Искусственный интеллект против профи: как AlphaStar покорил StarCraft II 0:00
Янник Килхер разбирает прорывную работу DeepMind, опубликованную в журнале Nature. Статья описывает создание системы AlphaStar — агента с обучением с подкреплением (reinforcement learning), достигшего уровня Grandmaster в StarCraft II. Хотя Килхер критикует выбор Nature как площадки из-за отсутствия свободного доступа к публикации, техническая ценность работы остается выдающейся. Главный вклад исследователей заключается в использовании метода «лигового обучения» (League Training) для преодоления классических проблем нестабильности в многоагентных системах.
🕹 Что такое AlphaStar и StarCraft II 1:44
StarCraft II — это сложная стратегия в реальном времени, требующая от игрока высокого уровня планирования и скорости реакции. Игра уникальна балансом трех рас:
- Terran: люди, использующие технологии вроде морпехов и танков.
- Protoss: высокоразвитая инопланетная раса, использующая энергетические щиты и телепортацию.
- Zerg: органическая раса, распространяющаяся как болезнь.
По словам Килхера, обучение ИИ для такой игры — крайне сложная задача из-за огромного пространства действий: агенту необходимо анализировать экран, управлять экономикой (производством зданий и юнитов) и координировать армию с помощью клавиатуры и мыши.
🧠 Архитектура: от имитации к стратегии 9:44
AlphaStar не является прямым продолжением AlphaGo, это модель обучения с подкреплением без использования моделей мира (model-free). Процесс обучения включает несколько уровней:
- Супервайзинг (Supervised Learning): на первом этапе агент учится имитировать действия профессиональных игроков, используя реальные данные. Это позволяет модели достичь уровня мастерства, превосходящего 85% обычных игроков.
- Энкодеры: данные с карты и список сущностей (юнитов) обрабатываются через отдельные нейронные сети: ResNet для визуальной информации и трансформеры для обработки набора сущностей.
- Глубинная LSTM: центральный элемент, отвечающий за запоминание контекста и планирование стратегии во времени, что критично при неполной наблюдаемости игры.
- Политика и выбор действий: после принятия решения о типе действия модель использует «сеть-указатель» (pointer network) для выбора конкретных юнитов, а затем определяет координаты цели с помощью деконволюционной ResNet,.
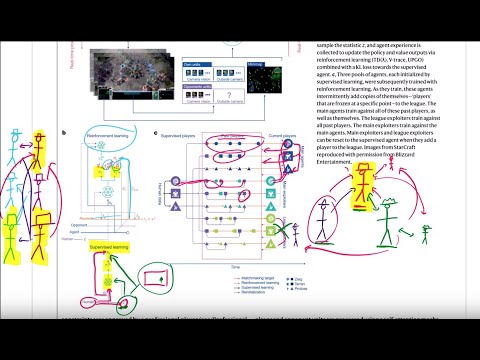
🏆 Лиговое обучение: главный секрет успеха 21:53
Традиционное самообучение (self-play) часто приводит к цикличным стратегиям «камень-ножницы-бумага». Исследователи DeepMind внедрили систему лиг, чтобы сделать агентов устойчивыми ко всем типам стратегий:
- Основные агенты (Main Agents): постоянно соревнуются друг с другом и с прошлыми версиями себя.
- Основные эксплуататоры (Main Exploiters): обучаются исключительно поиску слабых мест текущих «основных агентов».
- Лиговые эксплуататоры (League Exploiters): анализируют слабые стороны всей лиги в целом, заставляя «основных агентов» учиться контрить любые типы тактик.
Благодаря такой структуре, «основные агенты» развиваются, учась противодействовать практически любому сценарию, что в конечном итоге позволило им достичь уровня Grandmaster.
🧐 Критика и нюансы 35:25
Несмотря на впечатляющий результат, Янник Килхер отмечает несколько спорных моментов:
- Неравные условия: по мнению автора, преимущество AlphaStar заключается в способности «видеть» всех своих юнитов одновременно, даже вне зоны камеры, что недоступно человеку в том же объеме.
- Ограничение данных: DeepMind не предоставила исходный код модели, ограничившись лишь псевдокодом, что, по мнению Килхера, ограничивает возможность независимой проверки результатов.
- Человеческий фактор: даже при введении искусственных задержек и ограничений на количество действий в секунду, поведение машины остается «машинным» и не полностью имитирует физиологические ограничения профессионального игрока.




