В мире обработки естественного языка (NLP) произошел тектонический сдвиг с появлением BERT — модели, которая пересмотрела подходы к обучению машин пониманию человеческой речи. Исследователь Янник Килчер разбирает фундаментальную работу инженеров Google AI Language, объясняя, почему «двунаправленность» стала ключом к новому государству в индустрии ИИ.
🤖 Что такое BERT и почему вокруг него столько шума? 0:15
BERT (Bidirectional Encoder Representations from Transformers) — это нейросетевая модель, разработанная Джейкобом Девлином и его коллегами из Google AI Language . Главная особенность BERT заключается в том, что она приходит к пользователю уже «предварительно обученной» (pre-trained) на гигантском корпусе текстов.
По словам Янника Килчера, это самая обсуждаемая и «хайповая» модель современности . Она способна принимать последовательности языковых токенов и адаптироваться практически к любой задаче NLP — от классификации предложений до ответов на вопросы — с минимальным дополнительным обучением.
🔄 Эволюция: от LSTM к трансформерам и двунаправленности 1:14
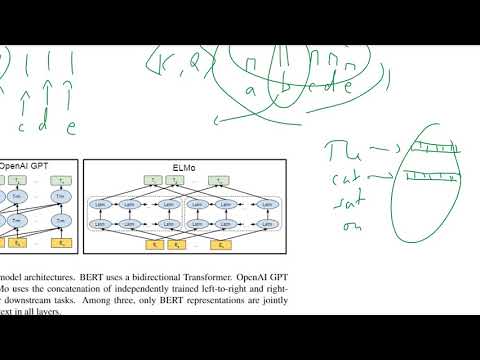
Чтобы понять инновацию BERT, Килчер сравнивает её с предшественниками: классическими моделями OpenAI Transformer (GPT-1) и ELMo .
- Классические трансформеры (OpenAI): Работают по принципу «слева направо» . Это означает, что при интерпретации конкретного слова модель видит только контекст, идущий перед ним. Это ограничивает понимание смысла в сложных предложениях.
- ELMo: Использует две независимые сети LSTM — одна читает текст слева направо, другая — справа налево . Однако, по мнению Килчера, это решение «поверхностно», так как в конце векторы просто объединяются (конкатенируются), а сама модель остается «слепой» к общему контексту во время обучения .
- BERT: Читает всё предложение целиком и сразу . В каждом слое архитектуры внимание (attention) направлено одновременно и на левый, и на правый контекст.
🎭 Секрет обучения: маскировка и предсказание следующего предложения 14:47
Поскольку классическое обучение (предсказание следующего слова) невозможно в двунаправленной модели (слово «видит» само себя в будущем), разработчики Google внедрили два новых метода обучения без учителя:
- Masked Language Model (MLM): В предложении случайным образом скрываются (маскируются) некоторые слова. Например: «Человек пошел в [MASK] за хлебом» . Модель должна угадать слово, используя информацию с обеих сторон.
- Next Sentence Prediction (NSP): Модели подают две фразы и спрашивают, является ли вторая логическим продолжением первой . В 50% случаев это реальная пара из текста, в 50% — случайный набор фраз (например, предложение про магазин и предложение про пингвинов) .
🧩 Токенизация и «трюк» с WordPieces 20:44
Одной из технических проблем NLP является огромный объем словаря. BERT использует систему WordPieces — некий промежуточный вариант между целыми словами и отдельными символами .
- Если слово встречается часто (например, «to»), оно остается целым.
- Редкие или сложные слова разбиваются на осмысленные части (суб-токены). Например, слово «playing» может быть разбито на «play» и окончание «##ing» .
- Это позволяет модели понимать смысл новых слов через их корни и суффиксы, а также избегать проблем с «незнакомыми словами» (Out-of-vocabulary), которые часто возникают в именах собственных, таких как PewDiePie .
🏆 Универсальность: 11 побед в тестах из 11 28:47
Килчер подчеркивает, что BERT показал лучшие результаты (state-of-the-art) во всех 11 протестированных задачах . Обученную модель можно «подстроить» (fine-tune) под конкретную задачу невероятно быстро:
- Классификация сообщений: К BERT добавляется один простой слой логистической регрессии, который переводит скрытые векторы в метки классов (например, «эмоциональная окраска» или «противоречие») .
- SQuAD (ответы на вопросы): Модель ищет конкретный фрагмент (span) в тексте Википедии, выделяя токены начала и конца ответа .
- NER (распознавание сущностей): BERT определяет, является ли каждое слово именем, организацией или географическим объектом .
📊 Итоги и выводы: дело не только в ресурсах 38:26
Хотя модель BERT Large огромна (24 слоя трансформеров) и обучалась на мощностях Google (TPU), исследование доказывает, что успех не только в «железе». Авторы провели абляционные исследования (Ablation Studies), отключая разные части системы .
Результаты показали:
- Удаление задачи предсказания следующего предложения (NSP) снижает точность .
- Переход от двунаправленности к обучению «только слева направо» ведет к серьезному обвалу метрик .
Янник Килчер заключает, что BERT — это мощнейший инструмент, который теперь доступен каждому для скачивания и адаптации под свои нужды, даже если у вас нет доступа к суперкомпьютерам Google .