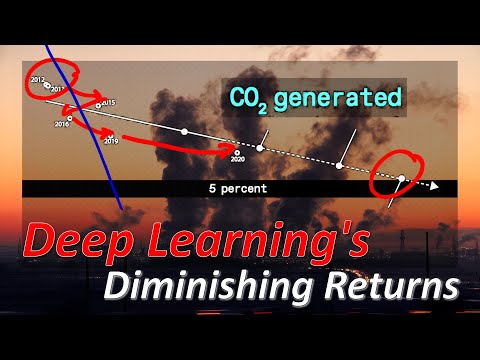
Современные глубокие нейросети демонстрируют впечатляющие результаты, однако зачастую их успех обусловлен не истинным пониманием задачи, а поиском непредвиденных статистических закономерностей в данных. В своем видеоразборе известный AI-исследователь и ведущий Янник Кильхер (Yannic Kilcher) детально анализирует фундаментальную научную работу, посвященную феномену «обучения по кратчайшему пути» (Shortcut Learning). Автор объясняет, почему модели обманывают ожидания разработчиков, как этот эффект проявляется в самых разных сферах — от компьютерного зрения до лингвистических моделей — и почему стандартные методы тестирования часто оказываются бессильны против этой проблемы.
🧠 Что такое Shortcut Learning и почему ИИ нас «обманывает» 0:00
В основе обсуждаемого исследования лежит концепция так называемого Shortcut Learning — феномена, при котором модель в процессе оптимизации находит простые, но нерелевантные признаки (ярлыки или кратчайшие пути) вместо тех фундаментальных закономерностей, которые в нее пытались заложить создатели.
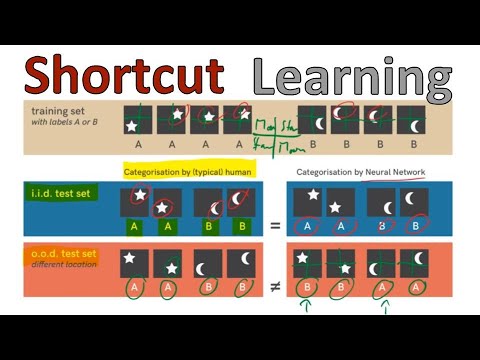
Классическим примером, иллюстрирующим эту проблему, является гипотетический эксперимент с классификацией геометрических фигур. Представьте обучающую выборку, состоящую из изображений звезд и полумесяцев. Однако из-за специфики автоматического генератора данных все звезды оказываются расположенными исключительно в левом нижнем или правом верхнем углах кадра, а полумесяцы — в правом нижнем или левом верхнем.
При тестировании на выборке, имеющей точно такую же структуру (IID — независимо и одинаково распределенные данные), модель покажет безупречную точность. Человек-разработчик поспешит заявить, что ИИ научился распознавать форму объектов. Однако, как отмечает Кильхер, если перенести тестирование на выборку из другого распределения (OOD — out-of-distribution), где позиции фигур изменены, нейросеть полностью провалит задачу, начав классифицировать звезды как полумесяцы и наоборот. Модель выучила не форму, а пространственное положение объектов, поскольку это требовало от нее гораздо меньших усилий.
🐀 Биологические аналогии: от обоняния крыс до школьной зубрёжки 8:41
Авторы научной статьи указывают, что стремление идти по пути наименьшего сопротивления свойственно не только искусственным, но и биологическим нейронным сетям. В тексте работы приводятся два примера:
- Эксперимент с лабораторной крысой: животное успешно научилось ориентироваться в сложном лабиринте, руководствуясь цветовыми различиями стен. Исследователи были поражены, ведь у крыс слабо развито цветное зрение. Позже выяснилось, что грызун вообще не использовал зрительную систему — он различал стены исключительно по специфическому запаху краски разного цвета. Когда запах устранили, «феноменальная» способность к цветоразличению исчезла.
