, авторы включили в блок явный слой свёртки (depth-wise separable convolution) .
По мнению ведущего, XCiT — это скорее «удачная эволюция ConvNets», чем классический трансформер, поскольку ключевой механизм маршрутизации информации между элементами последовательности здесь заменен на агрегацию каналов .
📊 Результаты и технические «трюки» 28:10
Несмотря на споры о терминологии, XCiT демонстрирует впечатляющие результаты на стандартных бенчмарках (ImageNet classification, детекция объектов, сегментация) .
Килчер выделяет несколько важных инженерных решений, без которых модель, по признанию самих авторов, «разваливается»:
- L2-нормализация: Критически важна для стабильности вычислений .
- Обучаемый параметр температуры: Масштабирование софтмакса с помощью отдельной переменной значительно влияет на точность .
- Блочно-диагональная матрица: В XCA каналы не всегда взаимодействуют «все со всеми». Авторы используют блоки (аналог Group Normalization), что повышает эффективность .
Янник отмечает, что по потреблению памяти на GPU модель XCiT показывает себя даже лучше, чем классический ResNet-50 при работе с высокими разрешениями .
🧐 Справедливая критика и выводы 33:26
В завершение обзора Килчер указывает на определенное противоречие. Авторы XCiT заявляют, что их метод позволяет обрабатывать изображения высокого разрешения благодаря линейной сложности. Однако в ходе экспериментов они всё равно продолжают использовать патчи (минимальный размер 8x8 пикселей) . Янник задается вопросом: если вычислительная сложность больше не является препятствием, почему бы не перейти к попиксельной обработке (full resolution)? .
Ключевые выводы автора:
- XCiT — это мощная архитектура, объединяющая точность трансформеров и масштабируемость свёрточных сетей .
- Модель отлично работает в связке с методами self-supervised learning, такими как DINO .
- Индустрия постепенно уходит от гонки за «+0.1% точности» к созданию моделей, работающих «на одном уровне со State-of-the-art», но гораздо более эффективных в плане ресурсов .
Килчер подытоживает, что был бы рад увидеть применение архитектуры XCA в других областях, например, в обработке текстов (NLP), чтобы окончательно понять, насколько «трансформерными» являются её свойства вне контекста изображений .




