self-attention
15 статей
 1ч 14м
1ч 14м💍 Филипп Изола: «Трансформер — это кольцо всевластия в современном ИИ»
 1ч 16м
1ч 16м🧩 Как работают трансформеры: От self-attention до BERT и Hugging Face
 1ч 16м
1ч 16м🌍 Как устроена архитектура Transformers и зачем ей скалярное произведение
1ч 16м🛠 «Они захватили всё»: Рама Рамакришнан о принципах работы трансформеров
 1ч 41м
1ч 41м🎓 Стэндфордский курс CME295: глубокое погружение в архитектуру Transformer
 53 мин
53 мин🤖 „Мы рассматриваем роботов как токены“: новая архитектура управления роем
 3ч 28м
3ч 28м🚀 Иллюзия разума: математика и архитектура современных LLM
 1ч
1ч👓 Почему нейросети «близоруки»: Федерико Барберо о фундаментальных изъянах внимания
 1ч 56м
1ч 56м📊 Как Андрей Карпатый собрал GPT из 200 строк кода
 48 мин
48 мин🛑 Как Nyströmformer решает проблему квадратичной сложности в архитектуре Transformer
48 мин🧠 Линейное внимание вместо квадратичного: спасёт ли метод Найстрема современные нейросети?
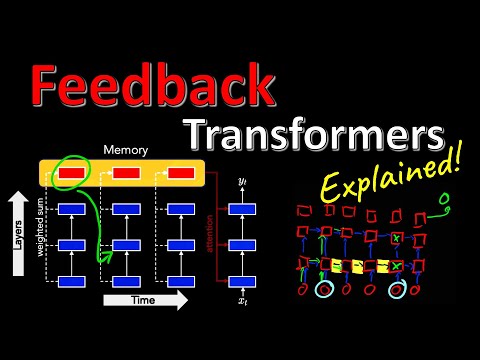 43 мин
43 мин🏗 Как Feedback Transformer решает проблему многошаговых рассуждений в ИИ?
 59 мин
59 мин🚀 Быстрее EfficientNet в 4.5 раза: Янник Килчер объясняет устройство LambdaLayers
 50 мин
50 мин🧠 Linformer: как аппроксимация матриц низкого ранга ускоряет трансформеры
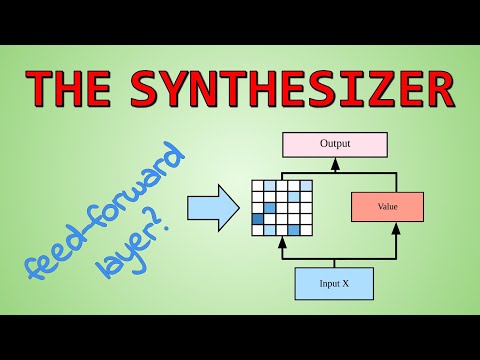 48 мин
48 минЯнник Кильхер о Synthesizer: переосмысление внимания в Transformer