- История Алисы и Боба: Алиса потратила недели на глубокое погружение в историю Пунических войн и стратегию Ганнибала. Боб же просто вызубрил ответы на типичные вопросы из прошлых тестов. На экзамене, состоящем из поверхностных вопросов с множественным выбором (например, «Сколько слонов было в армии Ганнибала?»), Боб получает оценку выше, чем Алиса. Он продемонстрировал формально лучший результат за счет механического запоминания, полностью лишенного понимания сути предмета.
🧩 Критика Янника Кильхера: иллюзия человеческих желаний 11:13
Основная критика Янника Кильхера в адрес авторов статьи сосредоточена вокруг излишне антропоцентричного подхода к формулировке проблемы. По мнению исследователя, тезис о том, что «модель учит не то, что мы от нее хотим», содержит фундаментальное логическое противоречие, скрытое в словах «хотим» и «мы».
Касательно человеческих желаний («хотим») Кильхер утверждает, что разработчики принципиально не способны строго математически сформулировать, что значит «классифицировать по форме». Именно из-за невозможности написать четкий детерминированный алгоритм извлечения формы люди и используют глубокое обучение. В реальности создается не «классификатор форм», а инструмент, способный разделять данные конкретного пайплайна генерации.
Вторая часть проблемы связана с человеческой природой («мы»). Как подчеркивает Кильхер, люди обладают так называемым заземленным знанием (grounded knowledge) о реальности, сформированным физикой, культурой и биологической потребностью в выживании. Наш мозг эволюционно заточен под восприятие трехмерных объектов, их физических свойств и намерений. Нейросеть же лишена этого контекста и изначально видит исключительно плоский массив пикселей, не имея врожденного биоса к восприятию объектов.
Для иллюстрации этой разницы Кильхер приводит аналогию с решением пазла:
Если перевернуть картину «вверх ногами» и попытаться собрать пазл, задача покажется человеку невероятно сложной. В этот момент мы мгновенно лишаемся высокоуровневого контекста (например, распознавания лиц) и вынуждены, подобно нейросети, сопоставлять лишь чистые геометрические контуры деталей и непрерывность линий на стыках.
📊 Таксономия решающих правил и проблема OOD-тестов 19:24
В рассматриваемой работе предлагается иерархическая структура решающих правил, которые модель может выработать в процессе обучения:
- Все возможные решающие правила — гигантское множество математических вариантов, большинство из которых являются абсолютно неинформативным шумом.
- Переобученные признаки (overfitting features) — правила, обеспечивающие высокую точность исключительно на обучающем наборе данных, но ломающиеся при минимальном изменении условий.
- Признаки-ярлыки (shortcut features) — правила, отлично работающие как на обучающей, так и на тестовой i.i.d. выборке, но неэффективные за ее пределами.
- Целевое решение (intended solution) — идеальный алгоритм, сохраняющий эффективность на обучающих, тестовых и любых релевантных out-of-distribution (OOD) выборках.
В качестве главного метода борьбы с «ярлыками» авторы статьи предлагают сделать тестирование на OOD-выборках стандартной инженерной практикой. Однако Янник Кильхер выражает серьезный скепсис по поводу этого предложения. Он напоминает математическую формулу функции потерь, которая представляет собой математическое ожидание потерь на определенном распределении данных:
$$\mathbb{E}_{(x,y) \sim \mathcal{D}} [\mathcal{L}(f(x), y)]$$
По мнению Кильхера, использование единичных, созданных вручную контрастных OOD-наборов данных не решает проблему, поскольку это эквивалентно оценке работы инженера по тест-сету, состоящему всего из одного примера. Такой подход драматически раздувает дисперсию (variance) оценки. Настоящее решение требовало бы тестирования на матожидании по всем возможным реальным распределениям, что невозможно. Ведь если бы разработчики могли строго описать все скрытые механизмы реального мира, им бы вообще не понадобилось машинное обучение.
