Longformer: Революция в обработке длинных документов 0:00
Трансформеры стали фундаментом современных NLP-задач, но у классических моделей есть критическое ограничение — жесткий лимит на количество токенов, которые они могут обрабатывать одновременно. Янник Килчер в своем обзоре разбирает архитектуру Longformer, разработанную специалистами Allen AI (И. Белтеджи, М. Питерс, А. Коэн), которая призвана снять этот барьер и позволить моделям эффективно работать с длинными текстами.
Проблема «узкого горлышка» в классических трансформерах 1:08
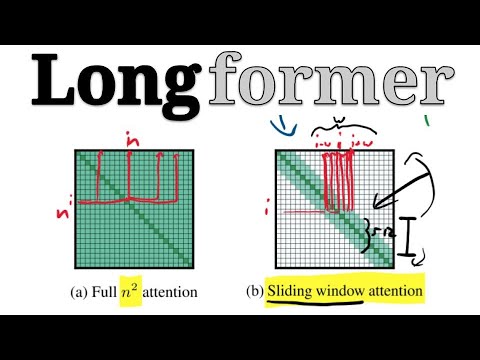
Классические архитектуры трансформеров сталкиваются с вычислительной сложностью порядка $O(N^2)$, где $N$ — длина последовательности. Это происходит потому, что в стандартном механизме внимания каждый токен «смотрит» на каждый другой токен, что требует огромных затрат памяти.
Раньше для работы с длинными документами их приходилось разбивать на независимые фрагменты. Это создавало проблему: модель теряла контекстуальные связи между частями текста, находящимися в разных блоках, так как механизм внимания не мог работать через границы фрагментов.
Как работает Longformer: механизмы внимания 7:08
Longformer меняет правила игры, заменяя полное квадратичное внимание более эффективными паттернами.
- Скользящее окно (Sliding Window Attention): По аналогии со сверточными нейронными сетями (CNN), каждый токен «смотрит» только на своих соседей в пределах окна размера $W$. Это снижает вычислительную сложность с $O(N^2)$ до $O(N \times W)$.
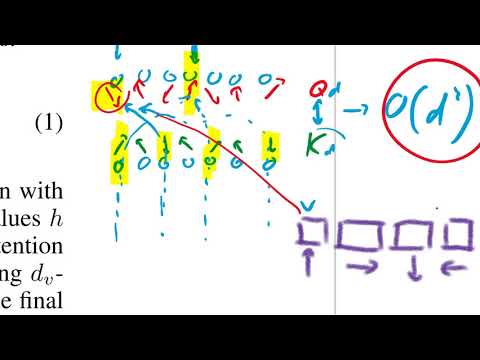
- Дилатированные (разреженные) окна: Чтобы быстрее распространять информацию по сети, авторы используют расширенные интервалы в окне внимания. Это позволяет модели захватывать глобальный контекст, не переходя к очень большой глубине. По мнению Килчера, решение использовать разные типы внимания на разных слоях (локальное внизу, глобальное вверху) выглядит как удачное инженерное компромиссное решение, помогающее модели лучше обучаться.
- Глобальное внимание (Global Attention): Для специфических токенов (например, CLS-токена в задачах классификации или вопросов в QA) вводится особый режим работы. Эти токены имеют доступ ко всему документу, что позволяет им собирать важную информацию со всей последовательности и передавать её дальше.
Технические детали и выводы 21:50
Для реализации этих механизмов авторы написали кастомные CUDA-ядра. Килчер отмечает интересный подход к обучению: модель стартует с чекпоинта RoBERTa (вариант BERT), копируя позиционные эмбеддинги, что позволяет значительно сократить время и ресурсы на дообучение.
Важно понимать, что Longformer не делает модели «легкими» для слабых машин. По словам ведущего, модель использует тот же объем памяти, что и классические аналоги, но при этом она способна обрабатывать гораздо более длинные документы, сохраняя при этом глобальную связность информации. Это делает Longformer мощным инструментом для задач, где понимание контекста всего документа важнее, чем работа с короткими фрагментами текста.