В современном машинном обучении доминируют архитектуры типа Transformer, однако стандартные декодерные модели имеют фундаментальные ограничения в последовательных рассуждениях. Популярный ИИ-блогер Янник Килчер разбирает научную работу исследователей из Facebook AI Research (FAIR) и Inria, которые предложили альтернативу — Feedback Transformer (трансформер с обратной связью). Эта архитектура жертвует параллелизмом при обучении, но взамен открывает возможность для глубокого многошагового анализа данных при меньшем количестве слоев.
🏗️ Проблема параллелизма и упущенная информация 0:13
В современных декодерных трансформерах, таких как GPT-3, применяется метод причинного маскирования (causal masking). Это техническое решение позволяет модели обучаться параллельно на огромных массивах данных. Однако за высокую скорость обучения приходится платить скрытым компромиссом: модель фактически игрирует часть уже вычисленной высокоуровневой информации.
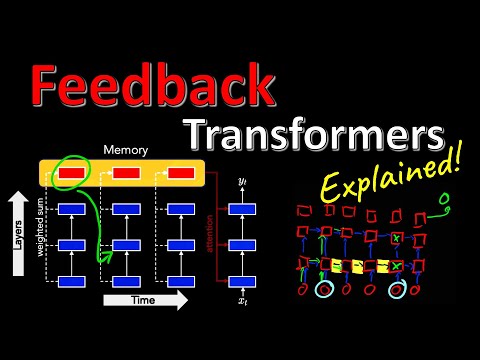
В процессе генерации текста или прогнозирования последовательности стандартный трансформер направляет потоки данных исключительно снизу вверх — от нижних слоев к верхним, и вперед по временной шкале. Модель не способна повторно использовать скрытые представления самых верхних слоев из прошлых шагов для вычислений на нижних слоях текущего шага, хотя технически эта информация уже доступна. Архитектура Feedback Transformer призвана исправить этот недостаток за счет внедрения памяти обратной связи.
🔄 Ограничения RNN и классическое внимание 3:29
Чтобы понять суть проблемы, Янник Килчер предлагает вернуться к истокам последовательного моделирования — рекуррентным нейронным сетям (RNN) и сетям долгой краткосрочной памяти (LSTM).
Особенности работы RNN и трансформеров:
- Поток данных в RNN: В рекуррентных сетях входные данные последовательно преобразуются в скрытые (латентные) представления. Информация передается по цепочке от одного временного шага к следующему, формируя горизонтальные связи внутри каждого слоя.
- Проблема длинных дистанций: Если двум токенам в тексте (например, имени «Фрэнк» и местоимению «он») необходимо связаться для понимания контекста, сигналу в RNN приходится преодолевать длинный путь через множество вычислительных шагов. Это приводит к затуханию сигнала и накоплению шума.
- Решение трансформеров: Классический трансформер решает эту проблему радикально. С помощью механизма внимания (attention механизм) каждый узел в слое может напрямую агрегировать информацию со всех узлов предыдущего слоя всего за один вычислительный шаг, независимо от расстояния между ними.
💻 Код, переменные и лимиты многошаговой логики 9:22
Несмотря на превосходство трансформеров над RNN на длинных дистанциях, они сталкиваются с жесткими ограничениями при выполнении сложных последовательных задач. В качестве примера авторы исследуемой научной работы приводят задачу интерпретации программного кода. Модели подается текстовый фрагмент с объявлением переменных, инкрементами, декрементами и условными операторами if, а на выходе ожидается результат работы программы.
Одиночный слой любой нейронной сети по своей сути выполняет линейные операции, дополненные нелинейной функцией активации на выходе. Подобная структура не способна в рамках одного слоя разрешить логические парадоксы (например, задачу XOR) или последовательно отслеживать динамическое изменение состояний нескольких переменных.
