Ян Лекун, один из «крестных отцов» современного глубокого обучения и лауреат премии Тьюринга, представил концептуальную работу, описывающую путь к созданию автономного машинного интеллекта. В центре его предложенной архитектуры лежит JEPA (Joint Embedding Predictive Architecture) — модель, которая, по мнению автора, позволит машинам учиться так же эффективно, как это делают люди и животные, за счет предсказания состояний мира в абстрактном латентном пространстве.
🧠 Видение Яна Лекуна: Архитектура для автономного интеллекта 0:00
Янник Килчер начинает обзор с анализа статьи Яна Лекуна «A Path Towards Autonomous Machine Intelligence» . Этот документ представляет собой не просто описание конкретного алгоритма, а «позиционную статью» (position paper), в которой излагается общее видение того, как преодолеть ограничения современных нейросетей .
По мнению Лекуна, нынешние системы глубокого обучения слишком «жадны» до данных, не способны к планомерному рассуждению и не умеют строить иерархические планы на различных временных горизонтах . Основные цели предложенной архитектуры включают:
- Эффективное обучение: достижение уровня обучения, сравнимого с биологическими существами.
- Рассуждение и планирование: способность системы предсказывать последствия действий.
- Иерархия абстракций: представление мира на разных уровнях — от пикселей до высокоуровневых концепций .
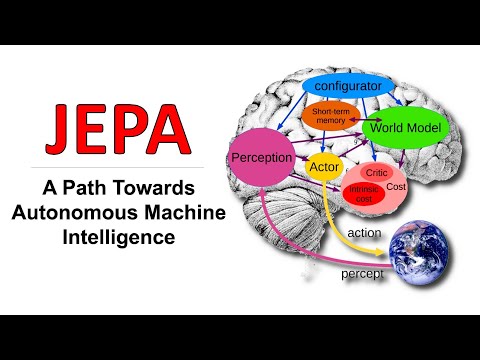
Килчер отмечает, что архитектура JEPA является «центральной деталью» этого пазла . Она задумана как дифференцируемая система, где каждый модуль может быть обучен с помощью градиентного спуска .
🌍 Мир как латентное пространство: Суть JEPA 3:43
Ключевое отличие JEPA от популярных генеративных моделей (таких как GPT или традиционные автоэнкодеры) заключается в том, что она является негенеративной . Вместо того чтобы пытаться предсказать каждый пиксель следующего кадра видео или каждое слово в тексте, JEPA предсказывает латентное представление будущего состояния .
В этой схеме участвуют два основных компонента:
- Энкодеры: переводят входные данные (например, изображения) в абстрактные векторы (латентное пространство) .
- Предиктор: предсказывает, каким будет латентный вектор
yна основе латентного вектораxи возможного действия .
Янник объясняет, что такой подход позволяет модели игнорировать нерелевантные детали . Если по улице едет автомобиль, модели не нужно предсказывать движение каждого листика на дереве на заднем плане; ей достаточно предсказать траекторию машины в абстрактном пространстве . По мнению Лекуна, это единственный способ избежать «проклятия размерности», которое делает предсказание сырых данных в высоком разрешении практически невозможным для сложных задач планирования .
🕹️ Режимы работы: Реактивное поведение против планирования 5:49
Лекун разделяет работу интеллекта на два режима, проводя аналогию с теорией Даниэля Канемана о «быстром» и «медленном» мышлении .
Режим 1: Реактивный эпизод
Это «подсознательное» действие. Сигнал идет напрямую от восприятия к актору (исполнителю), минуя модель мира . Актор просто выдает действие на основе текущего кадра. Так работают современные алгоритмы Model-Free Reinforcement Learning: они долго тренируются на наградах, а затем действуют мгновенно .
Режим 2: Планирование (Mode 2)
Здесь в игру вступает модель мира . Система не просто действует, она «проигрывает» возможные варианты будущего в своей голове:
- Актор предлагает последовательность действий .
- Модель мира предсказывает латентные состояния для каждого шага .
- Блок «критик» или функция стоимости оценивает, насколько результат соответствует цели .
Килчер подчеркивает важный технический нюанс: поскольку все модули JEPA дифференцируемы, система может использовать градиентный спуск во время инференса . Это означает, что нейросеть может оптимизировать свою последовательность действий «на лету», подправляя их так, чтобы минимизировать общую «энергию» (стоимость) . Это похоже на то, как создаются состязательные примеры (adversarial examples), но используется для поиска оптимального плана .
🛡️ Борьба с коллапсом: Регуляризация против контраста 29:44
Одной из главных проблем архитектур с совместным встраиванием (Joint Embedding) является коллапс . Если модель просто минимизирует расстояние между предсказанием и реальностью, она может «схитрить»: энкодеры начнут выдавать одну и ту же константу для любых входных данных . В таком случае предсказание всегда будет идеальным, но абсолютно бесполезным.
Ян Лекун выделяет два способа борьбы с этим:
- Контрастивные методы: подавать модели «плохие» примеры и заставлять ее увеличивать расстояние между ними . Однако в высоких размерностях найти информативные отрицательные примеры крайне сложно .
- Регуляризационные методы (выбор Лекуна): накладывать ограничения на саму структуру латентного пространства .
Для предотвращения коллапса в JEPA используются три типа регуляризации :
- Минимизация информативности латентной переменной
z(чтобы она не могла просто «переносить» ответy) . - Максимизация информативности представлений
xиy(чтобы они не превращались в константу, а использовали весь объем доступного пространства) . - Использование таких методов, как VICReg или Barlow Twins, которые заставляют ковариационную матрицу представлений быть близкой к единичной, предотвращая схлопывание признаков .
🧬 Иерархия и эмоции машин 47:03
Финальная форма концепции — Hierarchical JEPA (H-JEPA). Она позволяет планировать на разных уровнях абстракции . Высокоуровневая модель может поставить задачу «доехать до аэропорта» (длинный временной горизонт), а низкоуровневая — расшифровать это в конкретные движения рулем и педалями .
В завершение Янник цитирует довольно смелые философские выводы Лекуна :
- Эмоции: Лекун утверждает, что интеллектуальные агенты неизбежно будут обладать эквивалентом эмоций, так как эмоции — это предвкушение результата, рассчитанное критиком .
- Здравый смысл: Он может возникнуть как побочный продукт обучения моделей мира, которые замечают нарушения логики и согласованности событий .
- Символы: Лекун полагает, что на очень высоких уровнях абстракции мир становится настолько дискретным, что традиционные методы поиска (например, поиск по деревьям Монте-Карло) могут заменить градиентный спуск .
Автор ролика резюмирует, что хотя многие детали архитектуры пока остаются «расплывчатыми» (hand-wavy), JEPA предлагает фундаментально иной путь развития ИИ, отличный от простого масштабирования языковых моделей .




