Самообучение: «Темная материя» интеллекта и будущее ИИ 0:00
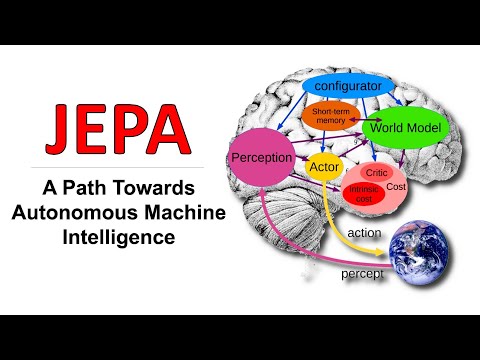
Ян Лекун и Ишан Мишра из исследовательской лаборатории Facebook AI (FAIR) в своем блог-посте представили концепцию самообучения (Self-Supervised Learning) как ключевой способ достижения «здравого смысла» у ИИ. В отличие от классического обучения с учителем, которое требует колоссальных объемов размеченных данных, самообучение позволяет нейросетям извлекать знания непосредственно из самих данных, что критически важно для создания универсальных моделей. По мнению ведущего канала Янника Килчера, данный подход — это попытка синтезировать разрозненные идеи исследователей Meta в единую дорожную карту развития машинного обучения.
Почему классический подход зашел в тупик? 1:20
Современный ИИ, обучаемый методами обучения с учителем, демонстрирует высокую эффективность в узкоспециализированных задачах, но сталкивается с рядом ограничений.
- Проблема масштабируемости: Для достижения более высокого уровня интеллекта требуются огромные объемы данных. Ручная разметка становится непомерно дорогой и физически невозможной для всех задач в мире.
- Отсутствие универсальности: Специализированные модели плохо справляются с задачами, выходящими за рамки их обучения.
- Биологический контраст: Человеческий ребенок способен распознать корову, увидев всего несколько примеров. ИИ же требует тысячи изображений и все равно может ошибиться, если корова лежит на пляже — в необычной для «датасета» ситуации.
Авторы статьи утверждают, что биологический интеллект обладает «здравым смыслом» — фоновыми знаниями о законах физики и структуры мира, которые мы приобретаем через постоянные наблюдения. Этот «здравый смысл» называют «темной материей» искусственного интеллекта.
Механика самообучения: предсказание скрытого 7:31
Самообучение — это не «обучение без учителя», а способ автоматической генерации меток (supervisory signals) из самих данных. Базовая формула выглядит так: мы скрываем часть данных и заставляем модель предсказать их на основе оставшейся «видимой» части.
Примеры реализации:
- NLP (текст): Модель типа BERT маскирует слово в предложении («Это — кот»), и задача ИИ — предсказать пропущенный элемент. Здесь пространство возможных ответов ограничено словарем, что позволяет модели выдавать вероятностное распределение и оценивать неуверенность.
- Видео: Предсказание будущих кадров на основе прошлых или заполнение пропущенных фрагментов видеоряда.
Идея состоит в том, что если модель научится предсказывать будущее состояние мира, она неминуемо «впитает» структуру этого мира, создав мощные репрезентации данных. Такие репрезентации позволяют адаптироваться к новым задачам с минимальным количеством примеров.
Проблема размерности и неопределенности 18:04
Перенос успехов из области текста в область компьютерного зрения сталкивается с фундаментальными препятствиями.
- Непрерывность: Если в тексте мы выбираем из ограниченного набора слов, то в изображении количество вариантов заполнения «дыры» бесконечно.
- Отсутствие классификатора: Построить классификатор для всех возможных вариантов патчей изображения невозможно.
- Сложность неопределенности: Прямое предсказание «среднего» значения (например, прозрачный бокал вместо четкого объекта) приводит к нереалистичным результатам, а классическое обучение не дает модели выразить неопределенность.
Энергетические модели и борьба с коллапсом 26:52
Ян Лекун предлагает рассматривать самообучение через призму энергетических моделей (Energy-Based Models, EBM), где ИИ оценивает «совместимость» объектов (например, кадра из прошлого и кадра из будущего). Низкая энергия означает высокую совместимость, высокая — несовместимость.
В компьютерном зрении популярны сиамские сети, где модель учится тому, что разные кропы (фрагменты) одного изображения должны иметь похожие репрезентации. Однако такие сети склонны к «коллапсу» — состоянию, при котором модель игнорирует входные данные и выдает идентичные ответы для всего.
Чтобы избежать коллапса, используются:
- Контрастивные методы: Сравнение положительных пар (совпадающих) с отрицательными («несовместимыми»). Это крайне дорого вычислительно из-за необходимости подбирать «сложные» негативные примеры.
- Методы регуляризации: Ограничение емкости модели, чтобы она не могла просто «запомнить» ответ, а была вынуждена учить структуру данных.
Путь вперед: латентные переменные 44:33
Авторы полагают, что будущим самообучения станут предиктивные модели с латентными переменными. Суть подхода в добавлении переменной $z$ (скрытой переменной), варьируя которую, модель может генерировать множество правдоподобных вариантов будущего.
Это решение позволяет:
- Сохранить детерминизм архитектуры.
- Представлять неопределенность (множество вариантов вместо одного усредненного).
- Избежать ручного выбора «позитивных» и «негативных» пар, характерного для контрастивных методов.
В конце статьи Лекун упоминает модель SEER — огромную нейросеть, обученную на миллиарде изображений из Instagram. Несмотря на критику ведущего по поводу доступности таких мощностей, это демонстрирует готовность FAIR масштабировать методы самообучения на неразмеченные данные в глобальных масштабах.