Создание искусственного интеллекта, способного превзойти человека в сложных стратегических играх, долгие годы оставалось главным вызовом для разработчиков. В своем подробном видеообзоре IT-исследователь Янник Килчер (Yannic Kilcher) анализирует научную статью от команды DeepMind, посвященную системе AlphaStar. Исследователям удалось вывести ИИ на уровень Грандмастера в культовой стратегии StarCraft II благодаря уникальному подходу к многоагентному обучению с подкреплением.
📢 Критика закрытой науки и пиара DeepMind 0:00
Янник Килчер начинает свой разбор с жесткой критики в адрес DeepMind. Поводом послужила публикация научной статьи в престижном журнале Nature. По мнению Килчера, выбор этой платформы является пережитком прошлого века и чистым пиар-ходом. Журнал не предоставляет открытый доступ (Open Access), заставляя читателей платить за загрузку материалов, при этом авторы и рецензенты не получают от этих денег ни цента. Ведущий иронично сравнивает эту ситуацию с заявлениями OpenAI о том, что их модели «слишком опасны для релиза», и шутит, что DeepMind, вероятно, считает AlphaStar «слишком опасным игроком в StarCraft», чтобы делиться им со всем миром. Килчер призывает академическое сообщество активнее переходить на открытые форматы распространения знаний.
🎮 Сложность StarCraft II как испытательного полигона для ИИ 1:44
Игра StarCraft II представляет собой стратегию в реальном времени (RTS) с видом от третьего лица. Игрок управляет экономикой, возводит здания, производит разнообразные войска и стремится полностью уничтожить базу противника. Проект знаменит глубоким балансом между тремя совершенно непохожими расами:
- Терраны — люди, использующие привычную технику вроде десантников, танков и вертолетов.
- Протоссы — высокотехнологичные пришельцы со способностями к телепортации и энергетическими щитами.
- Зерги — роящиеся подземные существа, которые распространяются подобно инфекции.
Каждая раса требует уникального стиля игры. Обучение агента для такой среды — колоссальная проблема для классического обучения с подкреплением (RL). Пространство возможных действий огромно: клики мышью по экрану, управление мини-картой, микроконтроль юнитов. Кроме того, в StarCraft II крайне «разреженная» награда (sparse reward): матч длится 10–15 минут, и ИИ получает сигнал победы или поражения только в самом конце. Агенту необходимо самостоятельно определить, какие именно из тысяч совершенных действий привели к итоговому результату. Чтобы решить эту задачу, инженеры DeepMind объединили почти все известные в индустрии приемы.
🧠 Первым делом — имитация: обучение на основе человеческого опыта 6:07
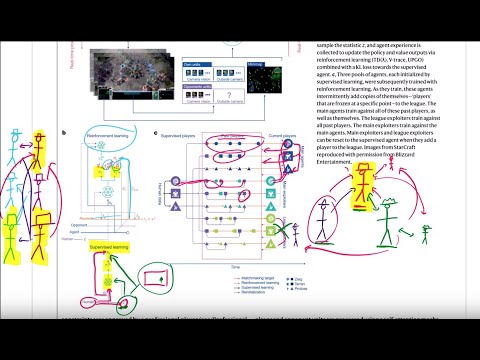
В отличие от прошлых проектов DeepMind, AlphaStar удивительно мало переняла от AlphaGo или AlphaZero — система построена на базе алгоритмов model-free reinforcement learning. Начальная инициализация системы происходит с помощью обучения с учителем (supervised learning) на основе матчей реальных игроков с высоким рейтингом Elo.
Из человеческих игр извлекается вектор статистики $Z$, который определяет «порядок сборки» (build order) — стратегическую последовательность возведения зданий и заказа юнитов на несколько минут вперед. На каждом шаге модель получает изображение экрана и текущую общую стратегию, пытаясь в точности скопировать действия человека. Килчер отмечает, что даже на этом этапе имитации ИИ смог обойти более 80–85% обычных игроков в официальных лигах StarCraft, что уже является серьезным достижением.
🏗️ Архитектура нейросети AlphaStar: от карты до LSTM 9:44
Нейросетевая модель AlphaStar сопоставляет входные данные с конкретным действием. На вход поступает не только мини-карта, но и детальный список объектов (entities). Игровой движок передает ИИ данные обо всех его юнитах: их здоровье, типе, координатах и предметах. Юниты противника видны модели только в том случае, если они находятся в зоне видимости. Также учитываются скалярные признаки: текущая раса, внутриигурное время и другие параметры.
