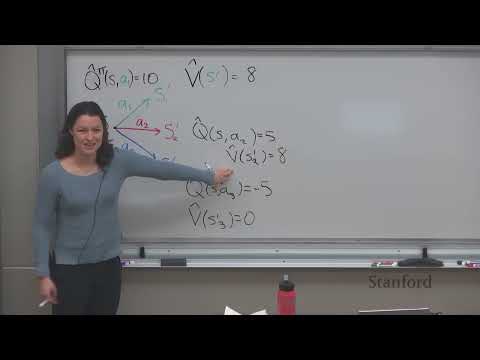RDLY
.ru
Тренды
Статьи
Темы
Люди
Поиск
Найти
Найдено: 3
1ч 05м
🔄 Лекция Стэнфорда о Reward Learning: как научить искусственный интеллект понимать человеческие цели
Stanford Online · 08.12.25
1ч 14м
🔄 Как устроен посттренинг языковых моделей: от SFT до RLHF
Stanford Online · 20.06.25
1ч 44м
🏗 Ян Дюбуа о создании LLM: почему данные и системы важнее архитектуры
Stanford Online · 27.08.24