Для реализации условной логики стандартный трансформер вынужден задействовать несколько слоев последовательно. Один слой лишь линейно объединяет значения, следующий — оценивает условие, третий — выполняет ветвление. В результате глубина и сложность логических рассуждений стандартной модели жестко ограничены количеством ее физических слоев на всю последовательность.
🧠 Архитектура Feedback Transformer: сквозная память 20:49
Feedback Transformer кардинально меняет правила игры, позволяя информации перемещаться не только вверх, но и сверху вниз по иерархии слоев. На каждом новом шаге авторегрессионной генерации модель получает доступ к репрезентациям самого высокого уровня, вычисленным для предыдущих токенов.
Прямое вычисление внимания ко всем скрытым состояниям прошлых шагов привело бы к колоссальному перерасходу вычислительной памяти. Чтобы избежать этого, авторы внедрили механизм сжатия:
- После того как токен прошел через все слои, его скрытые представления и эмбеддинги объединяются.
- На основе этого слияния формируется единый вектор — репрезентация памяти токена (memory representation).
- Все последующие слои для новых токенов обращаются уже не к индивидуальным промежуточным слоям прошлого, а к этой глобальной памяти.
По оценке Янника Килчера, ключевое преимущество такого подхода заключается в том, что глубина рассуждений становится практически неограниченной и привязывается к каждому отдельному токену, а не к длине последовательности в целом. Модель может «сохранить» значение переменной в высокоуровневой памяти, а на следующих шагах нижние слои будут считывать и модифицировать ее, используя всю глубину вычислений повторно.
📐 Гибрид или новый класс: мнение Янника Килчера 31:36
«Если вы просто наклоните эту схему набок, вы увидите структуру, которая до боли напоминает усложненную рекуррентную нейронную сеть», — делится своим наблюдением Янник Килчер.
По мнению ведущего, Feedback Transformer представляет собой своеобразный гибрид, находящийся на полпути между классической RNN и чистым трансформером. Килчер напоминает, что исторически механизмы внимания создавались именно для того, чтобы помочь рекуррентным сетям преодолеть проблему короткой памяти. В Feedback Transformer разработчики фактически убрали стандартные жесткие рекуррентные связи между соседними ячейками, заменив их гибким обращением к агрегированным блокам памяти.
📊 Результаты экспериментов: скорость против качества 37:15
В тестах на моделирование языка классические трансформеры демонстрируют резкое падение качества генерации при уменьшении количества слоев. В то же время Feedback Transformer, по данным исследования, удерживает высокую планку точности даже в конфигурациях с малой глубиной сети. Архитектура также показала отличные результаты в задачах обучения с подкреплением (Reinforcement Learning) в средах Grid World, где критически важно удерживать долгосрочные взаимосвязи.
Важные выводы из абляционных исследований и тестов производительности:
- Внимание только к вершине (Top-only attention): Эксперименты показали, что если позволить модели обращаться исключительно к самому верхнему слою репрезентаций прошлого шага (без сложного взвешивания всей памяти), то она сохраняет почти 100% эффективности полноценного Feedback Transformer.
- Парадокс скорости обучения и инференса: Из-за невозможности распараллелить процесс вычислений, Feedback Transformer обучается значительно медленнее стандартных моделей. Однако на этапе инференса (работы готовой модели) он обгоняет классический трансформер. Это связано с тем, что при генерации оба алгоритма работают пошагово, но архитектура с обратной связью позволяет эффективно делить вычисления ключей (Keys) и значений (Values) между слоями.
Заменяет ли эта технология привычные нам трансформеры? Как утверждает Килчер, в ближайшее время этого не произойдет. Если у разработчиков есть неограниченные вычислительные ресурсы и время, масштабные стандартные трансформеры все равно выиграют за счет колоссальной скорости параллельного обучения. Тем не менее, для специфических задач с жесткими ограничениями по памяти, требующих комплексной логики и длинных цепочек рассуждений, Feedback Transformer выглядит крайне перспективным решением.




