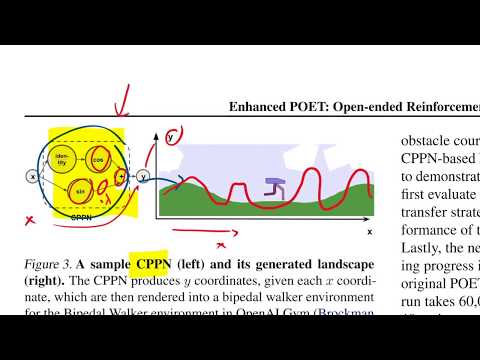
Разработка потокового бэкенда для инференса LLM: Практическое руководство
Создание пользовательского интерфейса, аналогичного ChatGPT, где ответ модели отображается «на лету» (по мере генерации токенов), требует сложной архитектуры. В данном видео ведущий канала Янник Килчер (Yannic Kilcher) демонстрирует процесс модификации text-generation-inference — open-source проекта для запуска больших языковых моделей (LLM). Цель разработки — внедрить поддержку стриминга (потоковой передачи) ответов, проходя через все технологические слои: от Python-кода модели, взаимодействующего через gRPC, до Rust-сервера и клиентского веб-интерфейса.
⚙️ Архитектура системы и задача 0:27
Для реализации стриминга Янник Килчер детально описывает путь токена от видеокарты до браузера пользователя. Основная сложность заключается в том, что существующая библиотека Hugging Face по умолчанию генерирует ответ целиком, а не токен за токеном.
- Технологический стек:
- Python: Используется для кода самих моделей (библиотека Hugging Face).
- Rust: Применяется для высокопроизводительного веб-сервера, так как Python плохо справляется с многопоточностью при необходимости прямого взаимодействия между запросами.
- gRPC: Протокол для эффективного взаимодействия между Python-процессом модели и Rust-бэкендом.
- Redis: Очередь для планирования задач.
- WebSockets: Используются для двунаправленной связи между воркерами и бэкендом.
- Server-Sent Events (SSE): Механизм односторонней передачи данных от сервера к клиенту для реализации стриминга токенов в реальном времени.
🐍 Модификация Python-части (Hugging Face) 11:16
Основная точка входа для генерации — функция generate_token в коде модели (типа CausalLM).
- Анализ логики: Функция итерируется не по длине последовательности, а по размеру батча, генерируя один токен для каждого активного запроса в батче.
- Точка внедрения: В текущей реализации метод возвращает список результатов только после завершения генерации. Янник предлагает модифицировать его так, чтобы он возвращал промежуточные токены на каждом шаге.
- Data Classes: Для передачи данных создается класс
Intermediateс полямиrequest_id(целое число согласно protobuf) иtoken. - Protobuf: Так как интерфейсы описаны через Protobuf, необходимо обновить определения сообщений, добавив в них списки промежуточных результатов, и пересобрать сгенерированный код с помощью
make install.
🦀 Переход к Rust: Маршрутизатор и стриминг 32:51
После подготовки Python-бэкенда работа переносится в Rust-часть проекта (router).
- Работа с каналами: Для межпотокового взаимодействия используются каналы (
mpsc— multi-producer, single-consumer). Поскольку стандартные One-Shot каналы не подходят для потока данных, внедряются unbounded-каналы (без лимита), которые позволяют непрерывно отправлять токены до завершения генерации. - Реализация стриминга в Axum: Янник использует Rust-фреймворк Axum для создания эндпоинта
/generate_stream. Вместо стандартногоHTTP responseэндпоинт теперь возвращаетSSE stream. - Async Streams: Для конвертации данных из каналов в поток используется
async_stream. Это позволяет собирать токены из gRPC-ответов и «выдавать» их в SSE-поток, который обрывается только после получения сигнала об окончании генерации (флагis_end).
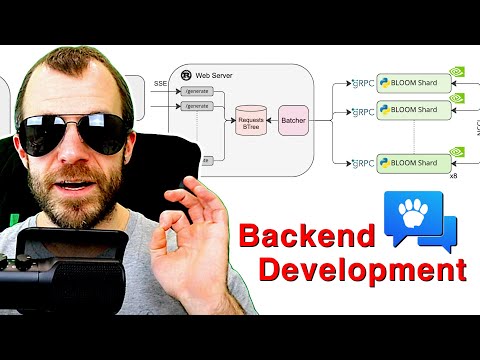
🌐 Масштабируемая сеть Open Assistant 1:18:27
В финальной части видео демонстрируется интеграция разработанного «стриминг-бэкенда» в экосистему Open Assistant. Система работает как распределенная сеть:
- Любой желающий может подключить свою видеокарту как воркер через
WebSocket. - Redis управляет очередью задач, направляя их к доступным воркерам.
- Результаты передаются по цепочке:
GPU->Hugging Face->gRPC->Rust Batcher->SSE->WebSocket->Redis->SSE->User Client.
Янник подчеркивает, что это позволяет пользователю видеть ответ модели (например, шутку или длинный текст) почти мгновенно, не дожидаясь завершения всей генерации.