Для обработки этих разнородных данных инженеры применили комплексную архитектуру:
- Мини-карта обрабатывается сверточной сетью ResNet.
- Список юнитов кодируется трансформером (Transformer), идеально подходящим для работы с множествами объектов.
- Скалярные данные проходят через многослойный перцептрон (MLP).
Все закодированные фичи объединяются и передаются в глубокую рекуррентную сеть LSTM, которая отвечает за долгосрочную стратегию во времени. LSTM необходима из-за частичной наблюдаемости среды: ИИ должен помнить, что три шага назад он отдал приказ строить здание, даже если сейчас этого здания нет на экране, чтобы не продублировать команду из-за забывчивости.
🕹️ Анатомия принятия решений: политика и управление действиями 15:13
На выходе архитектура делится на два ключевых компонента, характерных для алгоритмов Actor-Critic: сеть ценности (value network) и сеть политики (policy). Для улучшения обучения сети ценности DeepMind применила важный трюк: во время тренировок ей скармливали данные наблюдений обоих игроков, что существенно повысило качество работы системы (при этом во время реальной игры эта сеть не используется).
Сеть политики принимает решения по цепочке из нескольких подсетей:
- Определение типа действия (построить, переместить, сдвинуть камеру).
- Расчет задержки (delay) — когда именно выполнить действие.
- Решение о помещении команды в очередь (queue). Модель программно ограничена, чтобы имитировать физические возможности человека.
- Выбор юнитов-исполнителей с помощью указательной сети (Pointer Network), которая способна ссылаться на свои же входные данные через skip-connections от энкодера объектов.
- Выбор цели действия на мини-карте через десверточную сеть (D_convolutional ResNet), создающую распределение вероятностей (точку) на карте.
Для оптимизации этого сложного процесса DeepMind внедрила модификации классического обучения Actor-Critic, такие как алгоритм V-trace (из работы Impala), апдейты политики UPGO и обучение TD-lambda.
⚔️ Лига и эксплуататоры: инновационная методика тренировок 23:42
Главным концептуальным прорывом работы, по мнению Янника Килчера, является организация процесса тренировок, названная «обучением в Лиге» (League training). Обычная игра против самого себя (self-play), использовавшаяся в AlphaGo, часто приводит к нестабильности и зацикливанию алгоритма по принципу «камень-ножницы-бумага». Метод fictitious self-play частично решает это за счет периодических матчей со своими старыми версиями, но DeepMind пошла дальше и создала целую экосистему из трех типов агентов:
- Основные агенты (Main Agents): главные модели, которые играют друг против друга, против своих прошлых итераций и против специализированных противников.
- Основные эксплуататоры (Main Exploiters): агенты, чья единственная задача — искать уязвимости в текущей версии основного агента. Они регулярно инициализируются заново на основе человеческих данных и целенаправленно бьют по слабым местам. Как только основной агент учится отражать их атаки, эксплуататоры сбрасываются для поиска новых уязвимостей.
- Эксплуататоры Лиги (League Exploiters): агенты, нацеленные на поиск системных слабостей всей Лиги в целом. Они играют против прошлых версий всех участников, но не играют сами с собой.
В результате основные агенты оказываются подготовлены ко всем возможным тактикам и уловкам «под солнцем». Абляционные исследования (ablation studies) подтверждают, что добавление каждого нового типа эксплуататоров и усложнение состава Лиги неуклонно повышали рейтинг Эло системы.
📊 Триумф AlphaStar и скептицизм вокруг честности матчей 31:49
В итоге финальные агенты AlphaStar достигли уровня Грандмастера, превзойдя 99.x% игроков-людей. Тем не менее Янник Килчер призывает относиться к этим результатам со здоровой долей скептицизма, поскольку прямое сравнение машины и человека в RTS-играх не всегда корректно.
Несмотря на то, что DeepMind ограничила количество действий ИИ в секунду и ввела задержки для имитации человеческой реакции, ИИ принципиально не подвержен когнитивной перегрузке. Более того, Килчер называет сомнительным тот факт, что AlphaStar сохраняет способность видеть свои собственные юниты за пределами текущего обзора камеры. И хотя защитники проекта могут возразить, что про-игроки используют «горячие клавиши» для слепого контроля войск, для человека отсутствие визуального контакта все равно остается огромным усложнением, тогда как ИИ получает здесь явное техническое преимущество. Исходный код системы, к сожалению, разработчиками опубликован не был.