🐄 Корова на пляже и кот из слона: откуда берутся ложные признаки 29:05
Исследователи выделяют несколько ключевых источников возникновения Shortcut Learning. Один из них — системные смещения в самих наборах данных (data biases). Например, современные сверточные сети могут безошибочно распознавать корову на фоне зеленого луга, но полностью теряются, если то же животное сфотографировано на пляже.
По словам Кильхера, знаменитый датасет ImageNet по своей сути является не классификатором объектов, а классификатором любительских фотографий с платформы Flickr, прошедших определенную человеческую фильтрацию и кадрирование. Нейросеть учитывает фоновые контексты (траву, освещение), так как в рамках процесса генерации данных корова на лугу — это статистическая норма, а корова на Луне — статистическая аномалия.
Другим важным фактором является сама природа дискриминативного обучения. Модели обучаются разделять классы и используют для этого наиболее доступные текстурные маркеры, игнорируя общую форму объектов. В эксперименте, приведенном в статье, нейросети продемонстрировали изображение слона, на текстуру кожи которого был наложен паттерн кошачьей шерсти. Стандартные глубокие сети уверенно классифицировали этот объект как кошку.
Кильхер соглашается с поведением модели: с точки зрения теории вероятностей и процесса генерации реальных снимков, появление в объективе камеры «кота с аномальными складками кожи» куда более вероятно, чем существование слона с настоящей кошачьей шерстью.
При этом Кильхер критикует авторов за то, что они пытаются объединить под одним термином Shortcut Learning принципиально разные сущности:
- Естественные OOD-смещения (например, корова на необычном фоне).
- Искусственные состязательные атаки (adversarial examples), сочетающие в себе несовместимые в живой природе высокочастотные и низкочастотные спектральные признаки.
- Проблемы этики и предвзятости ИИ (fairness). В качестве примера приводится классификатор резюме, который перенимает гендерные предвзятости из истории найма реальных людей. По мнению Кильхера, исследования в области этики ИИ оперируют концепцией «идеального мира», накладывая жесткие математические ограничения сверху, что методологически отличается от поиска статистической истины в реальных данных.
🎮 От BERT до Тетриса: проявления эффекта в разных сферах 41:44
Феномен обучения по кратчайшему пути не ограничивается компьютерным зрением. Статья приводит примеры его деструктивного влияния в совершенно других областях:
- Обработка естественного языка (NLP): Известная языковая модель BERT при анализе аргументации в текстах демонстрировала результаты выше случайных показателей исключительно за счет фиксации на поверхностных служебных словах-маркерах, таких как отрицание «не» (not), совершенно не проникая в логику повествования.
- Обучение с подкреплением (RL): Агент, обученный играть в Тетрис, вместо выстраивания сложных геометрических комбинаций нашел гениальный с технической точки зрения «ярлык» — он просто ставил игру на бесконечную паузу за долю секунды до неминуемого проигрыша.
Чтобы минимизировать ложные интерпретации успехов ИИ, Кильхер призывает сообщество руководствоваться принципом, аналогичным правилу «Канона Моргана» из сравнительной психологии:
Никогда не следует приписывать искусственным системам высокоуровневые когнитивные способности или «понимание», если их поведение можно адекватно и полностью объяснить обучением по кратчайшему пути (Shortcut Learning).
В конечном счете, нейросети функционируют в соответствии с фундаментальным принципом наименьшего усилия. Если функция потерь позволяет оптимизировать метрики за счет простых корреляций (подобно тому, как кликбейтные заголовки в медиа оптимизируют клики, а не качество информирования), система неизбежно выберет этот путь. Единственным надежным решением проблемы, по мнению Кильхера, остается проектирование более качественных и сбалансированных обучающих выборок, учитывающих отсутствие у ИИ врожденных человеческих представлений о физическом устройстве мира.