Представьте себе задачу: искусственному интеллекту нужно перевести аудиозапись человеческой речи в текст. На первый взгляд, это стандартная задача «последовательность в последовательность» (sequence-to-sequence). Однако в отличие от машинного перевода, где слова в разных языках могут меняться местами, в речи порядок звуков строго соответствует порядку букв в словах.
Янник Килчер, популярный ИИ-блогер и исследователь, разбирает работу Imputer — модели, разработанной Уильямом Чаном (William Chan), Джеффри Хинтоном (Geoffrey Hinton) и их коллегами из Google. Эта архитектура призвана оптимизировать обработку последовательностей, используя специфические свойства таких задач, как распознавание речи.
🧱 Суть Imputer: Монотонное выравнивание и динамическое программирование 0:00
Большинство современных нейросетей для обработки естественного языка (NLP) работают с любым типом последовательностей. Например, в классическом машинном переводе предложение «I like you» на немецкий переводится как «Ich mag dich» (прямой порядок), а на французский — «Je t'aime» (где объект перемещается в середину).
Imputer же нацелен на узкий, но критически важный сегмент задач, обладающих двумя характеристиками:
- Монотонное выравнивание: Порядок элементов на входе строго соответствует порядку на выходе. Первый звук соответствует первой букве, и так далее.
- Длина входа больше или равна длине выхода: В аудиозаписи фразы «I like you» будет гораздо больше звуковых отсчетов (сэмплов), чем букв в итоговом тексте.
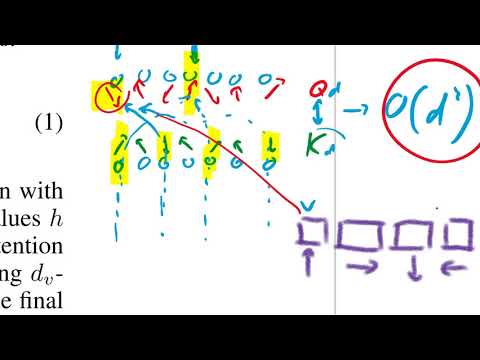
Чтобы эффективно связать длинный вход (X) и короткий выход (Y), Imputer представляет результат не просто как строку текста, а как последовательность той же длины, что и вход, заполняя «пустоты» между словами специальными токенами тишины . Задача модели — не просто предсказать буквы, но и правильно распределить их по временной шкале, отделяя значимые части от пауз.
⚡️ Компромисс между скоростью и качеством: Альтернативные подходы 6:04
Янник выделяет два экстремальных подхода, существующих в индустрии, и объясняет, где между ними находится Imputer.
Одношаговый метод (BERT / CTC)
Можно взять архитектуру типа BERT и попытаться классифицировать каждый входной кусочек аудио сразу . Это очень быстро, но возникает проблема «условной независимости».
- В чем риск: Когда модель предсказывает слово «like», она «забывает», что только что предсказала «I». Предсказания делаются параллельно и независимо друг от друга. По мнению Килчера, это может привести к грамматически бессмысленным предложениям, так как модель не учитывает контекст уже сгенерированных ею слов .
Пошаговое декодирование (Autoregressive)
Модель генерирует по одному токену за раз: сначала «I», затем, видя «I», генерирует «like» и так далее .
- Плюс: Максимальная точность и учет всех зависимостей.
- Минус: Если у вас 1000 входных отсчетов, вам нужно сделать 1000 последовательных шагов. Это крайне медленно .
🔄 Механика Imputer: Постоянное число шагов 10:41
Imputer предлагает элегантный «средний путь». Вместо того чтобы декодировать всё сразу или по одной букве, модель разбивает процесс на блоки фиксированного размера (B).
- На каждом шаге модель смотрит на входные данные и на то, что уже было «импутировано» (заполнено) ранее.
- В каждом блоке она заполняет те токены, в которых она максимально уверена на данный момент.
- Процесс повторяется, пока все пустые слоты не будут заполнены.
Главная инновация здесь в том, что количество шагов декодирования равно размеру блока (B) и не зависит от длины входной последовательности. Изменяя параметр B, разработчик может тонко настраивать баланс между скоростью работы и качеством предсказаний.
🧪 Обучение и архитектура: Взгляд под капот 13:18
Архитектурно Imputer напоминает BERT, но адаптированный для аудио: на входе стоит сверточная сеть (CNN) для обработки волновых форм, за которой следует классический трансформер с механизмом внимания (Attention) .
Однако Килчер высказывает скепсис относительно тренировочного процесса:
- Проблема распределения: При обучении используются эвристики (например, алгоритм CTC) для создания «идеальных» выравниваний и случайные маски для имитации пустых токенов .
- Аргумент автора: Килчер утверждает, что распределение данных, которое модель видит при обучении (случайные маски), может сильно отличаться от того, что она видит при реальной работе (постепенное заполнение блоков) .
- Защита авторов: Создатели из Google (включая легендарного Джеффри Хинтона) теоретически обосновывают, что их лосс-функция является нижней границей истинного лосса и в ожидании дает корректный результат .
🏁 Резюме 17:48
Imputer — это специализированный инструмент. Он не заменит универсальные языковые модели в задачах перевода, но для распознавания речи или генерации текста по губам (Lip Reading) его архитектура кажется Яннику крайне перспективной . Использование физических свойств задачи (монотонности) позволяет добиться высокой эффективности там, где общие модели тратят лишние ресурсы.